tFullValue should be always equal to tNumber regardless of tNumber value.
write $l(2.1)
>3- Log in to post comments
tFullValue should be always equal to tNumber regardless of tNumber value.
write $l(2.1)
>3I'm curious about this
set tFullValue = $EXTRACT(tNumber,1,$length(tNumber))in what cases tFullValue is not equal to tNumber?
Also after 2014 you can use * to denote last char like this:
set tFullValue = $EXTRACT(tNumber,1,*)Do you want the data to be accessible by anyone who can view the page?
It should:
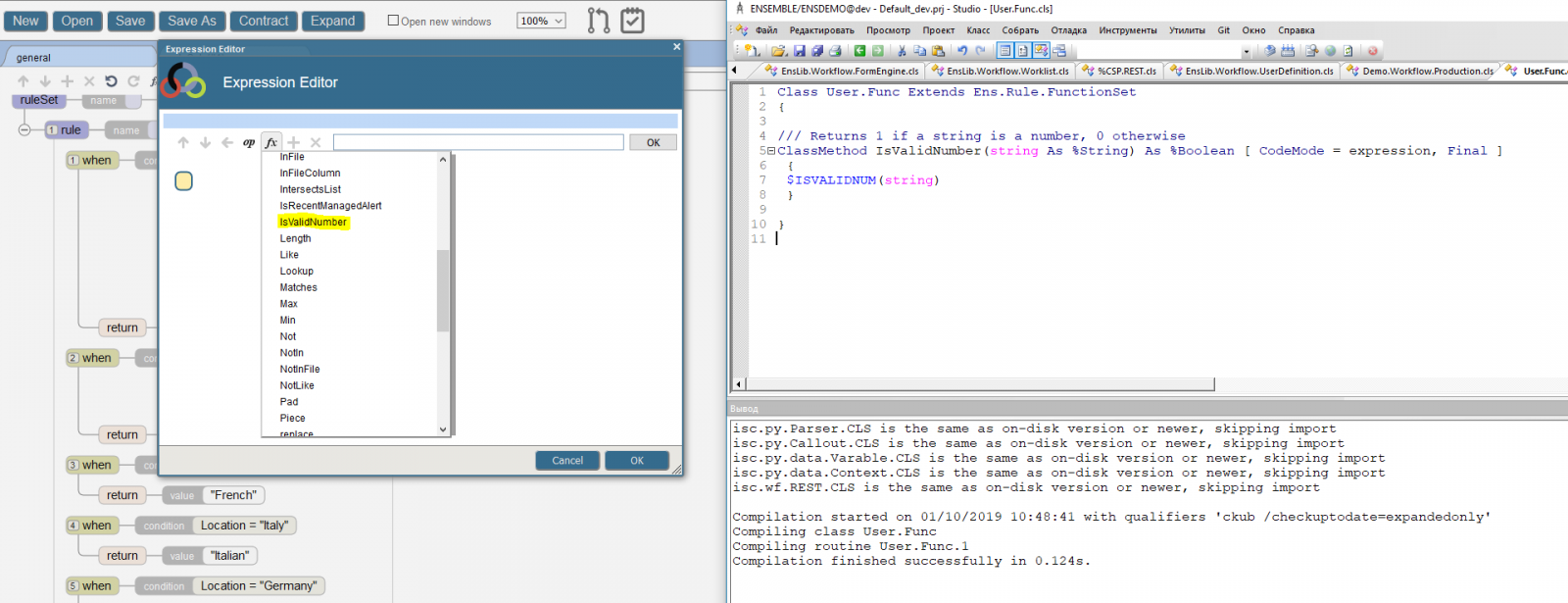
There's no default function to do it, but you can easily develop your own custom function. There's $IsValidNum ObjectScript function, which could be used to check that variable is a number. So something like this should work:
/// Functions to use in rule definitions.
Class Custom.Functions Extends Ens.Rule.FunctionSet
{
/// Returns 1 if a string is a number, 0 otherwise
ClassMethod IsValidNumber(string As %String) As %Boolean [ CodeMode = expression, Final ]
{
$ISVALIDNUM(string)
}
}SendRequestAsync is available in all Ensemble Hosts (Services, Operations, Processes).
For Operations and Services the signature is:
Method SendRequestAsync(pTargetDispatchName As %String, pRequest As %Library.Persistent, pDescription As %String = "") As %StatusAnd for Processes the signature is:
Method SendRequestAsync(pTargetDispatchName As %String, pRequest As Request, pResponseRequired As %Boolean = 1, pCompletionKey As %String = "", pDescription As %String = "") As %StatusThank you for the info!
All possible job states (from EnsConstrains.inc):
JGW (and therefore JBH) could be run as a separate container with TCP/IP interaction.
In the future please don't combine separate questions into one post.
