Internal Structure of Caché Database Blocks, Part 1
InterSystems Caché globals provide very convenient features for developers. But why are globals so fast and efficient?
Theory
Basically, the Caché database is a catalog having the same name as the database and containing the CACHE.DAT file. On Unix systems, the database can also be an ordinary disk partition.
All data in Caché is stored in blocks which, in turn, are organized as a balanced B* tree. Taking into account that all globals are basically stored in a tree, global's subscripts will be represented as branches, while values of global's subscripts will be stored as leaves. The difference between a balanced B* tree and an ordinary B tree is that its branches also have right links that can help to iterate through subscripts (i.e. globals in our case) rapidly using the $Order and $Query functions without getting back to the trunk of the tree.
By default, each block in the database file has the fixed size of 8,192 bytes. You can not modify size of block for already existed database. While you creating new database you can choose 16kB, 32 kB or even 64 kB blocks – depending on the data type you are going to store. However, always keep in mind that all data is read block-by-block – in other words, even if you request a single value of 1 byte in size, the system will read several blocks among which the requested data block will be the last one. You should also remember that Caché uses global buffers to store database blocks in memory for second use, and as well as size of blocks buffers has the same sizes. You cannot mount an existing database or create a new one when a global buffer with the corresponding block size is missing in the system. You should define size of memory which you want to be allocated for concrete size of blocks. It is possible to use buffers blocks bigger than database blocks, but in this case each buffer block will store only one database block, even smaller.
In this picture, a memory for the global buffer of 8 kB in size is allocated for the use with databases consisting of 8 kB blocks. Blocks which are not empty in this database defined in maps, so that one of the maps defines 62,464 blocks (for 8kb blocks).
Block types
The system supports multiple block types. At each level, right links of a block must point to a block of the same type or to a null block which defines the end of data.
