Thanks Yaron, these are helpful points.
- Log in to post comments
Thanks Yaron, these are helpful points.
This is a really interesting approach to try enable the ability to view the content of the https request being made, but it is worth noting that mitmproxy routinely triggers antivirus software, and therefore might not be a viable option for many.
I instead had to opt for throwing together a quick and dirty nodeJS app to get eyes on the output of the EnsLib.HL7.Operation.HTTPOperation to understand why I was hitting a snag with a supplier. Turns out the content-type from this operation is text/html and the supplier was expecting text/plain...
Well, this has got me ordering the hardware already!
I can't wait to get my hands on the repo, and look forward to the inevitable battle with our security team (which, to be fair, would be within their rights to be concerned).
The method that seemingly doesn't exist is "NameList" which you are attempting to call from your method "GetLastMethod".
You can demonstrate this by adding a trace before and after the following line and seeing that it never hits the second trace:
Set tSC = ..Adapter.NameList(.tFileList, ..FilePattern)The adapter for the file passthrough service is EnsLib.File.InboundAdapter, and this does not contain a method called NameList.
The Method as shown in my examples was "%Next" but you have missed the %.
See this more complete example:
Class Demo.Operations.GetResultsFromLookupTable Extends Ens.BusinessOperation
{
Method OnMessage(pRequest As Ens.Request, Output pResponse As Ens.StringContainer) As %Status
{
Set tSC = $$$OK
Set tStatement = ##class(%SQL.Statement).%New()
Set tQuery = "SELECT * From Ens_Util.LookupTable WHERE TableName = ?"
Set tTable = "testLookupTable"
$$$THROWONERROR(tSC,tStatement.%Prepare(tQuery))
Set tResult = tStatement.%Execute(tTable)
Set count = 0
While tResult.%Next(){
//Do what you need to with the results here
$$$TRACE("Result: "_tResult.KeyName_", "_tResult.DataValue)
Do $INCREMENT(count)
}
Set pResponse = ##Class(Ens.StringContainer).%New()
Set pResponse.StringValue = count_" results found."
Quit tSC
}
}
Which gives this in a trace:
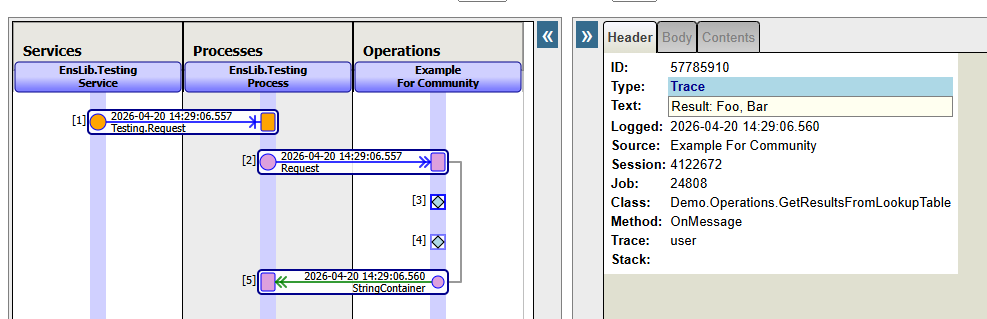
Also, please note that in my initial response, I had a mistake in the column names I referenced. I had put "KeyName" and "KeyValue" whereas the second should have been "DataValue" as you already had in your first screenshot.
Additionally, it's best that you avoid concatenation for building the string of your query, and should instead use parameters to avoid issues with unexpected characters breaking your query (or, in some scenarios, opening yourself up to exploits via SQL injection).
My example above should instead be:
Set tStatement = ##class(%SQL.Statement).%New()
Set tQuery = "SELECT * From Ens_Util.LookupTable WHERE TableName = ?"
$$$THROWONERROR(tSC,tStatement.%Prepare(tQuery))
Set tResult = tStatement.%Execute(tTable)
While tResult.%Next(){
//Do what you need to with the results here
$$$TRACE("Result: "_tResult.KeyName_", "_tResult.DataValue)
}Note that the table name is a ? in the initial query string, and the value of the table name is being referenced in the %Execute() method
Hey Nezla, if you are looking to interact with an internal table, then using the outbound adapter for SQL is not what will work for you. This is because the adapter relies on the servers ODBC config to look for the specified table in the external database based on the DSN you've configured.
You will instead want to swap your ObjectScript to something like:
Set tStatement = ##class(%SQL.Statement).%New()
Set tQuery = "SELECT * From Ens_Util.LookupTable WHERE TableName ='"_tTable_"'"
$$$THROWONERROR(tSC,tStatement.%Prepare(tQuery))
Set tResult = tStatement.%Execute()
While tResult.%Next(){
//Do what you need to with the results here
$$$TRACE("Result: "_tResult.KeyName_", "_tResult.DataValue)
}Then, if you still need to also query for something in the external database based on the DSN configured, then you can interact with the external database using the ..Adapter.ExecuteQuery approach you had attempted.
