How to find duplicates for a large text field in Caché Objects?
Hi, folks!
Suppose you have a Caché class with %String property which contains relatively large text (from 10 to 2000 symbols).
The class:
Class Test.Duplicates Extends %Persistent
{
Property Text As %String (MAXLEN = 2000);
}And you have thousands of entries.
What are the best options to find entries which are duplicates on this property?
Comments
For best performance, you need index on this property. And request something like this.
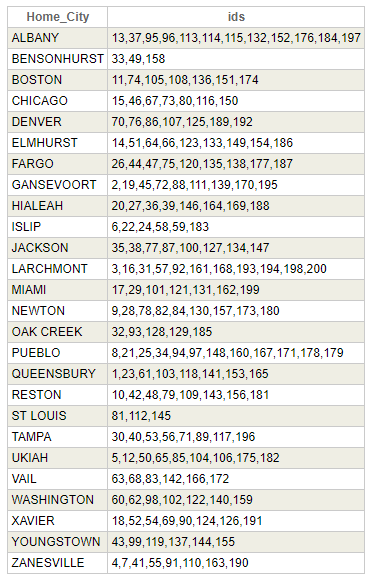
SELECT Home_City,list(ID) ids FROM sample.person GROUP BY Home_City HAVING count(*)>1
And result will be something like this
Thanks, Dmitry. Yes, the focus is - best performance.
But what about the index declaration? There is a limitation of 511 symbols in an index, right?
Should I put that in an index declaration or it will solve it for me automatically if I index an entry with value >511 symbols?
Thanks, Eduard. But I'm looking for duplicates, not for similar records. How can %SIMILARITY help here?
but hashing sounds more promising
Hi, Robert!
Thanks! That's really nice!
an example how to use:
https://community.intersystems.com/post/unlimited-unique-index
Do I understand it correctly?
? Uniqueness is not forced
Hi, Vitaly!
Thanks for your input! This is very interesting and totally different approach to solve the task which I like every time about InterSystems technology that problems can be solved with different approaches and you never know how many options even exist )
Yep, right, looks like Index can't help here and problem not only 511(and this length could be different on different strings).
But, you still can use Index but you should set length which should be stored. But find duplicates you can do without SQL, just by reading this index, it should be much faster, to find, all duplicates by indexed value, and then you can compare real values.
You can calculate a hash for each string and index this hash value. If use pure COS for index building, you can find duplicates earlier, just during index building, without quiering the index afterwards.
Or just add calculated indexable property with hash to this string, and use this property in SQL
I think it mostly depends on your task, how strongly you should care about duplications.
And I think that SHA1 should be enough
So, the final recipe looks like following:
For Insert and Update calculate the hash e.g. with MD5 and put it in Hash property. Index it with not unique index.
Find duplicates with SQL query on Hash where group by for hash shows more than one occurrence.
Loop through all the values with same hash just and check Text property values to be sure that they are duplicates but not hash collisions.
Thanks, Alex, Dmitry, Robert!
Just for info:
I'm elaborating a suggestion for an 'unlimitted' UNIQUE index based on old code fragments.
It may take some time depending on my luck on personal backups.
Here it is:
https://community.intersystems.com/post/unlimited-unique-index
It depends.
If you don't care about uniqueness of this hash, you can use any algorithm (the quicker the better, MD5Hash or even CRC32) and store your index like normal non-unique one. On calculated hash match to already stored (indexed) hash value you just compare the correspondent strings to separate real matches from the collisions. Maybe it's worth to use whole string as an index for reasonably short strings.
I like this idea:
Settting a property "HasDuplicates" during indexing
Thanks, @Alexey Maslov! What is the preferred algorithm to use hashes in this case?
And what about collisions? Should I care about that too?
True, but it can find also similar, but not identical, right?
THX .![]()
Duplicates are very similar.
Yes. This is solution on the original question "How to find duplicates?"
Possible prevent duplicates.
You can try to use %SIMILARITY function available in Cache SQL.
having this done ~ 9 yrs back I can't resist to share my old solution (at that time for a UNIQUE on 2000 char)
- split Text into 4 sections in calculated properties e.g.
tx1 = $e(Text,1,500)
tx2 = $e(Text,501,1000)
tx3 = $e(Text,1001,1500)
tx4 = $e(Text,1501,2000)
- index them
- then you can build an SQL statement to have all 4 pieces identic.
you end up with a cascade of embedded SELECTS
It's not to fast but very precise.