- Type 9: Block of a global catalog. These blocks usually describe all existing globals along with their parameters, including collation of global's subscripts which is one of the most important parameters that cannot be modified once the global is created.
- Type 66: Block of high-level pointers. Only a block of a global catalog can be on top of these blocks.
- Type 6: Block of low-level pointers. Only blocks of high-level pointers can be on top of these blocks and only data blocks can be placed lower.
- Type 70: Block of both high-level and low-level pointers. These blocks are used when the corresponding global stores a small number of values and therefore multiple levels of blocks are not required. These blocks usually point to data blocks, just as blocks of a global catalog do.
- Type 2: Block of pointers for storing a relatively large global. In order to allocate values among data blocks evenly, you may want to create additional levels of blocks of pointers. These blocks are usually placed between the blocks of pointers.
- Type 8: Data block. These blocks usually store values of several global nodes rather than of only one node.
- Type 24: Block for large strings. When a value of a single global is bigger than a block, then such value will be recorded into a special block for large strings, while the data block node will be storing links to the list of blocks for large strings along with the total length of this value.
- Type 16: Map block. These blocks are designed for storing information about unallocated blocks.
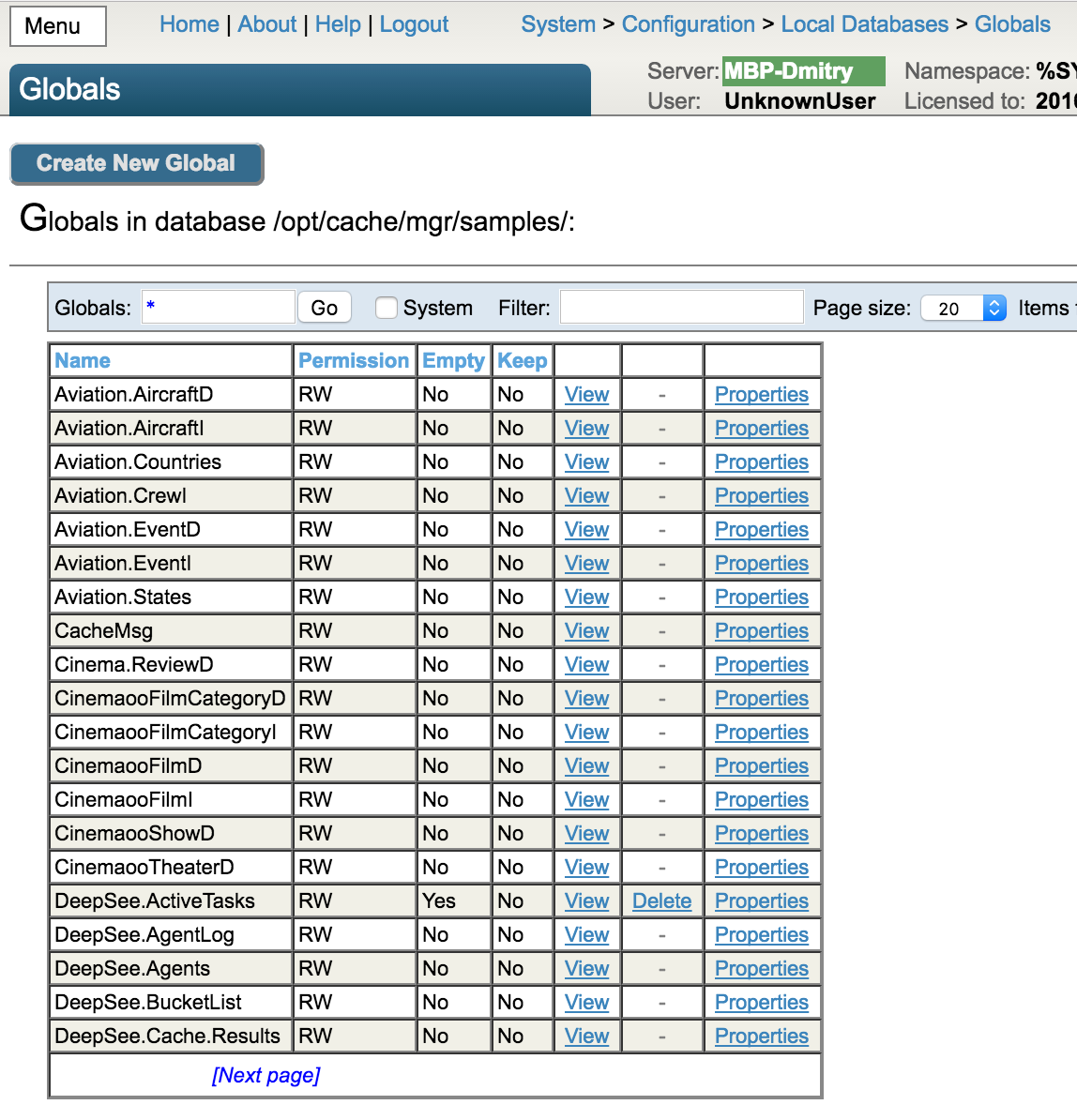
So, the first block of a typical Caché database contains service information about the database file itself, while the second blocks provides a map of blocks. The first catalog block goes on the third place (block #3), and a single database can have several catalog blocks. The next ones are blocks of pointers (branches), data blocks (leafs), and blocks of large strings. As I have mentioned above, blocks of global catalogs store information about all existing globals in the database or global settings (if not data is available in such a global). In this case, a node that describes such a global will have a null lower pointer. You can view the list of existing globals from the global catalog on the management portal. This portal also allows you to save a global in the catalog after deletion (e.g. save its collating sequence) as well as create a new global with either default or custom collate.
