Why AI-as-a-Service Requires an Integrated-from-Core Data Platform
Author: Sergey Lukyanchikov, InterSystems
For one major reason: to avoid progressive technical and economic performance deterioration in an AIaaS setup characterized by increasing volume, velocity and variety of data flows (the famous Big Data’s “3 Vs”).
Let us take a closer look at the variety factor: if the variety of our data increases (e.g., data comes from an ever-increasing range of ever-evolving data-generating processes), this inevitably builds up demand for more and more functionality. For example, yesterday, a mature DBMS was enough for us to cover all functional requirements, we were getting along by just creating new data tables/views and writing/adapting SQL procedures; today, we are forced to extend our DBMS with functionality like ETL, BI, AI, MDM, we name it; tomorrow… and we should not forget the two remaining Vs.
Data platform vendors respond to the above variety challenge by making one of the three distinct choices:
- Focusing on a functional niche: a pragmatic choice, but also an exit from the variety race
- Chasing functionality: a choice that prioritizes development/acquisition of required functionality and its fast inclusion in a data platform product
- Improving generalization capacity: a choice that prioritizes continuous improvement of the native core of a data platform with a dual objective of providing maximum efficiency for integration of required functionality in a data platform while avoiding non-sustainable functionality ramification and fragmentation due to development/acquisition
The most attractive choice nowadays seems to be “chasing functionality”, these are just some of the most well-known examples:
 Figure 1 Microsoft Azure portal with AI/ML functionality
Figure 1 Microsoft Azure portal with AI/ML functionality
 Figure 2 Amazon AWS portal with AI/ML functionality
Figure 2 Amazon AWS portal with AI/ML functionality
The strength of that choice is, obviously, its quick fixing of any gaps that a growing data variety may cause to the already existing functional portfolio of a data platform. It is enough to briefly study the menu structure of the AI/ML portions of the above data platforms to sense the “invisible hand of the market”: the functions are conveniently bundled into almost self-contained topics, getting a user up to speed with this or that problem-centric application.
The weakness (massively overlooked by the users) is that the applications developed based on such a data platform will (a) be inheriting all the inevitable integration and performance flaws cumulating over years and across the layers of opportunistically defined and implemented functional portfolio, and (b) be exposed to a very serious risk of having to re-write the code and/or re-educate the development teams following market-provoked changes in the data platform functionality bundling.
