As part of a recent documentation technical project to optimize the search, I needed to use Embedded Python in my ObjectScript code. The main blocker was passing a Python list from a Python class method to a ObjectScript method. Sending the list by reference to the python method, populating it with the Insert() method, and returning the reference to the ObjectScript method resulted in an list with type %SYS.Python, a process that was straightforward but not efficient.
I explored an alternative method: converting a Python list to an ObjectScript list using JSON as the intermediary format.
New
This past weekend we ran into something odd. When we failed over our mirror from 2022.1.3 to 2025.1.3 the one of the Business Rules that was on what became the Primary (2025.1.3), had a rule within it that was removed back in January. When the Failover occurred, we had to scramble to backup, disable, and remove the Rule that shouldn't have been there.
Both the Data and Code live within the same IRIS.dat that is the main MIRROR database for that Namespace.
If this happened to one Class file, could it happen to others we do not know about?
READY 2026 is almost here, and we’re really curious to hear what everyone is looking forward to this year 🚀
What are you most excited about? It could be a topic you want to explore, a question you’re hoping to get answered or something you’re simply curious about.
Share your thoughts below! We’d love to hear what’s on your mind and see what others are excited about too 💬
Feel free to read through the replies and like the ones you relate to! 😊
Motivation
Why do we need this?
-
Lack of Compiled Context: AI tools only see source code; they don't know what the final compiled routine looks like.
-
Macro Hallucination: Because AI doesn't see our
#includefiles or system macros, it often makes them up, wasting time during debugging. -
The Documentation Gap: Deep logic optimization often requires understanding internal macros that aren't fully covered in public documentation.
-
Manual Overhead: Currently, the only way to fix this is to manually use the IRIS VS Code extension to find the "truth" in the routine.
New
Hi Community,
In our two preceding articles, we explored the fundamentals of the Interoperability Embedded Python (IoP) framework, including message handling, production setup, and Python-based business components.
In this third piece, we will examine advanced methodologies and practical patterns within the IoP framework that are pivotal for real-world interoperability implementations.
We will explore the following topics:
✅ DTL (Data Transformation Language) in IoP
✅ JSON Schema Support
✅ Effective Debugging Techniques
Collectively, these features help us create maintainable, validated, and easily troubleshootable production-grade interoperability solutions.
Hey Community!
Have you attended one of the Global Summits or a previous READY 2025? We’d love your help to inspire others to join InterSystems READY 2026!

We’re inviting community members to record a short video (less than 1 minute) answering one or more of these questions:
- What did you find most valuable about attending?
- What surprised you?
- Why should others join READY 2026?
- Who would benefit most from attending?
Your authentic perspective helps future attendees understand the real impact of these events, beyond the agenda.
🎥 To record a short video, follow the link. No preparation needed.
Hi Community,
We're excited to invite you to the next Community webinar presented by George James Software, an InterSystems partner:
🗓️ Date & Time: Thursday, April 9th, 4 pm BST | 11 am EDT
The PACELC theorem was created by Daniel Abadi (University of Maryland, College Park) in 2010 as an extension of the CAP theorem (created by Eric Brewer - Consistency, Availability, and Partition Tolerance). Both help design how to architect the most suitable operation of data platforms in distributed environments under the aspects of consistency versus availability. The difference is that PACELC also allows analysis of the best option for non-distributed environments, making it the gold standard for considering all possible scenarios to define your deployment topology and architecture.
The CAP theorem states that in distributed systems, it is not possible to have consistency, availability, and partition tolerance simultaneously, requiring a choice of two out of three, according to the following diagram.
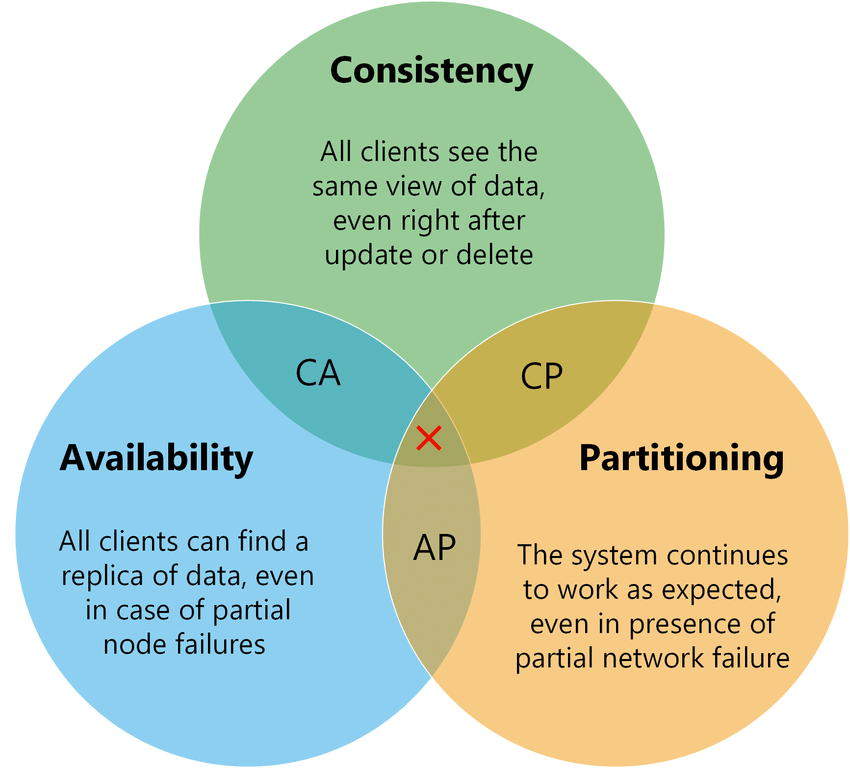
Source: https://medium.com/nerd-for-tech/understand-cap-theorem-751f0672890e
Hi Community!
We’re building a series of short, hands-on Instruqt tutorials to help newcomers get up to speed with InterSystems technologies faster and more effectively. To kick things off, we’ve just released a new tutorial, “Data Models of InterSystems IRIS,” covering the fundamentals of the IRIS multimodel approach. This is exactly the type of focused, concise, practical learning experience we want to expand. And this is where you come in!
We’d love to hear your ideas for other tutorial topics to help developers new to InterSystems IRIS take their first steps with confidence. Please welcome the new sweepstakes:
💡 Topics for hands-on Instruqt Tutorials 💡

