New
Is there a way to delete a message in a routing rule? For example, an HL7 message doesn't qualify for a rule, but instead of the message being passed on to the next rule, you delete the message.
.png)
InterSystems IRIS for Health™ is the world’s first and only data platform engineered specifically for the rapid development of healthcare applications to manage the world’s most critical data. It includes powerful out-of-the-box features: transaction processing and analytics, an extensible healthcare data model, FHIR-based solution development, support for healthcare interoperability standards, and more. All enabling developers to realize value and build breakthrough applications, fast. Learn more.
Is there a way to delete a message in a routing rule? For example, an HL7 message doesn't qualify for a rule, but instead of the message being passed on to the next rule, you delete the message.
I am trying to built a Task that kicks off a Workflow to pull data into HSPD, and when I try to test the Task
I keep getting TestTask+3^OSU.Workday.TerminationsTask.1 *%Exception.StatusException ERROR <Ens>ErrConfigDisabled: Configuration item 'OSU.DataSource.Workday.TermService' is disabled
But within the Namespace the OSU.DataSource.Workday.TermService shows enabled.
Here is my Task that I am using...
Class OSU.Workday.TerminationsTask Extends %SYS.This time, it’s not really programming per se, but we are using React as a front-end development tool for IRIS. When using a web development framework—not limited to React—one key consideration is which CSS framework to use. Up until now, we’ve been using Bootstrap, which is the standard and the easiest to get started with.
However, while it’s easy to use, I felt that it offers limited flexibility for customization. That said, even if we were to switch to another CSS framework, learning it and rewriting everything from scratch would be a significant effort, so we left things as they were.
Is your source control treating your InterSystems IRIS environment like a simple collection of files? Most source control tools lack the native intelligence to handle InterSystems IRIS, which is why your code is treated as such.
Deltanji is different. It understands how code and other artifacts are stored within IRIS and can manage them directly. This eliminates the friction that other tools introduce to the process.
Join us for an InterSystems-hosted webinar to see how Deltanji provides an enterprise-grade source control solution that is tightly integrated with your IRIS environment.
I have two RHEL 9.7 servers. One is running intersystems in docker no problem. But, I have now tried two other servers RHEL 9.7 one, podman and one docker and I get the following.
We are working on Disk Consolidation and looking at Class/Globals that are rather large and not being cleaned up by the nightly Purge process. We have implemented DeleteHelper - A Class to Help with Deleting Referenced Persistent Classes | IDC on any Custom Data Classes, and Business Processes (BPL).
We have a bunch of Data Classes, BPL's, and Operations that connect to external MS SQL Server using JDBC to query or write data to using Stored Procedures and Queries. All that Query external tables are using EnsLib.SQL.Snapshot, and this is being written to ^Ens.AppData which is not cleaned up.
A Continuous Training (CT) pipeline formalises a Machine Learning (ML) model developed through data science experimentation, using the data available at a given point in time. It prepares the model for deployment while enabling autonomous updates as new data becomes available, along with robust performance monitoring, logging, and model registry capabilities for auditing purposes.
InterSystems IRIS already provides nearly all the components required to support such a pipeline. However, one key element is missing: a standardised tool for model registry.
Hi Community,
An error occurs during the analysis process in the FHIR SQL Builder. How can I identify the exact cause of the error?
|
Alert ID |
Product & Versions Affected |
Risk Category & Score |
Explicit Requirements |
|
HSIEC-12800 |
InterSystems IRIS® for Health InterSystems Health Connect™ version |
System Stability Concern: 5 (High) |
1. HL7-to-SDA3 transformations are in use 2. Medication-related messages include TQ1 segments 3. TQ1-3 Repeat Pattern contains multiple repetitions |
An issue has been identified in the HL7-to-SDA3 transformation logic that can cause an infinite loop when processing certain medication-related HL7 messages.
Hi All,
First I want give a Shout Out to @Theo Stolker and @Rupert.Young. Because they helped me with the solution.
When you're using the EnsLib.SQL.Snapshot as a Property in the Response Message to return Snapshot data (,e.g.: from Business Operation to Business Process,) the Snapshot data won't be cleaned with the Purge messages task/service.
