Eduard, great project!
Please, convert the source code into UDL! ;)
- Log in to post comments
Eduard, great project!
Please, convert the source code into UDL! ;)
Hi, Pilar!
Thanks for the article! What is DNI?
True! Nice hack ;) Thank you, Vitaly!
But obviously, you cannot use this calls in a code, because dc.test.1 can be dc.test.2 etc...
Thanks, Dan!
That's helpful.
And from that class descriptor/dispatch table, can we say in general that call:
do foo^utils(p1)
would be always faster than
do ##class(My.Utils).foo(p1)
assuming that the code in foo() is same?
Oh, thanks, Dan! That's interesting.
So, practically speaking:
Class My.Utils {
ClassMethod Foo {
///
}
}Works faster than:
Class My.Utils Extends %RegisteredObject {
ClassMethod Foo {
///
}
}Right?
Thanks, Vitaly! That's interesting!
Thank you, Robert!
So, if I want to put $H to a %Date property I do:
set s.Date=$H
do s.%Save()for %TimeStamp property to set current date/time, I do what?
Eduard, do you think it makes sense to DELETE everything in a namespace and then import code from checkout?
Consider DeveloperA deleted ClassB from repo and from his local NamespaceA
DeveloperB checkout repo and with only classA but still has ClassB in his local NamespaceB. What will delete ClassB in DeveloperB's working system?
The only "automatic" solution I see here is to check out and import classes into clear or new Namespace.
Or never delete classes, only "deprecate" it
Hi, Alessandro!
Thanks again for such valuable content on BI Architecture with DeepSee. Analytics server configuration gets more and more sophisticated with a lot of manual operations.
Do you plan to introduce a script which will convert a "usual" server to a "ready for DeepSee Analytics" server in a one-run? That would be fantastic!
Hi, Alessandro!
Thank you for the useful article!
Having Primary and Analytics servers is very important, the main reason being to avoid performance problems on either server. Please check the documentation about Recommended Architecture.
What is the type of mirroring is recommended? Should it be synchronous mirror or async, or disaster recovery?
Wow. That's interesting. I'm curious what will happen if a class was created in Caché and then modified in IRIS (e.g. with new property) - would it be another global for a new property? Could you check that?
I think if you created class first in Caché 2017.2 and preserve the storage definition within a class in version control you should be good with IRIS - I mean IRIS shouldn't change the storage of your 2017.2 class.
Hi, Peter!
I would warn you of NOT including storage information in Git (or any other CVS). It is the must to keep class storage definition within source control.
Consider you have a system in production where you have class A with properties P1 and P2 with data.
And you developed a new version of a product with the optimization when you don't need P1 anymore and delete it. And you added a new feature which needs to add property P3
You deploy new class A with P2 and P3 properties on a production system. Storage would be generated upon class definition and you will get the following:
All reads from P2 would deal with former P1 data.
All reads from P3 would read former P2 data (yes, you will get P3 initialized by former unexpected P2 data).
So you'll get some unexpected behavior and bugs with this.
Solution:
keep the storage definition within a class and in Git.
Maybe delete a property is a bad practice but sometimes we are doing that.
HTH
I'll answer the comment related to import/export utility isc-dev . It exports everything in a namespace to a specified folder.
You can setup the folder with:
d ##class(sc.code).workdir("D:\yourfilder")Then export with
d ##class(sc.code).export()
You can specify a mask of classes too or set it up in isc.json file.
Hi, Jaqueline!
You also can consider using isc-dev import/export tool.
Install it in USER and map into %ALL (to make it runnable from any namespace), set up the tool like this:
d ##class(sc.code).workdir("/your/project/src")Enter your project namespace and call:
d ##class(sc.code).export()
And the tool will export (along with classes) all the DeepSee components you have in Namespace including pivots, dashboards, term lists, pivot variables and calculation members in folders like:
cls\package\class
dfi\folder\pivot
gbl\DeepSee\TermList.GBL.xml
gbl\deepsee\Variables.GBL.xml.
So you can use it with your CVS tool and see commit history, diffs, etc.
To import everything from the source folder into new namespace use:
d ##class(sc.code).import()
or standard $SYSTEM.OBJ.ImportDir() method.
HTH
Hi Sergey! Kanban is great! Love it)
But now I do not start any project without issue tracker. If you got a bug report or a feature request, where you will place it?
Hi, Peter, thanks!
