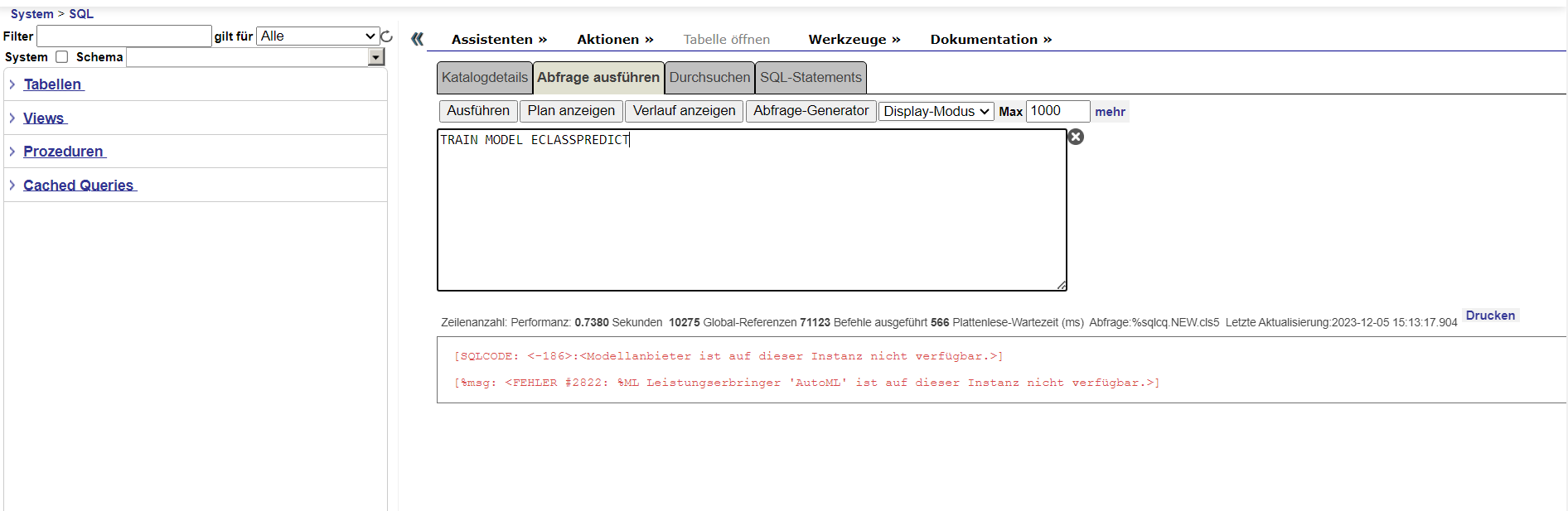
Machine learning (ML) is a subset of artificial intelligence in the field of computer science that often uses statistical techniques to give computers the ability to "learn" with data, without being explicitly programmed.
Some days ago, I've seen a youtuber talking about how to create a neural network (sorry, is in spanish)
https://www.youtube.com/embed/iX_on3VxZzk [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
When we have to predict the value of a categorical (or discrete) outcome we use logistic regression. I believe we use linear regression to also predict the value of an outcome given the input values.
Then, what is the difference between the two methodologies?
Hi everyone, I'll be honest with you I don't have much idea how to do this, but I was asked to install IRIS for Health on an AWS ubuntu machine(ssh -i "teleker-net.pem" ubuntu@xx.xxx.xx.xxx(no I will put the real number)). My boss has sent me the .key and .pem files that I am supposed to need for the installation.
I'm trying to deploy a container based on IRIS Community for Health ML image available from this url but when I start the container the memory consumption skyrockets to 99% making impossible to work with the instance (it never goes below the 95% of the memory). When I do the same with the IRIS Community for Health image it never goes over 80% of memory.
 By likes
By likes