The linked samples are very helpful, thank you!
- Log in to post comments
The linked samples are very helpful, thank you!
This is really helpful to know. I think I have seen it not work like this in the past and picked it up as a habit, but can't say for sure.
To test this for myself, I have written out above pseudocode into real classes and found that the code completion doesn't kick in when attempting in the $$$TRACE, but does when attempting outside of the macro params:
I'll try get this logged via github later today assuming this isn't intended behaviour for the Language Server.
EDIT:
Logged here and I realise that my habit of using #Dim for Intellisense 100% comes from my historic use of Studio.
3. vscode connect failed.
It looks like your images failed to upload so it's not clear what (if any) errors you are getting when the connection failed.
Hey Scott.
The call to ##class(%SYS.OAuth2.AccessToken).IsAuthorized() will return the most recent active token (if available). So a token generated in a BS running every hour would be the same token returned when your BP makes a call to ##class(%SYS.OAuth2.AccessToken).IsAuthorized().
If you were to do this and still keep the code in the BP per your codeblock, you'd find that your BP would then almost never hit the condition of if 'isAuth unless the token happened to expire between the time of your next BS run and the BP attempting to use that token.
That all said, would it be much of a time save having the BS running the task every hour vs checking the validity of the token at the point of using it and then only reauthorising when it's no longer valid?
Hey Jonathan.
The utility function ..CurrentDateTime() should be returning a value that is based on the servers local timezone. As you're in EST, I'm guessing you're getting UTC/GMT. You might want to look at addressing this early and not code around it just yet as this could then be corrected at an OS level and you're suddenly subtracting 50000 from the correct result.
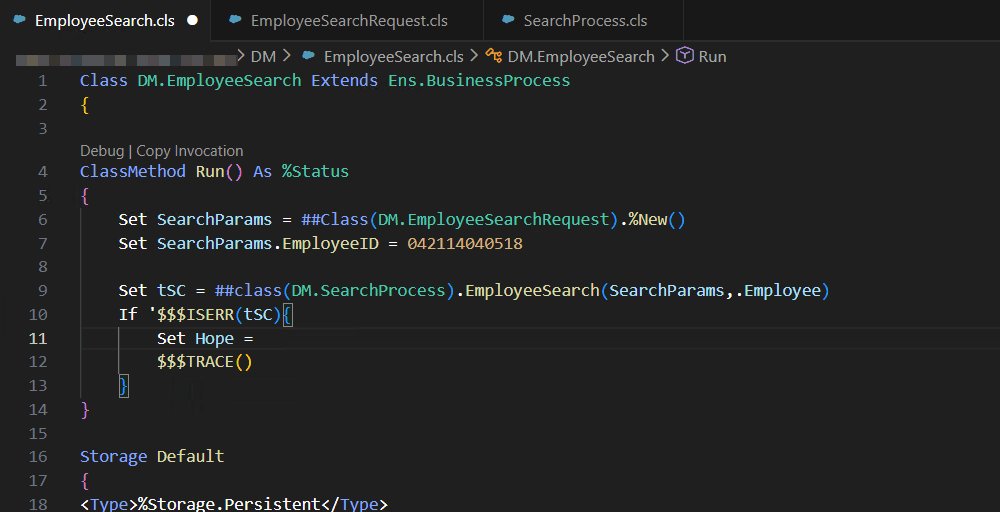
I tend to break up my usage between SET when an object is being created within the class, and using #DIM when working with responses from another ClassMethod. For example:
Set SearchParams = ##Class(DM.EmployeeSearch).%New()
Set SearchParams.EmployeeID = 042114040518
#DIM Employee As DM.Employee
Set tSC = ##class(DM.Employee).EmployeeSearch(SearchParams,.Employee)
If '$ISERROR(tSC){
$$$TRACE(Employee.Name) //Should return "Jim Halpert"
}
Additional question:
When using the EnsLib.File.PassthroughService, I seem to be seeing a lot of orphan Ens.StreamContainer entries.
By all accounts, the Ens.StreamContainer entries are being sent from a service and process and does gain an entry in the Ens.MessageHeader table on creation.
When attempting to manually delete these Ens.StreamContainer entries, I do get an error:
SQLCODE: <-412>:<General stream error>]
[%msg: <Error attempting to delete stream object for field StreamFC: ERROR #5019: Cannot delete file '\\original\path\to\file.here'>]I'm assuming that this is due to the behaviour of the EnsLib.File.PassthroughService where it deletes the file once processed, and the delete of the Ens.StreamContainer is then attempting to remove a file that no longer exists, however the Ens.MessageHeader entry is then successfully deleted, creating the orphan.
Should this be the case?
Edit: This does not seem to be directly limited to EnsLib.File.PassthroughService as it is also present with the EnsLib.HL7.Service.FileService Service.
Thanks Jeffrey - it's certainly highlighted some hidden pockets of orphaned messages for me. I'm going to track this in a separate thread, but basically it seems there's a few edge cases where ACKs are being saved and don't end up in the IO log and don't get an entry in the Message Header table.