The question was that everything which is listed in pivot-settings-dropdown is available to call with %LISTING in MDX, except with "custom listing".
Which can be called with
DRILLTHROUGH .... RETURN fields
MDX instruction, as you wrote. Thanks!
Thank you, Alessandro! That's clear now. I guess Custom Listing is being executed with DRILLTHROUGH + field names by comma: there is an option in Drillthrough documentation.
Have no idea, Alessandro.
Just figured out, that there are some extra listings (in addition to those we have in the cube) available for pivots in Analyzer. %Listing only works (for me) with those which are declared in the cube.
You can see (and alter custom listing) if you open Detail Listings section in Analyzer (version 2017.2).
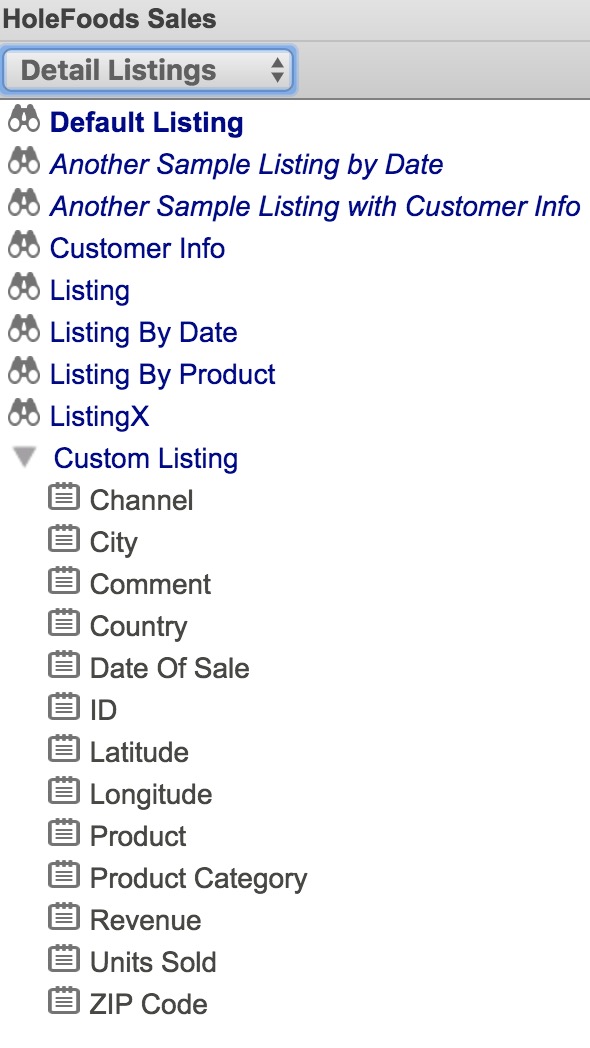
Hi, Robert!
Thanks for the answer!
Yes, %LISTING this works perfectly with listings declared in the cube definition.
But if you open Analyzer you can see extra "Custom" listings, which are available in the pivot, but not available via %LISTING.

Thank you, Artem!
It's a great feature which helps you call any binaries diectly from Objectscript without coding a proxy dll.
It was also used for Caché Localization manager.
2) It's OK approach for relatively small external source tables because in this case, you need to build the cube for all the records and have no option to update/sync.
If you OK with timings on cube building you are very welcome to use the approach.
If the building time is sensible for the application consider use the approach what @Eduard Lebedyuk already has advised you: import only new records from the external database (hash method, sophisticated query or some other bright idea) and do the cube syncing which will perform faster than cube rebuilding.
Hi, Chintan!
Have you seen this article? Maybe it's relevant.
Hi, John! Would you please share what is the course?
Thanks, Eduard!
Also this is a relevant article too by @Vicky Li
Hi, Max!
I think you have two questions here.
1. how to import data into Caché class from another DBMS.
2. How to update the cube which uses an imported table as a fact table.
About the second question: I believe you can introduce a field in the imported table with a hash-code for the fields of the record and import only new rows so DeepSee Cube update will work automatically in this case. Inviting @Eduard Lebedyuk to describe the technics in details.
Regarding the 1st question - I didn't get your problem, but you can test linked table via SQL Gateway UI in Control Panel.
Hi Peter!
Sure, that's why I raised the topic - to gather the best practices of "what works" in production, preferably "for years".
Thanks for sharing your experience.
BTW, do you want to share your Source Control library on DC someday?