New
hi 😊,
i'm able to LOAD DATA in IRIS from a rather complex, say Oracle's, query. It works pretty well but requires a target table created aforehand:
LOAD DATA FROM JDBC CONNECTION SOME_OTHER_SERVER QUERY 'complex query here' INTO TargetTableis there a way to base such target table on the same query ?
CREATE FOREIGN TABLE seems to require a column definition which I would prefer to be taken from the query
CREATE TABLE AS SELECT seems to be for local queries and other methods, like Linked Table Wizard or %SYSTEM.SQL.Schema.
Hi Developers!
Currently I have 2000+ lines in a class, and I think it's a lot already? What are the best practices?
if 10K lines OK? How do you cope with it? Please share?

New
Hello,
I am working on integrating a CELL-DYN Ruby hematology analyzer (Abbott) with InterSystems Ensemble using the ASTM E1394 protocol over TCP/IP via a Digi One SP serial-to-TCP converter. I am facing a persistent issue where the Link Test keeps failing on the CDRuby side and the Transmit button remains greyed out. I have overridden EOTOptional=1 in the service class file as Ensemble was not able to send ACK after ENQ. Now I am getting below logs like Machine sends ENQ, Ensemble sends back ACK and Machine sends EOT instead of STX.
Hey Developers,
Thank you for being part of the InterSystems Developer Ecosystem!
We truly appreciate your participation across the Developer Community, Open Exchange, Global Masters, and the Ideas Portal.
Each year we run a short survey to understand how we can improve our platforms and better support developers like you. Your feedback helps us shape the future of the ecosystem.
Please take a few minutes to complete the survey:
👉 InterSystems Developer Ecosystem Annual Survey 2026 (3-5 min, 12 questions)

Note: The survey takes less than 5 minutes to complete.
New
Hey Community,
We're bringing our Developer Ecosystem session back to READY 2026.
👥 Streamlining Development Workflow with InterSystems Developer Community and Ecosystem
🗓️ Wednesday, April 29, 2026
🕑 3:30 PM – 3:50 PM ET
📍 Cherry Blossom, Gaylord National Resort & Convention Center, National Harbor, MD


A question that quickly arises when configuring IAM (aka Kong Gateway) is how many routes should be created to reach all the business objects in an IRIS API.
A common mistake is to create one route per business object, unnecessarily multiplying the number of routes.
If you already know Java (or .Net) and perhaps also have used other document databases (or looking for one), but you are new to the InterSystems world, this post should help you.
InterSystems IRIS Cloud Document is a fully managed document database that lets you store JSON documents and query them with familiar SQL syntax, delivered as a cloud service managed by InterSystems.
In this article pair I’ll walk you through:
- Part I - Intro and Quick Tour (this article)
- What is it?
- Spinning up an InterSystems IRIS Cloud Document deployment
- Taking a quick tour of the service via the service UI
- Part II - Sample (Dockerized) Java App (the next article)
- Grabbing the connection details and TLS certificate
- Reviewing a simple Java sample that creates a collection, inserts documents, and queries them
- Setting up and running the Java (Dockerized) end‑to‑end sample
The goal is to give you a smooth “first run” experience.