Based on this, is it fair to assume that the following alteration to the SQL query in Scott's above post would give a truer reflection of orphaned messages?
SELECT HL7.ID,HL7.DocType,HL7.Envelope,HL7.Identifier,HL7.MessageTypeCategory,HL7.Name,HL7.OriginalDocId,HL7.ParentId, HL7.TimeCreated
FROM EnsLib_HL7.Message HL7
LEFT JOIN Ens.MessageHeader hdr
ON HL7.Id=hdr.MessageBodyId
LEFT JOIN Ens_Util.IOLogObj ack
ON HL7.Id = ack.InObjectId
WHERE hdr.MessageBodyId IS NULL AND ack.InObjectId IS NULLIf you're looking to simply convert timezone codes to the UTC offset, I'd setup a simple utility that returns the desired string based on a case statement.
Something like:
ClassMethod DisplayTimezoneToUTCOffset(pInput as %String) As %String{
Quit $CASE($ZCONVERT(pInput,"U"),
"CEST":"+02:00",
"CET":"+01:00",
"BST":"+01:00",
:"")
}If you then want to build the entire string, you could do similar to above for the months, and then have the following:
Class Demo.Utils.ExampleUtils.TimeConvert
{
ClassMethod DisplayDateTimeToLiteral(pInput as %String) As %String{
// Deconstruct the input string into it's logical parts.
// Variables starting d are "display" values that will be converted later.
Set DayOfWeek = $P(pInput," ",1) //Not used
Set dMonth = $P(pInput," ",2)
Set Day = $P(pInput," ",3)
Set Time = $P(pInput," ",4)
Set dTimeZone = $P(pInput," ",5)
Set Year = $P(pInput," ",6)
//Return final timestamp
Quit Year_"-"_..DisplayMonthToLiteral(dMonth)_"-"_Day_" "_Time_..DisplayTimezoneToUTCOffset(dTimeZone)
}
ClassMethod DisplayTimezoneToUTCOffset(pInput as %String) As %String{
Quit $CASE($ZCONVERT(pInput,"U"),
"CEST":"+02:00",
"CET":"+01:00",
"BST":"+01:00",
:"")
}
ClassMethod DisplayMonthToLiteral(pInput as %String) As %String{
Quit $CASE($ZCONVERT(pInput,"U"),
"JAN":"01",
"FEB":"02",
"MAR":"03",
//etc. etc.
"JUL":"07",
:"")
}
}
Which then gives the following:
.png)
Hi Nezla.
As the URL starts out as "ac1.mqtt.sx3ac.com", suggesting that the API is using MQTT, is the %net.httprequest adapter the right way to go?
I think it'd be good to take a look at Using the MQTT Adapters to see how the adapter can be used if you haven't already.
Have you tried adding backticks to your double-quotes to escape them?
PS C:\Users\Colin\Desktop> irissession healthconnect -U user 'Say^ImplUtil(`"Your String Here`")'Hey everyone!
It is technically possible, but you are somewhat limited by your receiving endpoints capability to receive these in batch.
It relies on the use of FHS (File Header) and BHS (Batch Header) segments at the start of your batch message, and then all of the content you wish to send in that batch, finalised with BTS (Batch Trailer) and FTS (File Trailer)
You may want to look first at how IRIS will display a batch message within the system here and look here as to how you can work with them. But I do want to stress again that you will want to ensure first and foremost that the system you want to send this to can actually support it so that you don't lose time to building a solution using this method only to find it will never work.
Out of interest:
It's slightly dependant on the HL7 Version and Message Type, but assuming you're working with ORM_O01 messages using HL7 V2.3, you have a few options:
Example 1, Multiple Ifs, one for each variation (I only did 2 in the screenshot to save time) :.png)
Example 2, If/Else where we assume that we only want "I" in OBR:18 when PV1:2 is "I", and otherwise set to "O":
.png)
Example 3, use the $CASE function:
.png)
All of these can be combined with the response you just got here HL7 DTL formatting | InterSystems Developer Community | Business Process for the same question, assuming you want to put them into a subtransform, but I'd start with what I have shared here first, and venture into subtransforms and auxiliary-based configs after you get this nailed down.
To give an example of where I have done something similar:
I have a Service that will check if the active mirror has changed since the last poll, and will trigger a message to the "Ens.Alert" component in the production if it has changed.
To do this, I have a service with the following code:
Class Demo.Monitoring.SystemMonitor Extends Ens.BusinessService
{
Method OnProcessInput(pInput As %RegisteredObject, Output pOutput As %RegisteredObject, ByRef pHint As %String) As %Status
{
Set tsc = ..CheckMirroring()
Quit tsc
}
Method CheckMirroring() As %Status
{
Set triggered = 0
//Get the current server
Set CurrServer = $PIECE($SYSTEM,":")
/**Check Global exists, and create it if it does not.(Should really only ever happen once on deployment, but this is a failsafe)**/
Set GBLCHK = $DATA(^$GLOBAL("^zMirrorName"))
If GBLCHK = 0{
Set ^zMirrorName = CurrServer
Quit $$$OK //No need to evaluate on first run
}
If ^zMirrorName = CurrServer {
/*Do not Alert*/
Quit $$$OK
}
Else {
/*Alert*/
Set AlertMessage = "The currently active server has changed since the last check, suggesting a mirror fail over."
