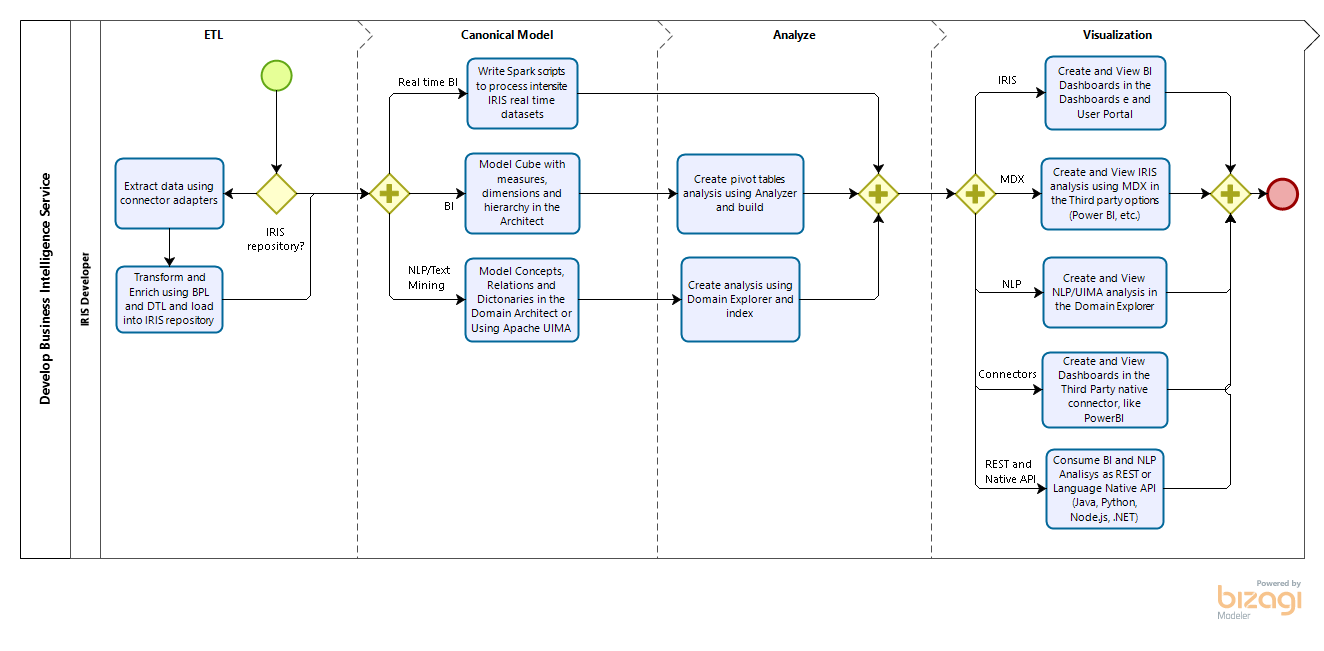
By replies
By repliesAuthor: Sergey Lukyanchikov, InterSystems
For one major reason: to avoid progressive technical and economic performance deterioration in an AIaaS setup characterized by increasing volume, velocity and variety of data flows (the famous Big Data’s “3 Vs”).
 Open Exchange app
Open Exchange app