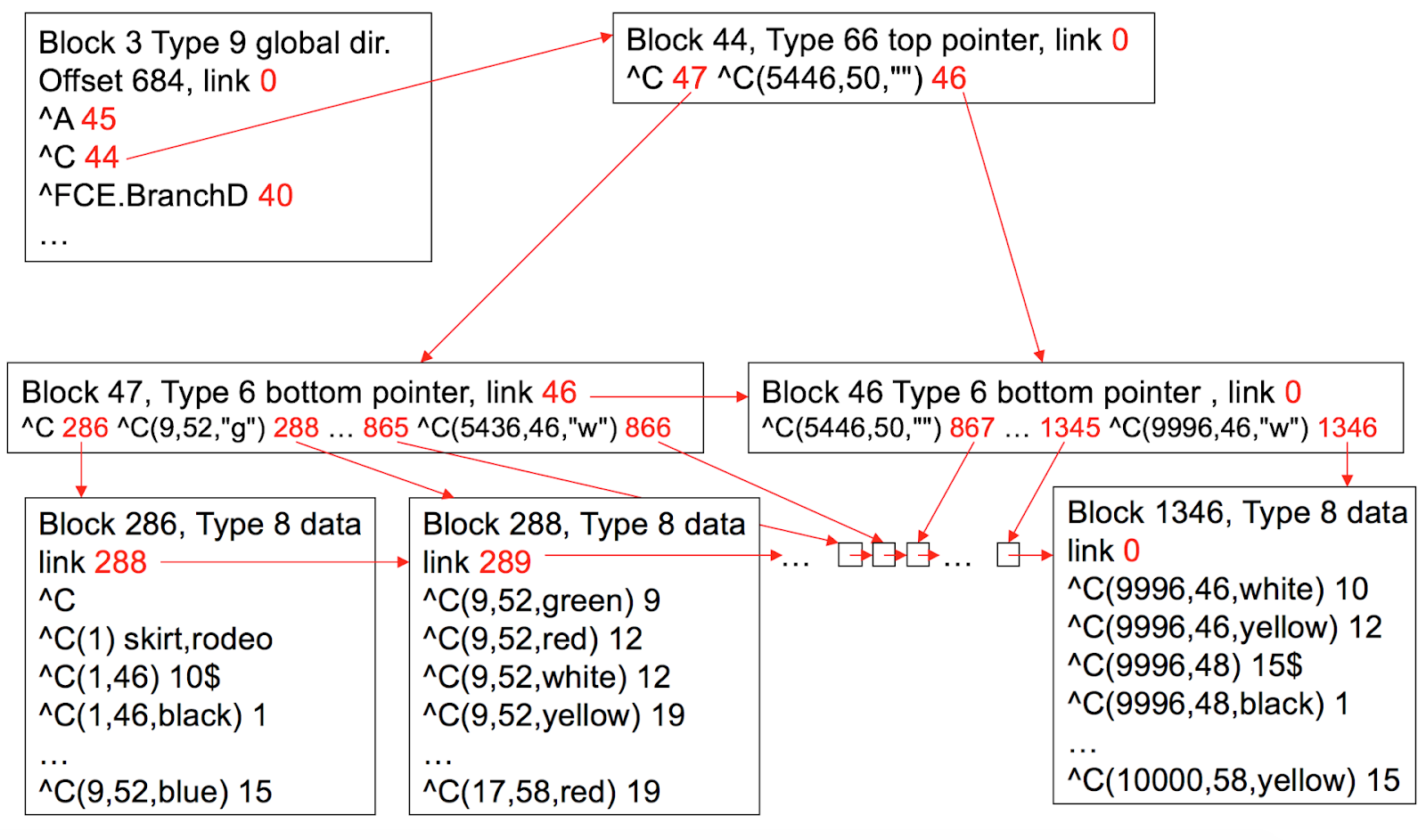
In general, the tree of blocks can be represented as in the picture below. Note that links to blocks are shown in red color.
