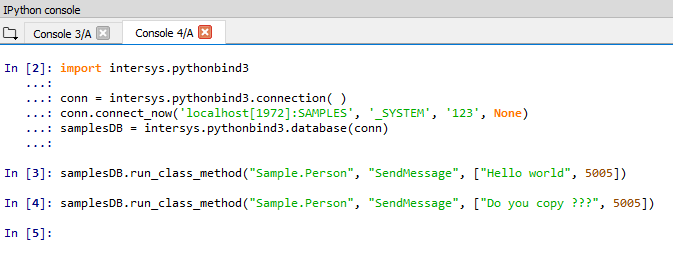
You can definitely compile and install cache-python binding module on x86-64 machines. I have done this on Ubuntu and it produced (pythonbind3-1.0-py3.6-linux-x86_64.egg). I am not sure I understand why it cannot be installed on IRIS x86-64bit platform. If you install python binding on IRIS I will be also interested in testing my CacheORM object-relational mapper.
- Log in to post comments