Hola Comunidad,
En este artículo, voy a presentar mi aplicación iris-RAG-Gen .
Iris-RAG-Gen es una aplicación generativa AI Retrieval-Augmented Generation (RAG) que aprovecha la funcionalidad de IRIS Vector Search para personalizar ChatGPT con la ayuda del framework web Streamlit, LangChain, y OpenAI. La aplicación utiliza IRIS como almacén de vectores.

Características de la aplicación
- Ingesta de documentos (PDF o TXT) en IRIS
- Chatear con el documento ingerido seleccionado
- Borrar Documentos ingerido
- OpenAI ChatGPT
Ingesta de documentos (PDF o TXT) en IRI
Seguid los siguientes pasos para ingerir el documento:
- Introducid a clave OpenAI
- Seleccionad el documento (PDF o TXT)
- Introducid la descripción del documento
- Haced clic en el botón Ingerir documento

La funcionalidad Ingest Document inserta los detalles del documento en la tabla rag_documents y crea la tabla 'rag_document + id' (id del rag_documents) para guardar los datos vectoriales.
El siguiente código Python guardará el documento seleccionado en vectores:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader, TextLoader
from langchain_iris import IRISVector
from langchain_openai import OpenAIEmbeddings
from sqlalchemy import create_engine,text
class RagOpr:
def ingestDoc(self,filePath,fileDesc,fileType):
embeddings = OpenAIEmbeddings()
if fileType == "text/plain":
loader = TextLoader(filePath)
elif fileType == "application/pdf":
loader = PyPDFLoader(filePath)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
COLLECTION_NAME = self.get_collection_name(fileDesc,fileType)
db = IRISVector.from_documents(
embedding=embeddings,
documents=texts,
collection_name = COLLECTION_NAME,
connection_string=self.CONNECTION_STRING,
)
def get_collection_name(self,fileDesc,fileType):
with self.engine.connect() as conn:
with conn.begin():
sql = text("""
SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'SQLUser'
AND TABLE_NAME = 'rag_documents';
""")
result = []
try:
result = conn.execute(sql).fetchall()
except Exception as err:
print("An exception occurred:", err)
return ''
if len(result) == 0:
sql = text("""
CREATE TABLE rag_documents (
description VARCHAR(255),
docType VARCHAR(50) )
""")
try:
result = conn.execute(sql)
except Exception as err:
print("An exception occurred:", err)
return ''
with self.engine.connect() as conn:
with conn.begin():
sql = text("""
INSERT INTO rag_documents
(description,docType)
VALUES (:desc,:ftype)
""")
try:
result = conn.execute(sql, {'desc':fileDesc,'ftype':fileType})
except Exception as err:
print("An exception occurred:", err)
return ''
sql = text("""
SELECT LAST_IDENTITY()
""")
try:
result = conn.execute(sql).fetchall()
except Exception as err:
print("An exception occurred:", err)
return ''
return "rag_document"+str(result[0][0])
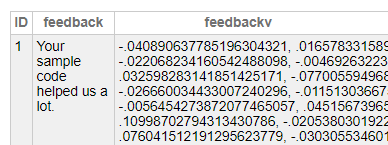
Escribid el siguiente comando SQL en el portal de gestión para recuperar los datos vectoriales
SELECT top 5
id, embedding, document, metadata
FROM SQLUser.rag_document2

Chatear con el documento ingerido seleccionado
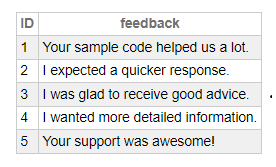
Seleccionad el Documento en la sección de opciones de chat y escribid la pregunta. La aplicación leerá los datos del vector y devolverá la respuesta correspondiente.

El siguiente código Python guardará el documento seleccionado en vectores:
from langchain_iris import IRISVector
from langchain_openai import OpenAIEmbeddings,ChatOpenAI
from langchain.chains import ConversationChain
from langchain.chains.conversation.memory import ConversationSummaryMemory
from langchain.chat_models import ChatOpenAI
class RagOpr:
def ragSearch(self,prompt,id):
COLLECTION_NAME = "rag_document"+str(id)
embeddings = OpenAIEmbeddings()
db2 = IRISVector (
embedding_function=embeddings,
collection_name=COLLECTION_NAME,
connection_string=self.CONNECTION_STRING,
)
docs_with_score = db2.similarity_search_with_score(prompt)
relevant_docs = ["".join(str(doc.page_content)) + " " for doc, _ in docs_with_score]
llm = ChatOpenAI(
temperature=0,
model_name="gpt-3.5-turbo"
)
conversation_sum = ConversationChain(
llm=llm,
memory= ConversationSummaryMemory(llm=llm),
verbose=False
)
template = f"""
Prompt: {prompt}
Relevant Docuemnts: {relevant_docs}
"""
resp = conversation_sum(template)
return resp['response']
Para más detalles, visitad la página de solicitud de intercambio abierto iris-RAG-Gen.
Gracias
 Open Exchange
Open Exchange