If n is the number of functions of a “chasing” vendor’s data platform used as a basis for developing your applications, the cost of cognitive integration (the most relevant cost aggregate nowadays) is “locally equivalent” to n(n-1)/2 (the number of links to implement and maintain among the n functions).
A viable alternative to “chasing functionality” could be “improving generalization capacity” choice. This choice is just starting to be discovered by the market, although some vendors have been practicing it for decades, for example:
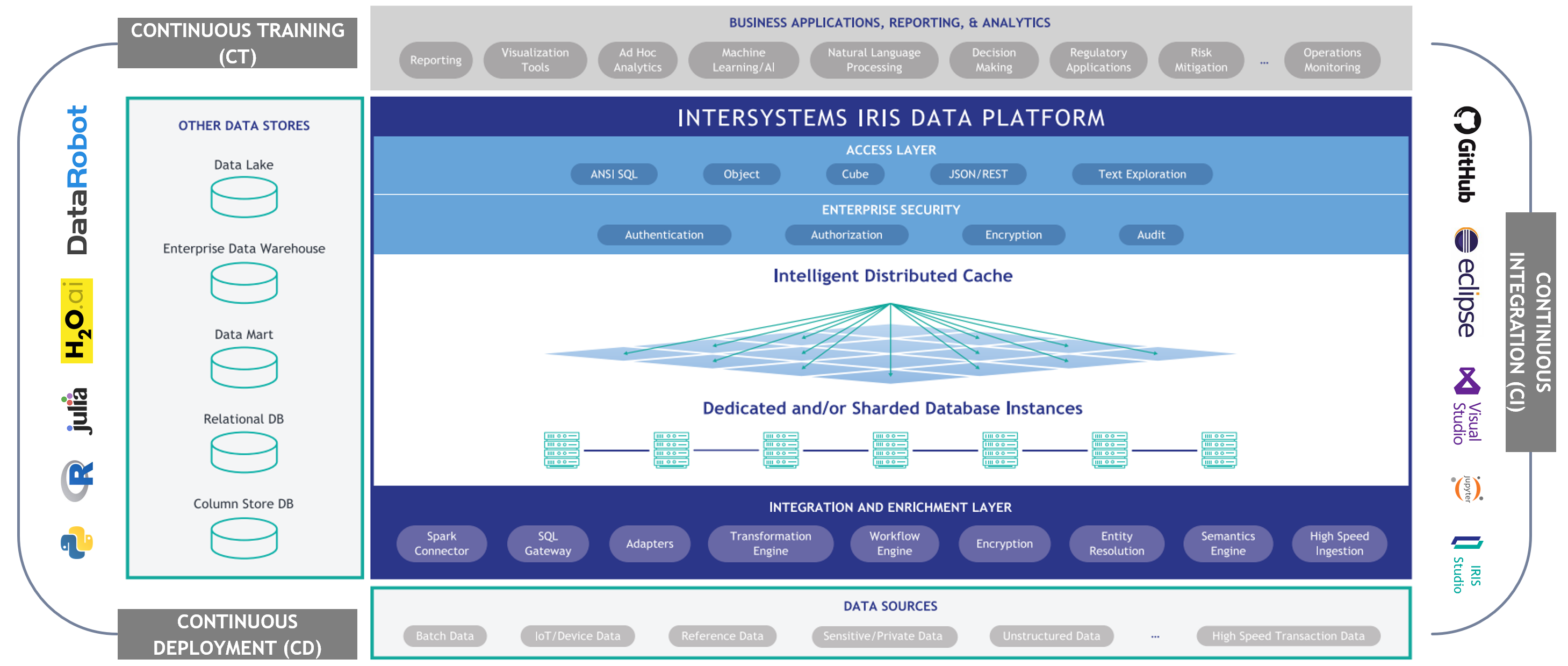
Figure 3 InterSystems IRIS: functional architecture
Do you see the major functional distinction of this data platform compared to the previous two? You are right: there is a clearly defined functional core.
At the “core of that core”, as we can see from the diagram above, there is an extremely performant database management system designed from its early days as a data-model-agnostic engine with intelligent distributed computation capacity. The database management layer is natively supplemented by the integration layer allowing the data engine to communicate in real time with an unlimited spectrum of source and target systems and to structure/automate that communication by means of workflows, rules, transformations, etc. The analytics layer tops (or wraps, depending on the view angle) the core’s architecture by providing tools (applications and APIs) for data analysis and visualization.
The crucial fact about the core of InterSystems IRIS data platform is that it was developed in parallel and in tight sync with its native programing language, resulting in a consistent and editable programmatic representation (object classes) of that platform’s objects.
And that brings us to the final turn in this analysis: would we rely on a data platform with a rich but pre-packaged functionality that permanently grows in assortment and whose “packaging logic” may change from release to release – or would we prefer efficient integration of the needed functionality into a performant functional core of an alternative data platform, knowing that the functional core is stable and evolves thoughtfully as one, as well as that any evolution in the functionality we interoperate with would at most require changing messages’ structure/mapping?
Returning to some basic math: if you rely on just 5 functions from your current “chasing” platform, your cognitive integration cost reduction due to replacing it with InterSystems IRIS would be a factor of 10 (i.e., the current cost will be divided by 10). The cost of cognitive integration associated with your current function-to-function “code topology” disappears: this integration is delivered by the “generalizing” data platform.
Let us be transparent on that Azure ML’s Python SDK and AWS ML’s Sagemaker/Boto3 are solid all-purpose integration mechanisms allowing to operate Python as part of those data platforms (or rather, operate those platforms using Python). But they are still explicit add-on function packages, self-contained increments to those platforms’ “patchwork” portfolios.