Once you have this setup working, I would say that you could add in a slight improvement and make it so that the Client is a configurable item for the Operation and not hard coded.
Hey Gigi.
In the past I have had to create a custom HL7 HTTP Operation that heavily relies on the code used by the built in Operation. Doing so comes with some risk risk, but in my use case it was required (the response could only be read using %Parser.ParseIOStream and not %Parser.ParseFramedIOStream). My change was effectively a copy of the SendMessage Method, with a single line changed.
In your case, I think you will want to do similar, but instead I think the following will need to be your approach:
This should hopefully add in the OAuth2 bearer token to the Http request as you need.
You will still need to configure your instance to be able to generate the OAuth token to be able to then make use of this.
If this is your first time working with OAuth2 in IRIS, I would start with making sure you are able to set this up and generate a token. Once configured within the management portal, you can try testing this by manually running the calls being made in the "AuthorizeMe" method and seeing if you get a valid token back (or add it to an adhoc classmethod so you can call that on each test instead of needing to manually run the required lines).
Hi Mark.
Do you mean that you're trying to have a drop down in the "table" field when using your custom lookup function?
If so, I don't think this is possible as the logic for this seems to be buried in a system zen page that is explicitly looking out for both the "Lookup" and "Exists" function by name to give this behaviour.
What's the reason for not using the EnsLib.HL7 classes for your Ensemble interface?
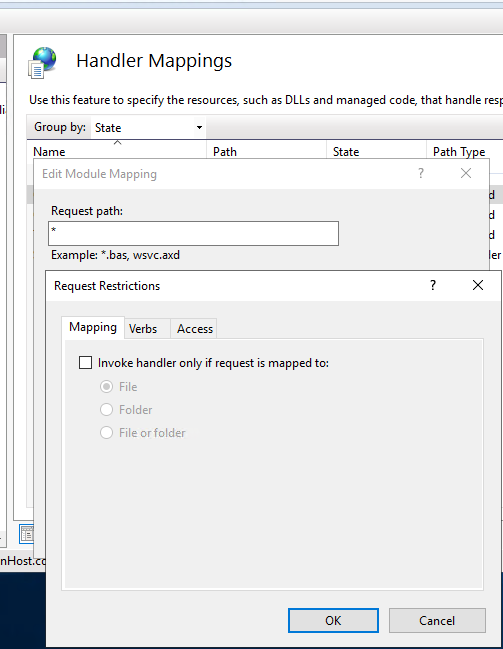
I might be barking up the wrong tree, but do you have your request restrictions for the module mapping in IIS set as you need?
I have found in the past that it defaults to only invoking the handler if mapping to a file which has then stopped things working for me:
The utility of Find In Files from Studio is one that is badly missed in VSCode, so I'm glad to see something in this space.
Is there an official recommendation from InterSystems regarding disabling content indexing for drives hosting database files (.dat), journals, and WIJ?
I'm fairly sure that the search indexing is disabled by default on Windows Server, so there's a good chance that it's not something that comes up frequently enough to make it into documentation as an official position.
However it does make sense to disable it for specific locations such as the location of the database and journals etc if you have indexing turned on for the server as a whole.
I will say that, this isn't possible everywhere.
Certainly in the UK (and I believe elsewhere in Europe) we don't have free SMS gateways via the carrier, which is why we then either look to paid services for the SMS or we use services such as Pushover.
Depending on the issue I'm seeing, I tend to rely on these two links to help pin down the issue:
€‚ƒ„…†‡ˆ‰Š‹ŒŽ‘’“”•–—˜™š›œžŸ.I'm pretty sure WDSUSPD is a flag to see if the write daemon is suspended, so that is also a good way to check.
Hey Malaya.
If you're not already getting the status code of 5 for successfully frozen and 3 for failure, then there is ##Class(Backup.General).IsWDSuspendedExt() that can be called to see if the Write Daemon is suspended, which follows that same output of either 5 or 3 depending on it's status.
Hey John.
I'm happy to be corrected, but I didn't think that the Arbiter utilised TLS and that the minimal traffic between the mirror and the arbiter was rather lacking in any information about the environments that are being managed by the arbiter.
That said, it would make sense for it to move to using TLS even just for completeness.
Hey Ashok.
I think there's a slight correction needed for your code snippet.
Specifically, for the line "do object.Organizations.GetAt(key).%DeleteId(key)" the DeleteId using the value of Key will not be the correct value to delete the intended object.