Starting with InterSystems IRIS 2025.1, the way dependent cubes are handled in cube builds and cube synchronizes was changed.
This change may require modifying custom build/synchronize methods. If you are using the Cube Manager, these changes are already considered and handled, which means no action is needed.
Prior to this change, cubes were required to be built and synchronized in the proper order and account for any cube relationships/dependencies. With this change, dependent cubes are automatically updated as needed when using the %BuildCube or %SynchronizeCube APIs.
Please, provide Code example to build a %Library.DynamicObject or a %Library.DynamicArray from Resultset followed by converting to JSON
New
Hi everyone,
I was wondering if it is possible to use the InterSystems Server VSCode Extension to work in client side mode but importing locally the content of a project without having to choose the files manually.
It would be awesome to have all project-related assets synchronized in one go. Relying on InterSystems Projects (.prj files) would be convenient for several reasons:
- Projects bundle different file types (CLS, MAC, INT, CSP). Importing the project as a whole is much more efficient than picking individual files piece by piece.
New
Claude Code has a strong understanding of IRIS, but unexpected issues still occur.
The first issue is one that has already happened several times and is likely to continue occurring if not properly addressed.
In IRIS, the collation for string data (%String) is set to SQLUPPER by default. As a result, when data is retrieved via SQL, it may be returned in uppercase (for example, when sorting and aggregating with GROUP BY).
Hi developers!
In a method I need to return a result as a dynamic object aka JSON Object. And here is my logic:
Classmethod Planets() as %DynamicObject {
set val1="Jupiter"
set val2="Mars"
// this doesn't work! cannot compile
return {"value1":val1, "value2":val2}
}So I need to do the following:
Dynamic Entities (objects and arrays) in IRIS are incredibly useful in situations where you are having to transform JSON data into an Object Model for storage to the database, such as in REST API endpoints hosted within IRIS. This is because these dynamic objects and arrays can easily serve as a point of conversion from one data structure to the other.
New
HealthShare Unified Care Record Fundamentals – Virtual* May 4-8, 2026
*Please review the important prerequisite requirements for this class prior to registering.
- Learn the architecture, configuration, and management of HealthShare Unified Care Record.
- This 5-day course teaches HealthShare Unified Care Record users and integrators the HealthShare Unified Care Record architecture and administration tasks.
- The course also includes how to install HealthShare Unified Care Record.
- This course is intended for HealthShare Unified Care Record developers, integrators, administrators and managers.
New
Hi Community!
Welcome to Issue #28 of the InterSystems Ideas newsletter! Let's look at the latest news from the Ideas Portal, such as:
✓ General Statistics
✓ Update on the current sweepstakes
✓ Your ideas implemented by InterSystems

And a little teaser: look forward to an exciting initiative linking Ideas Portal, Open Exchange, Global Masters, and Developer Community!
Hi Community!
It's time to share the Top InterSystems Ideas Portal Contributors of 2025 🌟
(1).jpg)
New
Hi, Community!
Need help setting up OAuth on the FHIR Server? We'll guide you through the workflow:
New
Since I started using Claude Code, my motivation to create things has skyrocketed.
Previously, even if I wanted to build something, actually doing the coding felt like a hassle, so unless there was a very strong need, I rarely went as far as programming. But now, if I just jot down the specifications, Claude Code handles the rest automatically, resulting in a dramatic improvement in productivity.
I come from a generation native to ObjectScript, so I used to feel some hesitation when it came to switching to Python.
New
Hello and welcome to the Developer Ecosystem News!
The first quarter of the year was full of exciting activities in the InterSystems Developer Ecosystem. In case you missed something, we've prepared a selection of the hottest news and topics for you to catch up on!

Recently, I replaced my old laptop with a new one and had to migrate all my data. I was looking for a guide but couldn’t find anything that explained in detail how to migrate server connections from InterSystems Studio and Visual Studio Code from one PC to another. Simply reinstalling the tools is not enough, and migrating all the connections manually seemed like a waste of time. In the end, I managed to solve the problem, and this article explains how.
InterSystems Studio
Exporting Server Connections
Migrating Studio connections was the most challenging part.
New
Hello,
can someone confirm to me if image for docker deployment of IRIS are ready for production? Also what about Healtshare products?
Thank you.