Set AlertMessage = AlertMessage_" The previous server was "_^zMirrorName_" and the current server is "_CurrServer_"."
Set ^zMirrorName = CurrServer
Set req=##class(Ens.AlertRequest).%New()
Set req.SourceConfigName = "System Monitor"
Set req.AlertText = AlertMessage
Set req.AlertTime = $ZDATETIME($HOROLOG,3)_".000"
Set tSC = ..SendRequestSync("Ens.Alert", req)
Quit tSC
}
}
}Then, from within my production, I then have the service that is using this class configured with "CallInterval" set to the desired frequency of running:
.png)
Hey Lukasz.
Do you not get this option after selecting the namespace?.png)
Assuming you are iterating though the OBX's, you can simply add a variable where you increment it for each OBX you are processing.
Assuming your code is still similar to your code from your other account, you should have an incrementing variable of i.
Try sticking in
Do pOutput.SetValueAt(i,"ORCgrp(1).OBRuniongrp.OBXgrp("_i_").OBX:4")Setup 2 is my preferrable option for a few reasons:
So in effect, I would suggest something like:
.png)
Any common transforms you need to apply can then go in at the System A router (for example, I had a system with a bug in the outputs we would get, so worked around it once earlier in the flow rather than trying to fix it in every transform for the downstream systems).
Beyond that, I'd recommend the routing rules in the System A router is minimal but still apply a base level of filtering based on the message types the downstream routers will be receiving. There no point sending System D A04 messages if that router then will never process them. However, if System D will receive A08's when PV1:2 is "E", I'd allow all A08's from System A's Router to go to System D's router, and then do the explicit check for A08's when PV1:2 is "E" from within the rules of System D's Router.
Perfect, thank you Ashok.
Hey Colin.
I had a few minutes before a meeting so wanted to try recreate on IRIS instead of Cache and happened to have not yet restarted VSCode so didn't have the new extension versions installed.
I was able to run the example you tried in the old extension versions and observed no errors in the output for the language server, ran my updates, and then lost the ability to select the Language Server from the Output selection dropdown:
.png)
I would have liked to been able to completely recreate this in the new version, or at least give some indication of where the fault may be. But not being able to see the Output window for the language server like in your screenshot stops me in my tracks 😅
Hey Gary.
I know that this has been mentioned before, but actual line breaks in the HL7 like this will likely causes issues with the parsing of the HL7 message in your receiving system.
I believe your goal should either be (see line 35):
.png)
(but maybe swapping out "/.br/" with "\X0D\\X0A\" depending on the receiving system per Jeffrey Drumm's comment here)
Or (see line 21)
.png)
Good spot - I got so distracted by the %ConstructClone not being called with deep=1 that I didn't even notice that they were then still working from their pRequest variable.
Also, from a HL7 perspective, trying to add line breaks between your first and second OBX lines may not translate as you're expecting. Any receiving system trying to parse the HL7 will either ignore the break or will see it as malformed HL7.
Assuming that whatever system is receiving the HL7 is producing an output from the OBX:5 values, then you'll want to try adding in a new line and leave the OBX.5 blank, or if your receiving system supports line breaks, then this would usually be with adding a "/.br/" to the end of the OBX.5 in your first OBX (some systems may expect a different value to represent a line break, so your milage may vary).
Finally, as a general point, I would personally move this into a DTL. If there are actions going on in an ObjectScript Business Process leading up to the need to manipulate the message, then you can call the DTL from within your ObjectScript rather easily.
%ConstructClone() has a property of "deep" that is defaulted to 0, and it controls whether or not the new copy is a complete copy of the source, or if it merely copies the top level of the source object and then creates references to any sub objects contained within the source object. See more here.
My guess (without testing) is that the EnsLib.HL7.Message at a top level is being cloned with your code, but deep being false means that it's then still referencing the original EnsLib.HL7.Segment objects contained within the source EnsLib.HL7.Message object.
In your case, try changing to:
Set pOutput = pRequest.%ConstructClone(1)Hey John.
I know it's not a direct answer to what you're looking to do, but we ended up writing a nodeJS app that acts an API that we pass HTML to and it returns a PDF, and we then have an Operation we call this API with.
Hey Thembelani.
You have a few options you can go for depending on what formats you are attempting to convert from.
You could look at something like using pandoc via the command line (as in, building an operation that does the command line calling, and then creating a set of request/response classes to call from a Process in your IRIS instance), or with with Python becoming more popular in IRIS, you could look what packages are available for doing what you're looking to do.
You could also look at libreoffice from the command line, but I found that headless libreoffice was a fair bit slower when running on Windows vs linux, so you may not get a lot of use with this approach depending on what you're running on.
What environment did you run the installer on?
If Windows, did you have IIS enabled before running the installer?
I had some oddities when attempting to install a version that no longer includes the PWS (including a few self inflicted), and found that the best method was to: