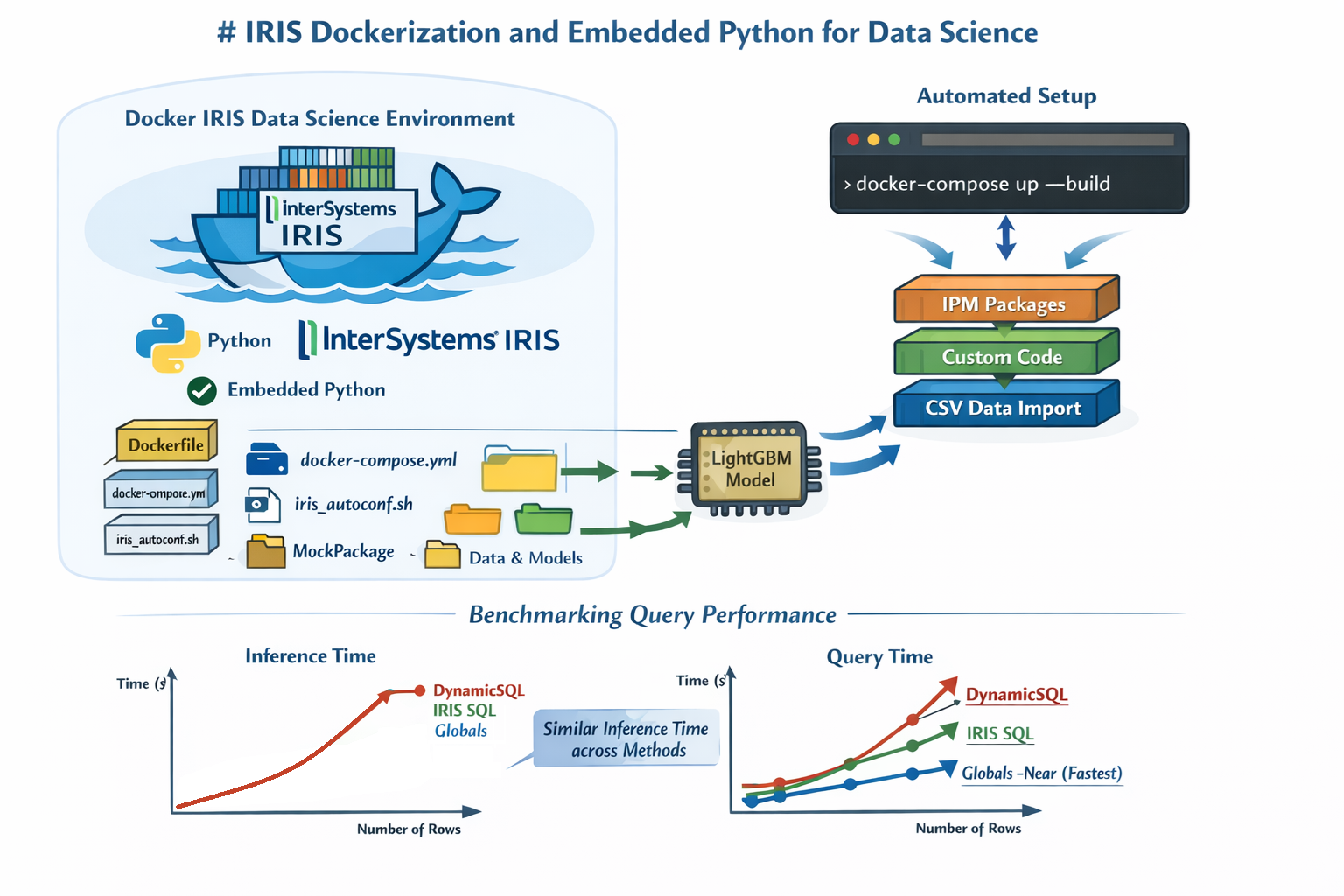
This article presents a straightforward approach to automatically and efficiently tune hyperparameters for machine learning models using Optuna as the optimisation framework. We explore how to use both Optuna’s native storage options and InterSystems IRIS as a database backend to track the progress of hyperparameter searches. We also show how MLflow can be used to monitor experiments and manage models through its tracking and model registry UI.
This article is based on this Kaggle Notebook, which you can run and directly edit yourself.