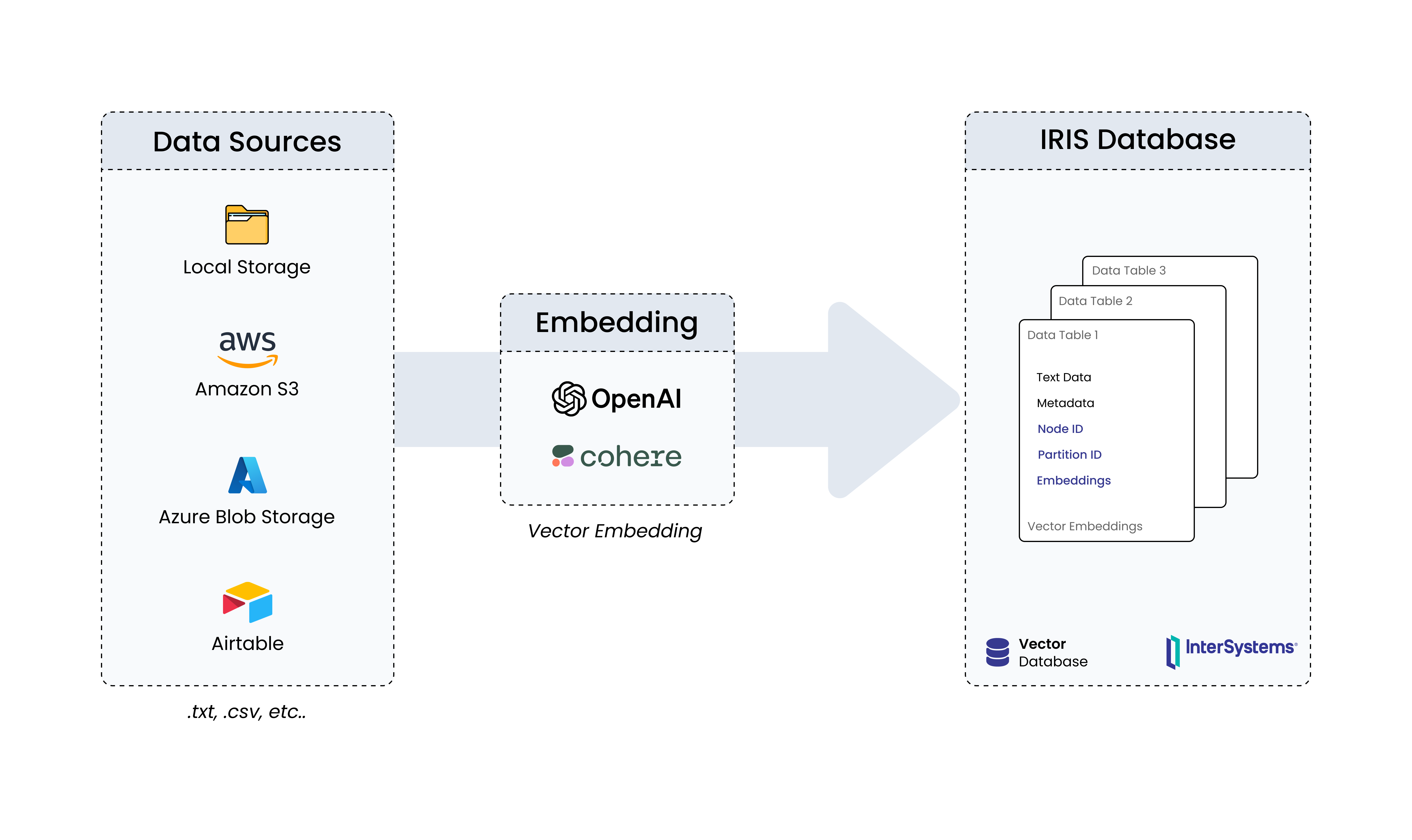
DNA Similarity and Classification was developed as a REST API utilizing InterSystems Vector Search technology to investigate genetic similarities and efficiently classify DNA sequences. This is an application that utilizes artificial intelligence techniques, such as machine learning, enhanced by vector search capabilities, to classify genetic families and identify known similar DNAs from an unknown input DNA.
.png)
K-mer Analysis: Fundamentals in DNA Sequence Analysis
Fragmentation of a DNA sequence into k-mers is a fundamental technique in genetic data processing.

.png)
.png)
.jpg)

.png)


.png)