Database integrity
In the current version of Caché, we have resolved the most important issues and problems with databases, so that the risks of database degradation are extremely low. However, we still recommend that you run automatic integrity checks regularly using our ^Integrity tool – you can launch it in the terminal from the %SYS namespace, via our management portal, on the Database page or via the task manager. By default, the automatic integrity check is already set up and predefined, so that the only thing you need to do is to activate it:
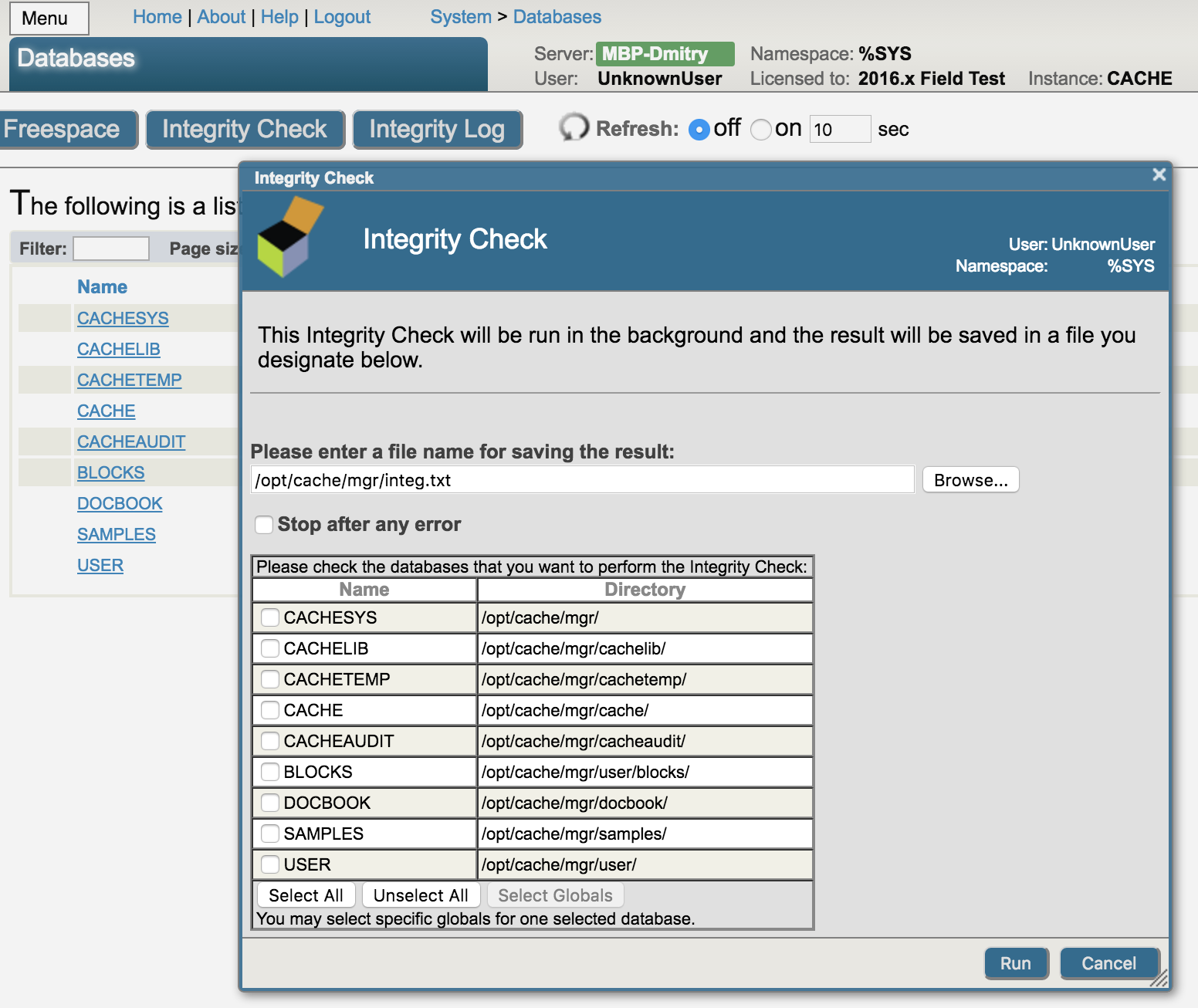

The integrity check includes verification of links at the lower levels, validation of block types, analysis of the right links and matching of global nodes with the applied collating sequence. If any errors are found during the integrity check, you can run our ^REPAIR tool from the %SYS namespace. Using this tool, you can view any block and modify it as required, i.e. repair your database.
Practice
However, this was only theory. It is still difficult to figure out what do a global and its blocks actually look like. Presently, the only way to view blocks is to use our ^REPAIR tool mentioned above. The typical output of this program is shown below:

A year ago, I have started a new project to develop a tool that iterates through a tree of blocks without any risks of database damage, visualizes these blocks in a web UI and provides options for saving their visualization in SVG or PNG. The project is called CacheBlocksExplorer, and you can download its source code on Github.
