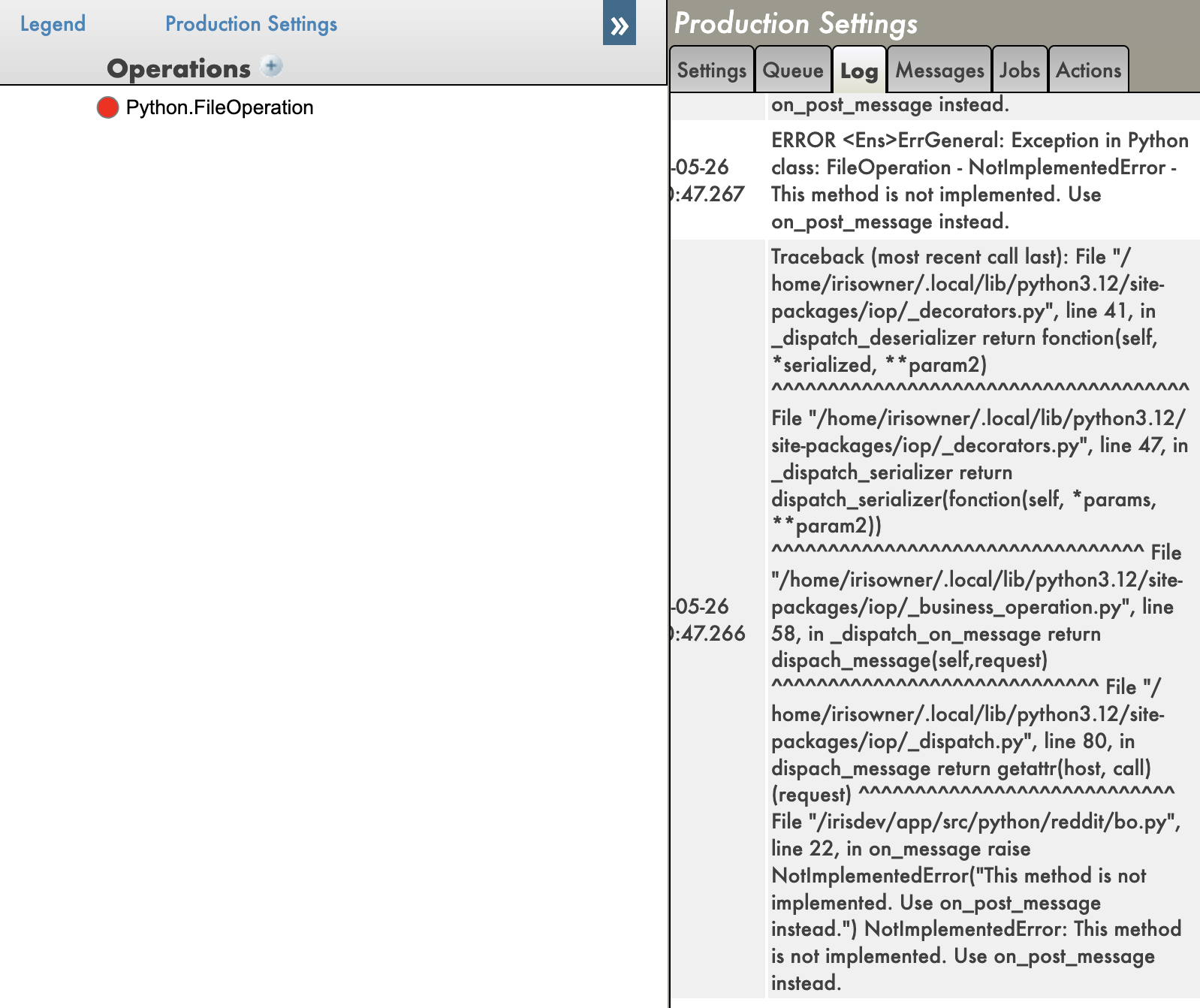
Great very useful, i plan to do the same but for classes, it's ok for custom classes they are on your local folder, the LLM claude, codex, copilot can parse them, but not for server side classes for example in Ens.Director or others.
Do you plan to support it too ?
- Log in to post comments
.png)