{
Property SnapshotProp As EnsLib.SQL.Snapshot;
}
The data will be stuck in the global: ^Ens.AppData. You can find it with this query in System>Globals: ^Ens.AppData("EnsLib.SQL.
While starting with Intersystems IRIS or Cache, developers often encounter three core concepts: Dynamic Objects, Globals & Relational Table. Each has its role in building scalable and maintainable solutions. In this article, we'll walk through practical code examples, highlight best practices, and show how these concepts tie together.
1. Working with Dynamic Objects:
Dynamic objects (%DynamicObject and %DynamicArray) allow developers to manipulate JSON-like structures directly in Objectscript. They are especially useful for modern applications that need to parse, transform or generate JSON.
Working in healthcare IT as a young developer, especially on InterSystems TrakCare, you quickly realize one thing: it’s not just about HL7 messages or backend integrations. A hugepart of making TrakCare work smoothly for hospitals comes down to how it’s configured, customized, and supported on the application side.
That’s where people like me come in—techno-functional developers who understand both the tech and how it impacts actual hospital workflows.
Our role sits right in the middle.
FHIR (Fast Healthcare Interoperability Resources) is the modern standard for storing and exchanging clinical data. But once your data is in a FHIR server, how do you actually explore it? FHIR data is stored as JSON — powerful, but not practical to read directly. I wanted a tool where you could click on a patient, see their conditions, medications, lab results, and more — in a clean, readable format. So I built the FHIR Patient Viewer.
The app runs entirely in Docker and connects directly to an InterSystems IRIS for Health FHIR server.
Hi everyone,
I’ve configured an integration scenario in InterSystems IRIS with a Business Service exposed as a SOAP web service. Everything works correctly when the web application allows unauthenticated access.
However, when I switch the web application to require Basic Authentication, I’m unable to get it working properly. I have configured a resource and assigned it to both the web application and the user I’m using for the request, but I consistently get login failures (visible in the audit log).
For example in %Library.File Class Documentation, FiieSet query is listed as:
"Selects Name As %String, Type As %String, Size As %BigInt, DateCreated As %TimeStamp, DateModified As %TimeStamp, ItemName As %Stringof ..."
How to obtain a "real" syntax?
Thank you.
Our Pharmacy team would like us to convert...
¼ test character and ½ test character and ¾ test character andto more like
1/4 test character and 1/2 test character and 3/4 test character andIs this possible?
Currently have an extension of the ..lookup function as a custom version of the lookup. Is there any easy way to get it to display it as a list of the lookup tables
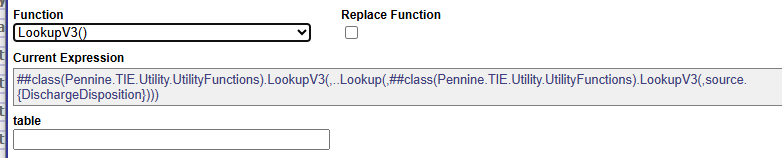
ClassMethod LookupV3(table As %String = "",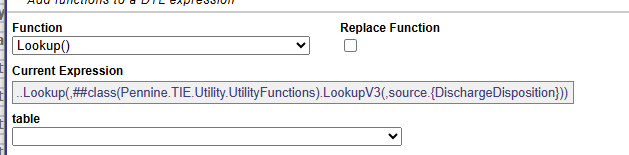
and the one i'm trying with
Working with files often starts off simple. open the file, read, and process. That approach works perfectly well, until the file happens to be an Excel file.
A Common Assumption
At first, an Excel file (.xlsx) looks like just another data file, rows, columns and values. nothing unusual. So it's natural to assume it can be read the same way as a .txt ot .csv file. But that's where things start to break.
Why Excel files behave differently
The key difference is how the data is stored:
-> .txt / .csv - plain text, line-by-line.
-> .
Hi Community,
Preparing for InterSystems Certification exams requires more than reading documentation. It calls for focused practice aligned with real exam objectives.If you are planning to validate your expertise in HL7, SQL, System Administration, or Development, structured preparation can make a significant difference.

