 By replies
By replies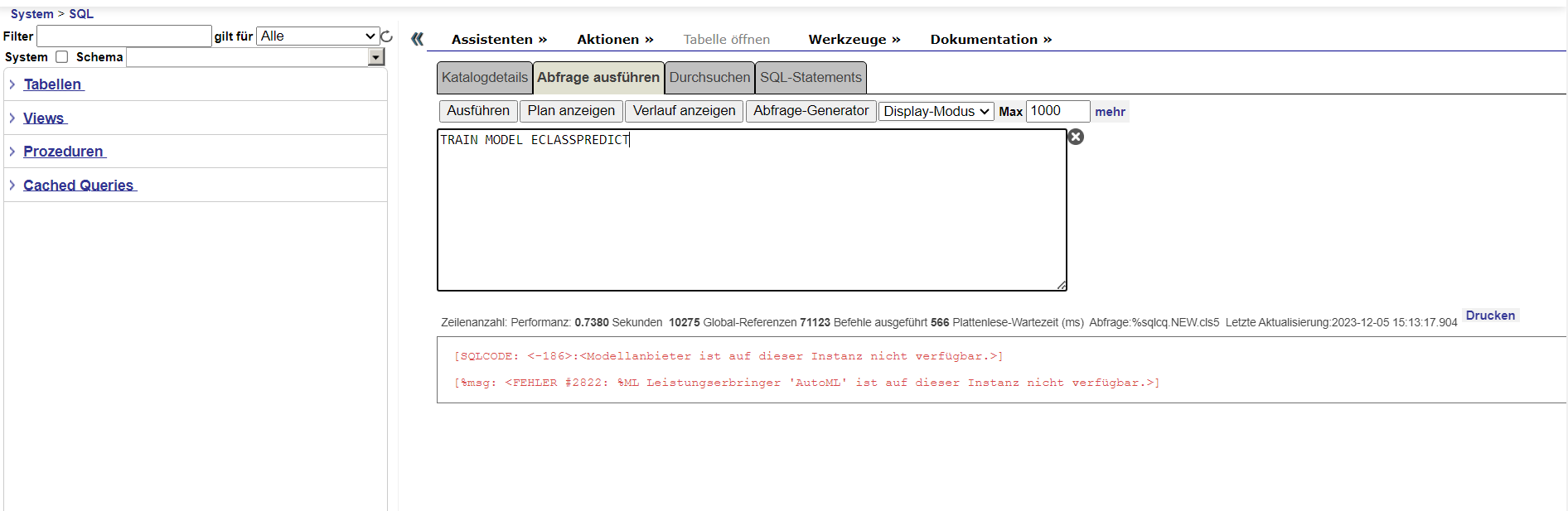
Hi all,
Some days ago, I've seen a youtuber talking about how to create a neural network (sorry, is in spanish)
https://www.youtube.com/embed/iX_on3VxZzk
[This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]