#InterSystems Business Solutions and Architectures
0
This topic unites publications, which describe business ideas and approaches, success stories, architectures, and demos of solutions you can create, build, and implement with InterSystems products: InterSystems IRIS, InterSystems IRIS for Health, HealthShare, Caché, and Ensemble.
Hi, this post was initially written for Caché. In June 2023, I finally updated it for IRIS. If you are revisiting the post since then, the only real change is substituting Caché for IRIS! I also updated the links for IRIS documentation and fixed a few typos and grammatical errors. Enjoy :)
Your application is deployed and everything is running fine. Great, hi-five! Then out of the blue the phone starts to ring off the hook – it’s users complaining that the application is sometimes ‘slow’. But what does that mean? Sometimes? What tools do you have and what statistics should you be looking at to find and resolve this slowness? Is your system infrastructure up to the task of the user load? What infrastructure design questions should you have asked before you went into production? How can you capacity plan for new hardware with confidence and without over-spec'ing? How can you stop the phone ringing? How could you have stopped it ringing in the first place?
The use of the InterSystems Virtual IP (VIP) address built-in to Caché database mirroring has certain limitations. In particular, it can only be used when mirror members reside the same network subnet. When multiple data centers are used, network subnets are not often “stretched” beyond the physical data center due to added network complexity (more detailed discussion here). For similar reasons, Virtual IP is often not usable when the database is hosted in the cloud.
Network traffic management appliances such as load balancers (physical or virtual) can be used to achieve the same level of transparency, presenting a single address to the client applications or devices. The network traffic manager automatically redirects clients to the current mirror primary’s real IP address. The automation is intended to meet the needs of both HA failover and DR promotion following a disaster.
The following steps show you how to display a sample list of metrics available from the /api/monitor service.
In the last post, I gave an overview of the service that exposes IRIS metrics in Prometheus format. The post shows how to set up and run IRIS preview release 2019.4 in a container and then list the metrics.
This post assumes you have Docker installed. If not, go and do that now for your platform :)
In the last post we scheduled 24-hour collections of performance metrics using pButtons. In this post we are going to be looking at a few of the key metrics that are being collected and how they relate to the underlying system hardware. We will also start to explore the relationship between Caché (or any of the InterSystems Data Platforms) metrics and system metrics. And how you can use these metrics to understand the daily beat rate of your systems and diagnose performance problems.
This week I am going to look at CPU, one of the primary hardware food groups :) A customer asked me to advise on the following scenario; Their production servers are approaching end of life and its time for a hardware refresh. They are also thinking of consolidating servers by virtualising and want to right-size capacity either bare-metal or virtualized. Today we will look at CPU, in later posts I will explain the approach for right-sizing other key food groups - memory and IO.
While this article is about InterSystems IRIS, it also applies to Caché, Ensemble, and HealthShare distributions.
Introduction
Memory is managed in pages. The default page size is 4KB on Linux systems. Red Hat Enterprise Linux 6, SUSE Linux Enterprise Server 11, and Oracle Linux 6 introduced a method to provide an increased page size in 2MB or 1GB sizes depending on system configuration know as HugePages.
At first HugePages required to be assigned at boot time, and if not managed or calculated appropriately could result in wasted resources. As a result various Linux distributions introduced Transparent HugePages with the 2.6.38 kernel as enabled by default. This was meant as a means to automate creating, managing, and using HugePages. Prior kernel versions may have this feature as well however may not be marked as [always] and potentially set to [madvise].
Transparent Huge Pages (THP) is a Linux memory management system that reduces the overhead of Translation Lookaside Buffer (TLB) lookups on machines with large amounts of memory by using larger memory pages. However in current Linux releases THP can only map individual process heap and stack space.
Hyper-Converged Infrastructure (HCI) solutions have been gaining traction for the last few years with the number of deployments now increasing rapidly. IT decision makers are considering HCI when scoping new deployments or hardware refreshes especially for applications already virtualised on VMware. Reasons for choosing HCI include; dealing with a single vendor, validated interoperability between all hardware and software components, high performance especially IO, simple scalability by addition of hosts, simplified deployment and simplified management.
Database systems have very specific backup requirements that in enterprise deployments require forethought and planning. For database systems, the operational goal of a backup solution is to create a copy of the data in a state that is equivalent to when application is shut down gracefully. Application consistent backups meet these requirements and Caché provides a set of APIs that facilitate the integration with external solutions to achieve this level of backup consistency.
Myself and the other Technology Architects often have to explain to customers and vendors Caché IO requirements and the way that Caché applications will use storage systems. The following tables are useful when explaining typical Caché IO profile and requirements for a transactional database application with customers and vendors. The original tables were created by Mark Bolinsky.
In future posts I will be discussing more about storage IO so am also posting these tables now as a reference for those articles.
One of the great availability and scaling features of Caché is Enterprise Cache Protocol (ECP). With consideration during application development distributed processing using ECP allows a scale out architecture for Caché applications. Application processing can scale to very high rates from a single application server to the processing power of up to 255 application servers with no application changes.
InterSystems and Intel recently conducted a series of benchmarks combining InterSystems IRIS with 2nd Generation Intel® Xeon® Scalable Processors, also known as “Cascade Lake”, and Intel® Optane™ DC Persistent Memory (DCPMM). The goals of these benchmarks are to demonstrate the performance and scalability capabilities of InterSystems IRIS with Intel’s latest server technologies in various workload settings and server configurations. Along with various benchmark results, three different use-cases of Intel DCPMM with InterSystems IRIS are provided in this report.
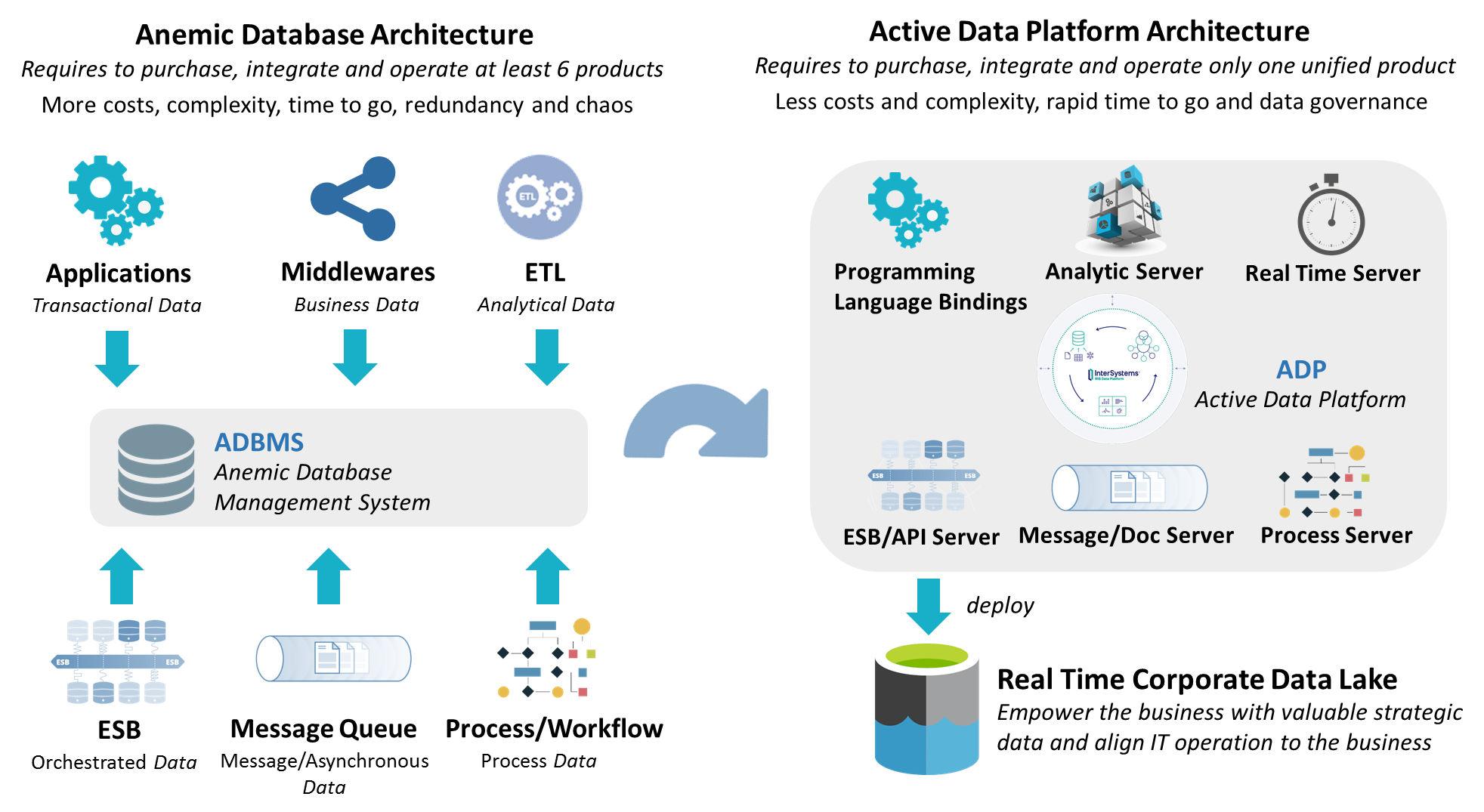
If you need write your organization Data Architecture and map to the InterSystems IRIS, consider following Data Architecture Diagram and references to the intersystems iris documentation, see:
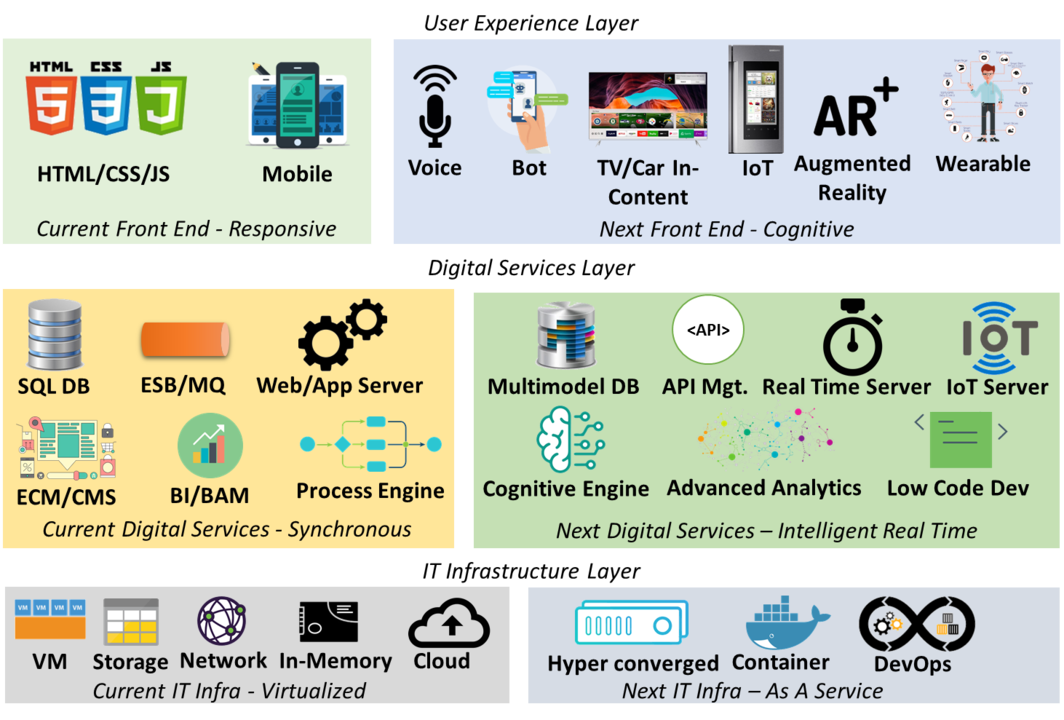
In the next ten years the applications will radically change, see my vision about it:
Today, the web apps are developed using modern HTML 5/CSS/Javascript frameworks like React, Angular, Bootstrap, etc. These web apps are focused on responsive views from the laptop to tablets and mobile screens.
This article provides a reference architecture as a sample for providing robust performing and highly available applications based on InterSystems Technologies that are applicable to Caché, Ensemble, HealthShare, TrakCare, and associated embedded technologies such as DeepSee, iKnow, Zen and Zen Mojo.
Azure has two different deployment models for creating and working with resources: Azure Classic and Azure Resource Manager. The information detailed in this article is based on the Azure Resource Manager model (ARM).
InterSystems has been at the forefront of database technology since its inception, pioneering innovations that consistently outperform competitors like Oracle, IBM, and Microsoft.
This post provides useful links and an overview of best practice configuration for low latency storage IO by creating LVM Physical Extent (PE) stripes for database disks on InterSystems Data Platforms; InterSystems IRIS, Caché, and Ensemble.
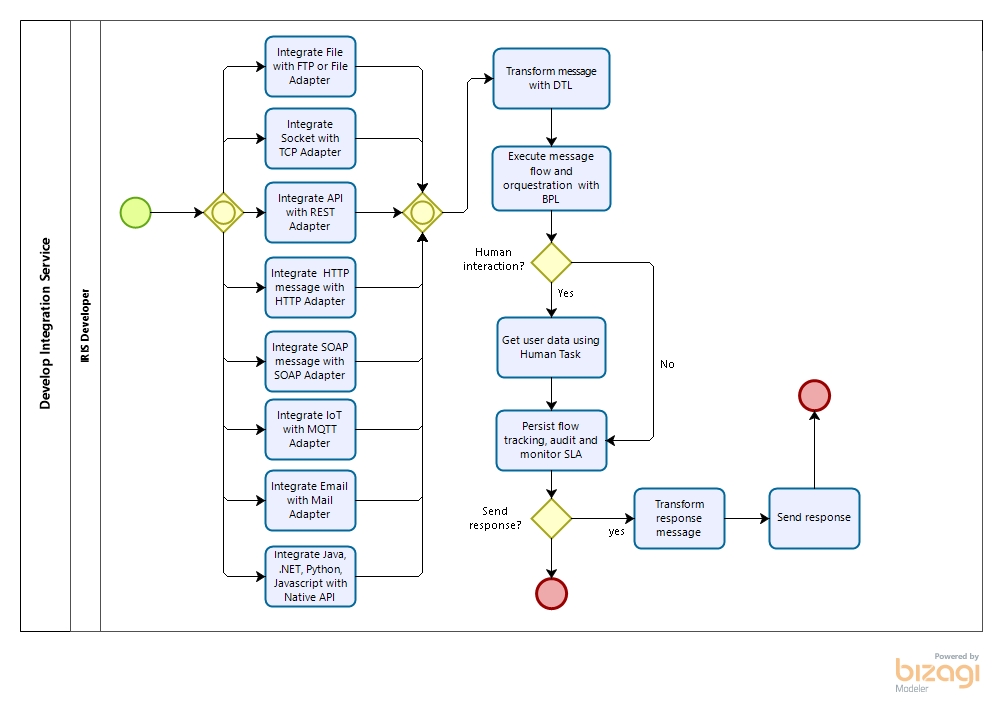
The InterSystems IRIS has an integration engine with these core elements:
1. Adapters: are inbound (data/message input/request) and outbound (data/message output/response) integration logic specialized in the type of data or message protocol (file, http, etc.). They are the interface to allows connect with source or target data repositories or systems.
2. DTL: is a component to mapping and transform data between two components in the flow orchestration.
There are many storage technologies available today from various vendors. The storage technology and configuration best for your application depends on the application access patterns and workloads.
The attached document discusses the various design considerations and recommendations for various technologies. This guide is to help you during discussions with your storage vendor to determine the appropriate storage technologies and products that will work best to meet the performance goals for your applications.
The Amazon Web Services (AWS) Cloud provides a broad set of infrastructure services, such as compute resources, storage options, and networking that are delivered as a utility: on-demand, available in seconds, with pay-as-you-go pricing. New services can be provisioned quickly, without upfront capital expense. This allows enterprises, start-ups, small and medium-sized businesses, and customers in the public sector to access the building blocks they need to respond quickly to changing business requirements.
The release of IBM POWER 8 processors with AIX 7.1 introduced up to 8 SMT threads per processor core (logical or physical). Which SMT level (1, 2, 4, or 8) to use can be confusing and varies based on multiple factors. This article is meant to help with a starting point for your specific application.
Firstly, if running on a version of 2014.x or older, it is advised to use SMT 4 or lower. SMT 8 with those older versions of Cache' has shown a decline in performance and scaling in benchmarking applications.
InterSystems has recently completed a performance and scalability benchmark of IRIS for Health 2020.1, focusing on HL7 version 2 interoperability. This article describes the observed throughput for various workloads, and also provides general configuration and sizing guidelines for systems where IRIS for Health is used as an interoperability engine for HL7v2 messaging.
This is the first article from a series. I will provide details, using bpmn notation, how can I do to develop, deploy, secure, operate a consume IRIS digital services, linking with IRIS documentation. Each subprocess will be described with an individual bpmn diagram. This is the macroprocess.
This post will guide you through the process of sizing shared memory requirements for database applications running on InterSystems data platforms. It will cover key aspects such as global and routine buffers, gmheap, and locksize, providing you with a comprehensive understanding. Additionally, it will offer performance tips for configuring servers and virtualizing IRIS applications. Please note that when I refer to IRIS, I include all the data platforms (Ensemble, HealthShare, iKnow, Caché, and IRIS).
 By replies
By replies
.png)
.png)
.png)