The platform offers a large pool of practice questions mapped to certification domains, along with detailed answer explanations that point back to relevant documentation.
Hi Community,
Enjoy the new video on InterSystems Developers YouTube:
⏯ Data on the Move - Securing InterSystems IRIS Connections with TLS @ Ready 2025
RabbitMQ is a message broker that allows producers (those who send a data message) and consumers (those who receive a data message) to establish asynchronous, real-time, and high-performance massive data flows. RabbitMQ supports AMQP (Advanced Message Queuing Protocol), an open standard application layer protocol.
The main reasons to employ RabbitMQ include the following:
My team is trying to decide on the best Git strategy for a group of related but separate projects/environments.
One side prefers one repo per project/environment/namespace for cleaner separation. The other side prefers one repo with multiple project folders so shared code and releases are easier to manage in one place.
The challenge is that these projects are separate enough that boundaries matter but related enough that some utilities and common logic may need to be reused. We also want the setup to be easy for developers to understand and not become a deployment nightmare later.
v2026.1 was just released as GA, and one of the features I'm looking forward to using is the DTL Explainer feature.
This allows you to take a Data Transformation, and with a click of a button get a human-readable description of the transformation (which you can also use as the basis for the DTL Description).
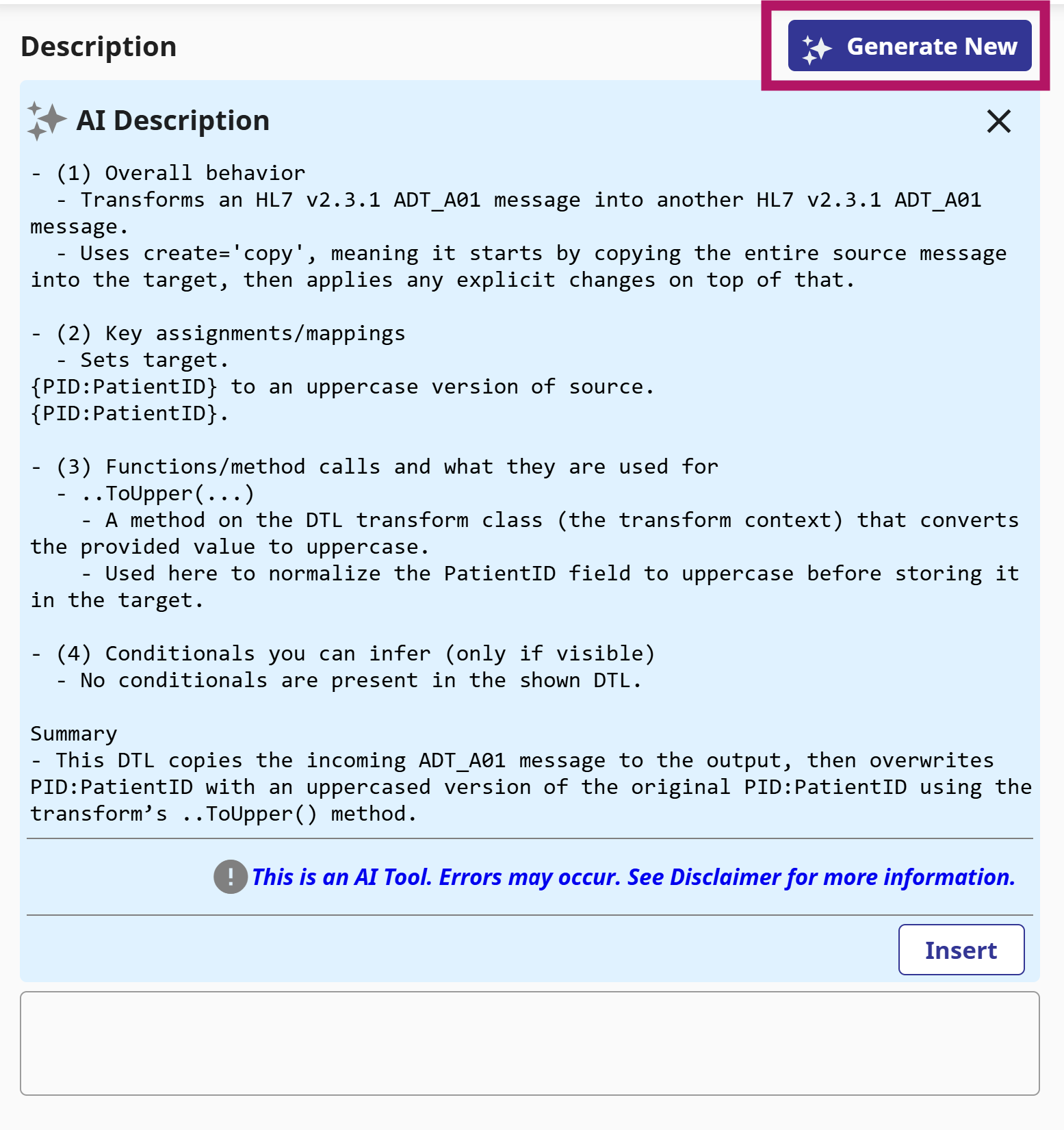
For complex DTLs, especially ones you didn't write yourself, or you did but a long time ago, this will allow you to get a clear quick understanding of what it's doing.