I am looking for a way to detimerine if a certain namespace is ensemble enabled.
To check that some <namespace> has Ensemble enabled call:
write ##class(%EnsembleMgr).IsEnsembleNamespace(<namespace>)
where <namespace> defaults to current namespace.
Log some information to the console log file with a certain error level.
%SYS.System class provides the WriteToConsoleLog method, which you can use to write to the cconsole.log file.
Use %Stream.GlobalBinary to pass streams without saving them on disk. Also use Ens.StreamContainer as an interoperability message class.
If you used %Stream.TmpBinary class to hold your stream, it would not be saved.
If you have SSL config named, say, "AWS" try to set SMTP SSLConfiguration setting to "AWS*" (with asterisk on end). It can help.
Click "Visual Trace" link to view details.
In your case there's 403 error, so you're not authenticated.
Check this topic for AWS authorization options.
- If I have a global available in a certain namespace, can I use InterSystems SQL to query those globals?
- How do existing globals and creating classes work? Like I have a Person global right now. Can I turn that into a class and manipulate the data that way?
You'll need class mapping to query globals via SQL. Check article series The Art of Mapping Globals to Classes by @Brendan.Bannon.
- I'm used to Java where you can write a class and then write a driver class to test your classes and methods. Or simply just test your newly created classes and methods in the main method (wherever that lies in your code). Is there something similar in Studio? I can write classes but then they are compiled and I have to go to the terminal and test them? Is this where routines come into play in Studio?
You can configure Studio or Atelier debugger to run any class method. There's no need to use routines for that.
What do you want to do with that?
Wouldn't $data over local be more effective?
Thank you, that's exactly what I'm looking for.
The input pattern is not constant, it's just an example.
I'd rather avoid parsing my input pattern and translating it into Cache pattern.
For simple communication you can use Cache Event API.
To distribute work, there's a number of options, discussed here.
Thanks for the info, Fabian.
I myself am a fan of Ubuntu structure, do you know how to get that automatically on other OSes, primarily CentOS?
While spawning a process on Windows can be (and usually is) costly, linux offers better performance in that regard.
Additionally ImageMagick offers two C APIs: High-level and Low-Level they could be used to write a callout library, which would likely offer the best performance.
I used imagemagick to do something similar and called it via $zf(-100).
Great game!
Does not work, as object with that ID does not exist
zw ##class(OPNLib.Game.ConwayLifeGame).Test()
These are the settings for the test:
{"ID":1,"From":0,"To":200,"Iterations":200,"InitialConfig":5,"Rows":80,"Columns":150,"Vector0":"1,1","VectorN":"100,40"}
Press any key to continue... (Ctrl-C to stop)"0 "_$lb($lb(5002,"zCreateFromStatus+8^%Exception.StatusException.1 *tInfo(1,""code"")",,,,,,,,$lb(,"USER",$lb("^zCreateFromStatus+8^%Exception.StatusException.1^1","e^zThrowIfInterrupt+7^%Exception.StatusException.1^1","e^zTest+12^OPNLib.Game.ConwayLifeGame.1^2","e^^^0"))))/* ERROR #5002: Cache error: zCreateFromStatus+8^%Exception.StatusException.1 *tInfo(1,"code") [zTest+12^OPNLib.Game.ConwayLifeGame.1:USER] */ I added this code after read and it works:
If ..%ExistsId(pTest.ID) {
set g = ##class(OPNLib.Game.ConwayLifeGame).%OpenId(pTest.ID)
} else {
set g = ##class(OPNLib.Game.ConwayLifeGame).%New()
}Set Reply Code Action for email business operation.
Check Dir method of %Net.SSH.SFTP class, it returns directory contents, including sub-directories.
If you're using InterSystems IRIS try this connection string (replacing values with appropriate):
"Driver=InterSystems ODBC Driver;Host=127.0.0.1;Port=56772;Database=USER;UID=myUsername;PWD="
and for Caché/Ensemble try (driver name could be InterSystems ODBC):
"Driver=Cache ODBC Driver;Host=127.0.0.1;Port=1972;Database=USER;UID=myUsername;PWD="
If the problem persist, check Audit log.
Thank you, Dmitry, I used Process Monitor to get relevant error:

Turns out dependent DLLs should be in bin folder or current folder, but not in callout library folder.
when you get the error <DYNAMIC LIBRARY LOAD>, you should look at cconsole.log (or messages.log for IRIS), where you may find code of error.
Thank you. Got this error
Error loading dll (c:\users\eduard\eclipse-c-workspace\helloworld\debuglib\libhelloworld.dll) is 126It is possible that you build it for 32bit, but uses in 64bit instance. In this case, you will get the error with code 139. if you got other code, you can google it.
I can get it to work if I compile it without a few lines, so I'm sure it's 64bit.
Installers can be used to do that.