By replies
By replies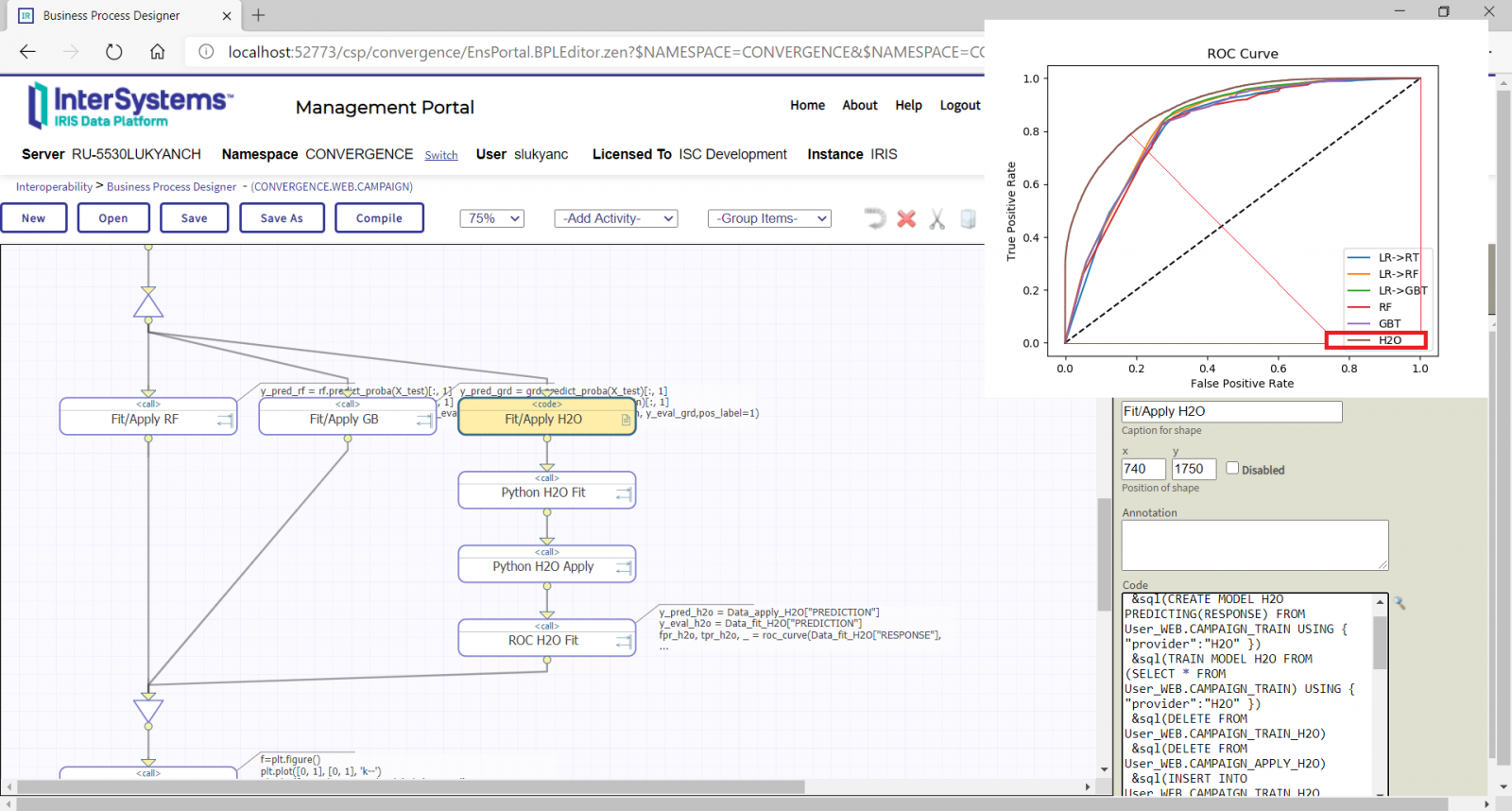
Hi Community,
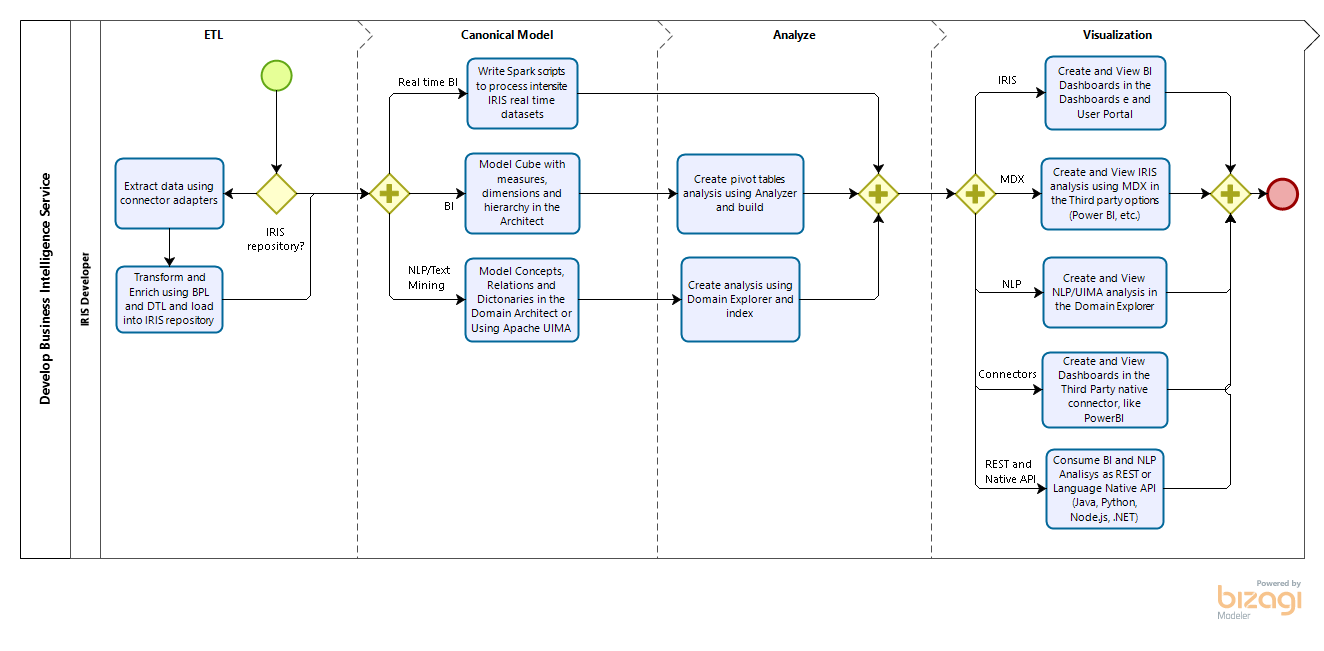
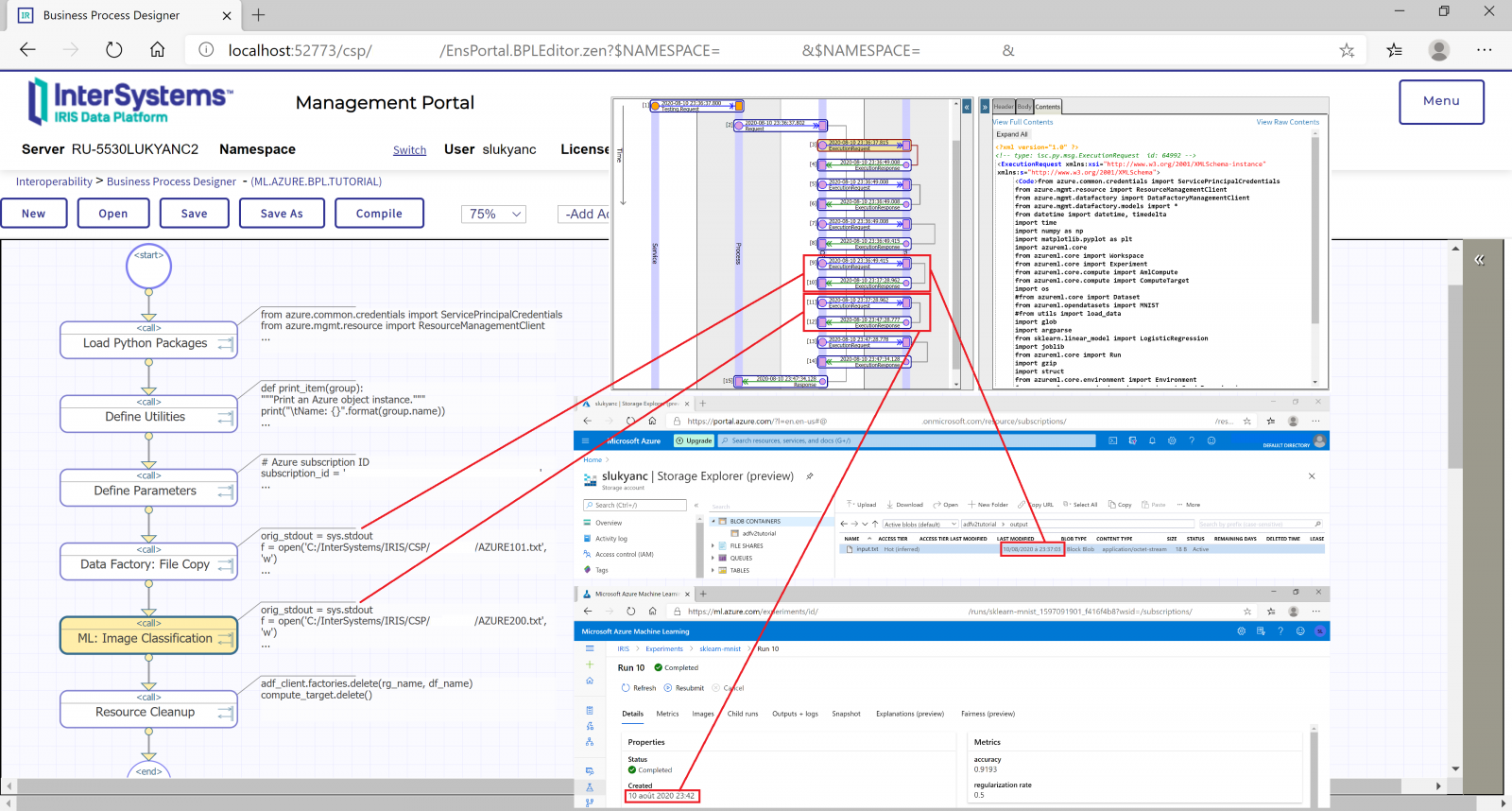
Enjoy watching the new session recording from the InterSystems AI+ML Summit 2021:
⏯ AI+ML Summit Convergent Analytics – Healthcare Stream
https://www.youtube.com/embed/yDRZwK3maeQ
[This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
 Open Exchange app
Open Exchange app