Should the code block instead be:
ClassMethod %OnDelete(oid As %ObjectIdentity) As %Status [ Private, ServerOnly = 1 ]
{
Set object = ..%Open(oid,,.status)
If $$$ISERR(status) Quit status
If $ISOBJECT(object.Organizations) {
Set org= object.OrganizationsGetSwizzled()
While org.GetNext(.key){
Set tID = object.Organizations.GetAt(key).%Id()
Do object.Organizations.GetAt(key).%DeleteId(tID)
}
}
Quit $$$OK
}Hey David.
I'll give XPath a try and see how I get on and update accordingly.
Edit:
It seems that trying to use xpath for the elements within the cdata block fail, and attempting to use xpath for <jkl> returns the content of the entire cdata as a stream object. However I think this is going to be a limitation of the xml I am working with rather than xpath itself.
Hey Julius, thank you for this.
Unfortunately, there is a risk of hitting the maxstring lengths due to one of the fields within the CData blocks will be a base64 encoded document or two. But this does look interesting for other use cases.
I'm glad it worked!
Hey Jainam.
I don't get a lot of hands on time with ASTM messaging but, from what you've shared, what you're receiving is using carriage returns.
The TCP Adapter does have a property of "Terminators" that is set to use ASCII Character 10 (line feed) for this, but this value is not configurable from the management portal (which is stated in the documentation)
I'm not sure if this is what you have tried where you stated "I've modified the class file", and I can't say for sure if this will work as I have no way to test it locally, but you could try creating a custom adapter which extends the in built adapter and overwrite the property, and then creating a custom service which extends the in built service and uses the custom adapter.
Something like:
Class Custom.EDI.ASTM.Adapter.TCPAdapter Extends EnsLib.EDI.ASTM.Adapter.TCPAdapter
{
/// Overwriting the original value of $C(10) (line feed) with $C(13) (carriage return)
Property Terminators As %String [ InitialExpression = {$C(13)} ];
}and
Class Custom.EDI.ASTM.Service.TCPService Extends EnsLib.EDI.ASTM.Service.TCPService
{
Parameter ADAPTER = "Custom.EDI.ASTM.Adapter.TCPAdapter";
}And finally, use the custom service in your production.
If this doesn't work, you might need to look into what your sending system is actually outputting for the carriage returns/line feeds.
Hey Joel.
Absolutely - there are a couple levels of ambiguity for the IDE without throwing a #dim in to know what that response object could be.
The biggest being that the target of the call of ..SendRequestSync/Async is something that can, and for good practice should, be configured within the Interoperability Production. Therefore the IDE has nothing to work from with regards to identifying what the response object will be to then provide code completion. Even if it's not configured within the Interoperability Production directly but a developer has simply declared the Target Dispatch Name as a string within the code, the link between that name and the target Class is still contained within the Production and could also not yet exist in the production at the time of development.
It's great to see the effort put into improving the Language Server which has massively reduced the need to use #dim, but I'm not we will see the last of it for some time.
I did post an example last year of how I traditionally would use #DIM, and it was (rightly) pointed out that the scenario was no longer required due to how VSCode behaves these days (well, the Language Server extension used in VSCode).
However today I have found a more common example where #DIM seems to be needed for code completion, based around using Business Services/Processes within an Interoperability Production.
Class Some.Business.Process Extends Ens.BusinessProcess
{
Property OnwardTarget As Ens.DataType.ConfigName;
Parameter SETTINGS = "OnwardTarget";
Method OnRequest(pRequest As Ens.Request, Output pResponse As Ens.Response) As %Status
{
//Some code above
Set someReqMsg = ##Class(Some.Req.Msg).%New()
Set someReqMsg.abc = "123"
Set tSC = ..SendRequestSync(..OnwardTarget,someReqMsg,.someRespMsg)
#; No autocomplete on someRespMsg.xyz without #dim before ..SendRequestSync
//Some code below
Quit $$$OK
}
}Without the #dim in the above, there is no context for the IDE to know what someRespMsg returned from the ..SendRequestSync() call will be.
That said, its use is certainly dwindling compared to pre-VSCode times and it's continued usage can be more from habit than necessity a lot of times (I'm certainly guilty of this).
.NET 6 and IRIS 2022.1.
As "w gw.invoke("System.Convert","ToBoolean(System.UInt64)",123)" also doesn't work for me, I have to assume there's an issue with my older versions.
Thanks again for your help!
Ahh, I see. So I was trying to call a static method as if it was a constructor. Thank you for showing me this!
Interestingly, if I try your examples, I can recreate the ambiguity error, but then get an error when attempting to specify the full param specification:
Method not found: System.Convert.ToBoolean(int)
However this + the reply from Enrico has got me on a good footing, so will try a few things and see where I land.
The linked samples are very helpful, thank you!