In the case of InterSystems IRIS, integration with Python (as well as with R and Julia) is done at its native core: e.g., a Python application written to work stand-alone is simply pasted into IRIS (to become either a visual workflow step, or an object class, or a stored procedure), and it is ready to do useful work for the AI solution we are designing. That useful work (95% of the times) would require just a standard Python/R/Julia instance – installed locally or “borrowed” from a remote IRIS instance using IRIS-to-IRIS or Python-to-Python interoperability – but can also be accomplished by calling external providers (billable, not to be forgotten):
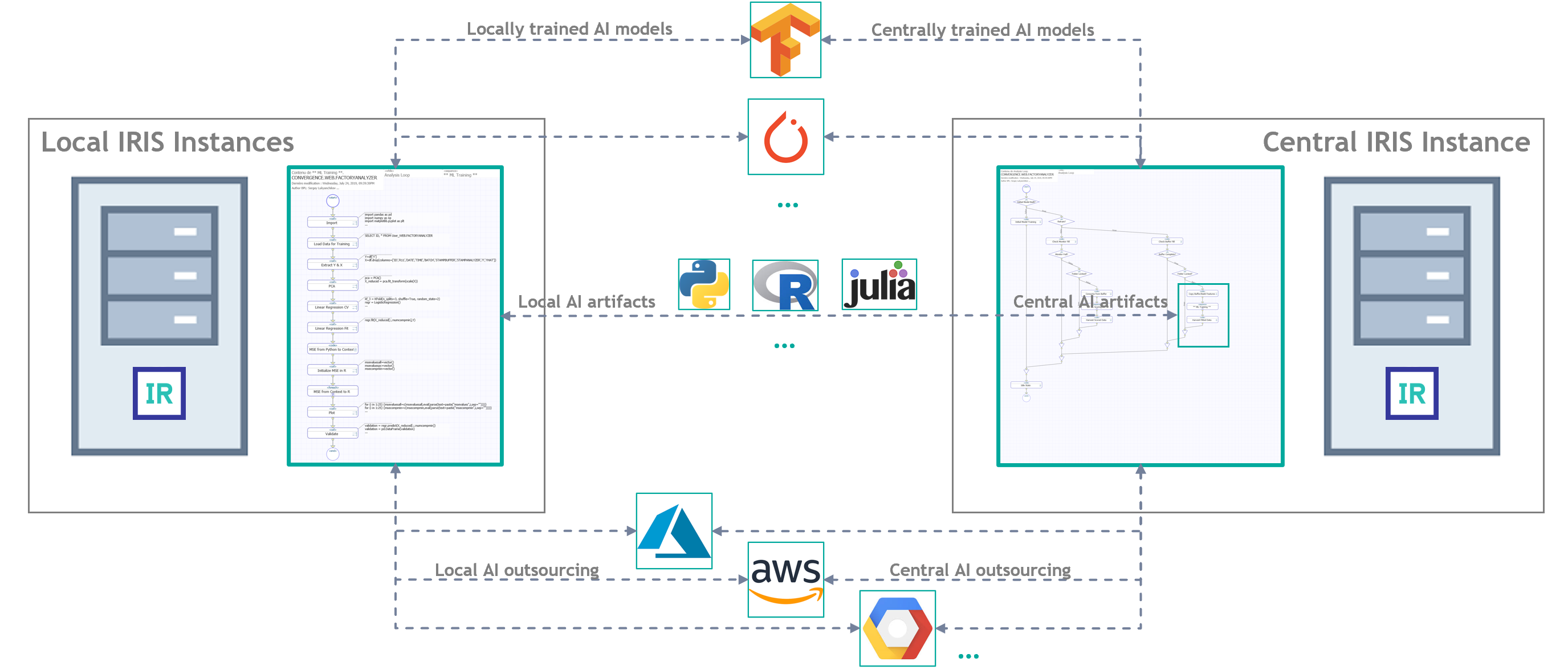 Figure 4 InterSystems IRIS: distributed AIaaS deployment approaches
Figure 4 InterSystems IRIS: distributed AIaaS deployment approaches
InterSystems IRIS does not oppose on-premise deployment to native cloud data platforms: for IRIS there is simply no difference between on-premise and in-cloud deployment. InterSystems IRIS is a pure-form data platform, it operates on all types of infrastructure, without imposing its “infrastructure origins” on neither its functional portfolio, nor on the user. The term “local” relative to IRIS rather means “same infrastructure with IRIS”, whether it is a cloud or a local network.
The users of AIaaS solutions deployed on InterSystems IRIS can take their solution portfolio from one infrastructure to another one, distribute it across several infrastructures, and, on top of that, be guaranteed against any unexpected turns in the functionality:
 Figure 5 InterSystems IRIS AIaaS implementation philosophy
Figure 5 InterSystems IRIS AIaaS implementation philosophy
This concludes our analysis as the result of which we could learn about the major architectural choices that data platform vendors make, and about the AIaaS advantages of integrated-from-core functional architectures, whereof InterSystems IRIS is a distinct example. We hope this analysis will be useful for the user while making their vendor choice given their mix of strategic and tactical requirements.
Should AIaaS be an important topic for you or your organization, do not hesitate to reach out to me via LinkedIn to discuss.