Class Test.Duplicates Extends %Persistent
{
Index iText On (Text(KEYS), Text(ELEMENTS)) [ Type = bitmap ];
Property Text As %String(MAXLEN = 2000);
ClassMethod TextBuildValueArray(
v,
ByRef arr) As %Status
{
#define sizeOfChunk 400
i v="" {
s arr("null")=v
}else{
s hasDupl=$$$YES
f i=1:1:$l(v)\$$$sizeOfChunk+($l(v)#$$$sizeOfChunk>0) {
s arr(i)=$e(v,1,$$$sizeOfChunk),$e(v,1,$$$sizeOfChunk)=""
s:hasDupl&&'$d(^Test.DuplicatesI("iText"," "_i,##class(%Collation).SqlUpper(arr(i)))) hasDupl=$$$NO
}
s:hasDupl arr("hasDupl")=""
}
q $$$OK
}
ClassMethod Test()
{
;d ##class(Test.Duplicates).Test()
d ..%KillExtent()
s text=##class(%PopulateUtils).StringMin(2000,2000)
&sql(insert into Test.Duplicates(Text)
select 'ab'
union all select 'abc' union all select 'abc'
union all select 'abe' union all select 'abe' union all select 'abe'
union all select null union all select null
union all select :text union all select :text)
d $SYSTEM.SQL.PurgeForTable($classname()),
$system.SQL.TuneTable($classname(),$$$YES),
$system.OBJ.Compile($classname(),"cu-d")
s sql(1)="select %ID,$extract(Text,1,10) Text10 from Test.Duplicates",
sql(2)="select * from Test.Duplicates where FOR SOME %ELEMENT(Text) (%KEY='null')",
sql(3)="select %ID,$extract(Text,1,10) HasDupl_Text10_All from Test.Duplicates where FOR SOME %ELEMENT(Text) (%KEY='hasdupl')",
sql(4)="select distinct $extract(%exact(Text),1,10) HasDupl_Text10 from Test.Duplicates where FOR SOME %ELEMENT(Text) (%KEY='hasdupl')"
f i=1:1:$o(sql(""),-1) w !,sql(i),!! d ##class(%SQL.Statement).%ExecDirect(,sql(i)).%Display() w !,"---------",!
}
}Result:
USER>d ##class(Test.Duplicates).Test() select %ID,$extract(Text,1,10) Text10 from Test.Duplicates ID Text10 1 ab 2 abc 3 abc 4 abe 5 abe 6 abe 7 8 9 QfgrABXjbT 10 QfgrABXjbT 10 Rows(s) Affected --------- select * from Test.Duplicates where FOR SOME %ELEMENT(Text) (%KEY='null') ID Text 7 8 2 Rows(s) Affected --------- select %ID,$extract(Text,1,10) HasDupl_Text10_All from Test.Duplicates where FOR SOME %ELEMENT(Text) (%KEY='hasdupl') ID HasDupl_Text10_All 3 abc 5 abe 6 abe 10 QfgrABXjbT 4 Rows(s) Affected --------- select distinct $extract(%exact(Text),1,10) HasDupl_Text10 from Test.Duplicates where FOR SOME %ELEMENT(Text) (%KEY='hasdupl') HasDupl_Text10 abc abe QfgrABXjbT 3 Rows(s) Affected ---------
Notes:
- not used hashing, so there's no risk of collisions
- support for strings of unlimited length up to 3641144 ($zu(96,39))
- customizable chunk size
- minimum code
- should work for older versions of Caché
- high performance
- possible else more optimize code ;)
I would probably go for some extra hashing safety and add a CRC or something similar to the hash. There may be more subtle hashing methods or combinations thereof that will make duplicates "almost impossible" ;)
Class Test.Duplicates Extends %Persistent
{
Property myText As %String (MAXLEN = 32000);
Property myHash as %String (MAXLEN=50)
[SqlComputed,
Calculated,
SqlComputeCode={ set {myHash} = $SYSTEM.Encryption.MD5Hash({myText})_"|"_$ZCRC({myText},7)},
SqlComputeOnChange = (%%INSERT,%%UPDATE,myText)
];
/// a bitmap would not be worth the effort
Index ixMyHash on myHash;
ClassMethod RunTest(pMax as %Integer = 1000, pDelete as %Boolean = 0)
{
write !,"begin "_..%ClassName(1)
do DISABLE^%SYS.NOJRN()
try
{
&sql(SET TRANSACTION %COMMITMODE NONE)
do:pDelete ..%KillExtent()
for tIdx = 1 : 1 : pMax
{
set tRandomStr = ##class(%PopulateUtils).StringMin(100,32000)
&sql(INSERT INTO Duplicates(myText) VALUES(:tRandomStr))
continue:SQLCODE'=0
write:(tIdx#100=0) !,tIdx_" records inserted"
}
&sql(SET TRANSACTION %COMMITMODE IMPLICIT)
}
catch(tEx)
{
write !,"Oops..."
write !,tEx.DisplayString()
}
DO ENABLE^%SYS.NOJRN()
write !,"end "_..%ClassName(1)
}
}
I don't think that checking for duplicates can be solved other than have a reliable index per hash.
Note you can have more subtle hashing (hash sub-pieces, etc.) but you cannot have a reliable hasDuplicate property at runtime that goes beyond the current snapshot of data during INSERT. IOW, it does not mean much in a system with lots of concurrent access.
In the end if will be
SELECT COUNT(*) AS CountDuplicates
FROM Test.Duplicates
GROUP BY myHash
HAVING COUNT(*) > 1
If you want to avoid duplicates you can make the index unique.