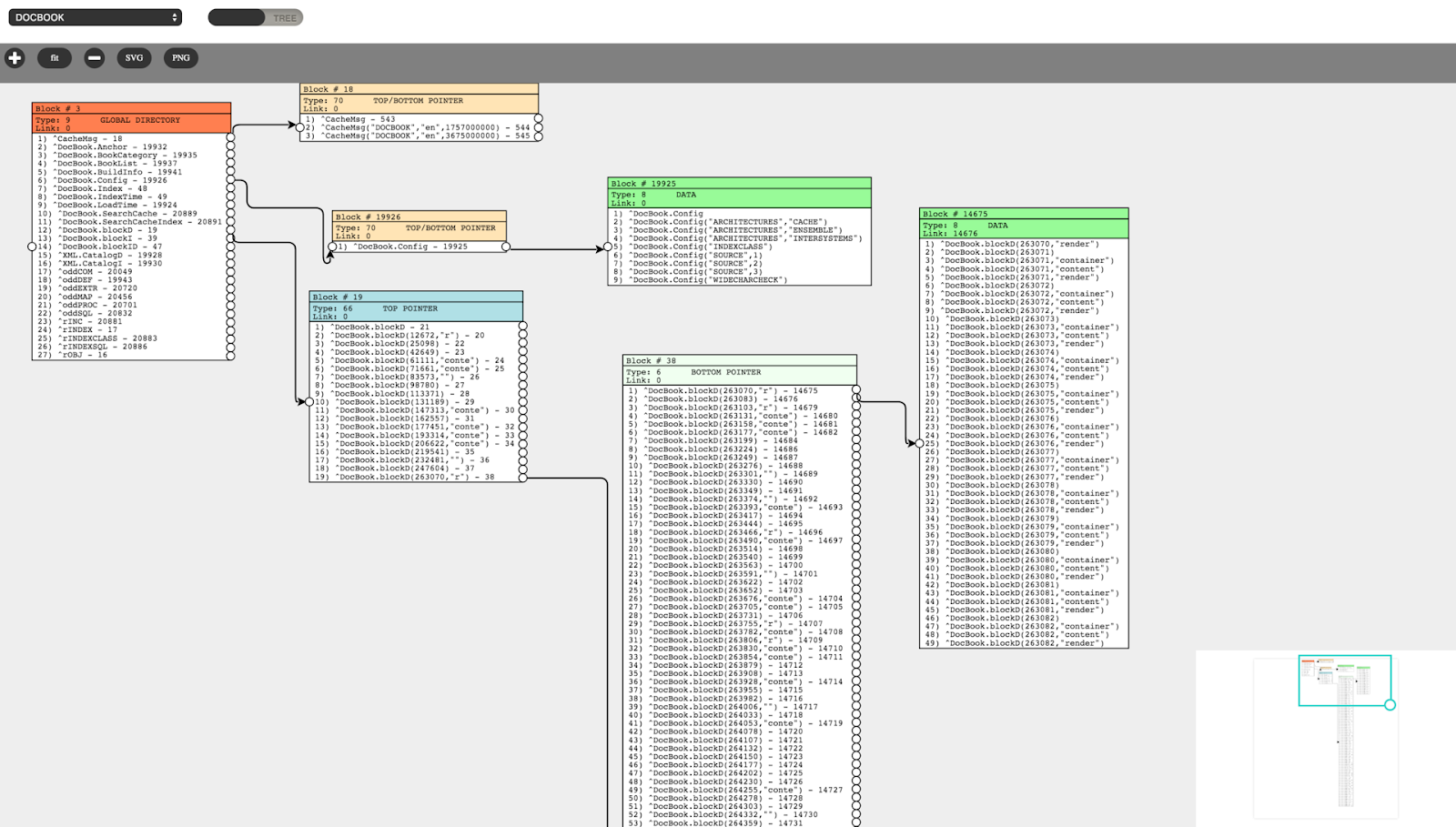
The implemented features include:
- View any configured or simply mounted database in the system;
- View information by block, block type, right pointer, list of nodes with links;
- View detailed information about any node pointing to a lower block;
- Hide blocks by removing links to them (without any damage to the data stored in these blocks).
The to-do list:
-
Displaying right links: in the current version, right links are shown in the information about blocks, but it would be better to display them as arrows;
-
Display blocks of large strings: they are simply not shown in the current version;
-
Display all blocks of global catalog rather than only the third one.
I would also want to display the entire tree, but still cannot find any library able to rapidly render hundreds of thousands blocks along with their links – the current library renders them in web browsers much slower than Caché reads the whole structure.
In the next article, I will try to describe in more detail how it works, provide some usage examples and demonstrate how to retrieve lots of actionable data about globals and blocks using my Cache Block Explorer.
Comments
Very interesting. Thank You.
I've just published next part of this article
Hi, You wrote: "Taking into account that all globals are basically stored in a tree, global's subscripts will be represented as branches, while values of global's subscripts will be stored as leaves. "
Are you saying that a subscript of "Cat" which points to a record that consists of (Legs=4, Fur=True, Tail=True, Attitude=100) is stored in the leaf (along with the data associated with it), or that the data it points to is stored in the leaf? I'm trying to figure out where the string "Cat" lives.
Thanks. Really interesting article. I used to play with file systems and database internals.
So let's suggest you have some object with such properties (Legs=4, Fur=True, Tail=True, Attitude=100). In a global it will looks something like this
^MyPets("Cat")=$lb(4,1,1,100)And in this case, we should have any pointer block in anyway, and while we don't have so many data in our global, yet. Type for pointer block will be 70
Block Repair Function (Current Block 3): 44 Block # 44 Type: 70 TOP/BOTTOM POINTER Link Block: 0 Offset: 40 Count of Nodes: 1 Collate: 5 --more-- # Node POINTER 1 ^MyPets 78
But we also have not so big value for our object, and data block can store subscripts in this block, as well as a value.
Block Repair Function (Current Block 44): 78
Block # 78 Type: 8 DATA
Link Block: 0 Offset: 60
Count of Nodes: 2 Collate: 5 Big String Nodes: 0
Pointer Length:6 Next Pointer Length:0 Diff Byte:Hex 0
Pointer Reference: ^MyPets
Next Pointer Reference:
Next pointer stored? No
--more--
# Node Data
1 ^MyPets
2 ^MyPets("Cat") $lb(4,1,1,100)
Or our global could be looks a bit different
^MyPets("Cat","Attitude")=100
^MyPets("Cat","Fur")=1
^MyPets("Cat","Legs")=4
^MyPets("Cat","Tail")=1But change nothing.
Block Repair Function (Current Block 44): 78
Block # 78 Type: 8 DATA
Link Block: 0 Offset: 108
Count of Nodes: 5 Collate: 5 Big String Nodes: 0
Pointer Length:6 Next Pointer Length:0 Diff Byte:Hex 0
Pointer Reference: ^MyPets
Next Pointer Reference:
Next pointer stored? No
--more--
# Node Data
1 ^MyPets
2 ^MyPets("Cat","Attitude") 100 *
3 ^MyPets("Cat","Fur") 1 *
4 ^MyPets("Cat","Legs") 4 *
5 ^MyPets("Cat","Tail") 1 *
So, we can see that yes, our subscripts now stores only in data block, yes it is, but they represent here as a nodes, and could be named as branches in a tree, we still have to store data in a data block, but we also need to store information about global, that's why we can see it here. And when will get more data than could be stored in one block, this block will be splitted, and in a parent block will see two nodes, for first nodes in a children blocks.
The pictures do not load.
Check it now, should be ok
It sure is!
Hello Dmitry, First of all, very nice article! Do you know, or where can I find, how exactly are the data written within each of these blocks? I would like to see kind of a byte-to-byte representation. Further, when it is being said about data being stored as a B* tree, is it meant in a sense of tree of above mentioned blocks or is there also a tree-like structure within each of the blocks? For example, if I search for ^C(9996,46, yellow), I would jump to block #1346 and from there on I will iterate through each element of the block until I get to ^C(9996,46,yellow). Is this correct?
I'm not an InterSystems guy and can say only from my point of view, how it works.
Every global name has internal representation in some kind of binary format, I don't know how it can be converted to and back. But this string used to find a correct block. Like when you looking for ^C(9996,46, yellow), it first should read Map (Block 3), to find where Global ^C started (Block 44), then using this internal format for global, it can find the closest node in the first pointer block if it points to another pointer block, the same search repeats until it reached any Data block, which may also contain data for multiple nodes.
Not sure If I can better explain it, but most important is that B* tree helps to very quickly find the final block, and their neighbours.
@Aleksandar Kovacevic
ISC Engineering & Support has this information and also appropriate tools for analysis.
You better contact them directly in Cambridge.
@Dmitry Maslennikov : Excellent explanation ![]()