Hi Guys,
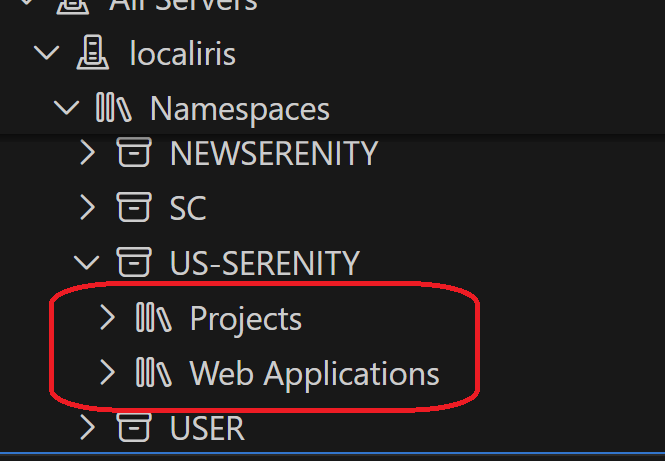
I've connected VS Code to my IRIS server and can see projects & web application option but not Classes tab, how can I add it, and with the old Studio we do have the Inspector tab where we can check properties, Storage, methods, are these available in VS code?
also does any changes or new classes created via VS code automatically reflected in my IRIS namespace ?
Thanks
Since our previous announcement, we have introduced several incremental improvements to the client‑side editing experience in VS Code. These updates focus on preserving developer‑authored formatting when synchronizing with the server.
Client‑side *.cls files previously lost certain formatting details during compilation, including keyword casing (e.g., classmethod → ClassMethod), normalization of blank lines between class members, and removal of line breaks within parameter lists.
The 2023.1.7 maintenance releases of InterSystems IRIS® data platform,InterSystems IRIS® for HealthTM, and HealthShare® Health Connect are now Generally Available (GA).
Please share your feedback through the Ideas Portal using the category Post-Release Feedback so we can build a better product together.
You can find the detailed change lists & upgrade checklists on these pages:
There are many EAPs available now. Check out this page and register to those you are interested.
IrisTest is a light weight, powerful, user-friendly tool designed to simplify unit test report generation. It includes an interactive shell and API to facilitate communication, allowing developers to easily manage and generate reports for their test runs in various formats. Whether you're debugging or creating detailed reports for analysis, IrisTest makes the process smooth and efficient!
The 2026.1 release of InterSystems IRIS® data platform, InterSystems IRIS® for HealthTM, and HealthShare® Health Connect is now Generally Available (GA). This is an Extended Maintenance (EM) release.
The Interoperability user interface project has continued from 2025.1 and has incorporated many of the items that you – our customers and partners – have suggested and observed. We are continuing to invest in feedback and updating this important user experience. In the latest release, 2026.1 for IRIS, IRIS for Health, Health Connect and Health Connect Cloud, the BPL Editor and Message Viewer/Visual Trace applications are now available for opt-in!
NOTE: