Writing better-performing loops in Caché ObjectScript
The topic of for/while loop performance in Caché ObjectScript came up in discussion recently, and I'd like to share some thoughts/best practices with the rest of the community. While this is a basic topic in itself, it's easy to overlook the performance implications of otherwise-reasonable approaches. In short, loops iterating over $ListBuild lists with $ListNext or over a local array with $Order are the fastest options.
As a motivating example, we will consider looping over the pieces of a comma-delimited string.
A natural way to write such a loop, in minimal code, is:
For i=1:1:$Length(string,",") {
Set piece = $Piece(string,",",i)
//Do something with piece...
}
This is straightforward, although many coding style guidelines might suggest:
Set n = $Length(string,",")
For i=1:1:n {
Set piece = $Piece(string,",",i)
//Do something with piece...
}
There isn't actually a performance difference between the two, since the end condition is not evaluated for each iteration. (I originally had this wrong - thanks to Mark for pointing out that it's just a style concern and not a performance issue.)
For the case of a delimited string, we can achieve better performance. As the string gets longer, $Piece(string,",",i) becomes more expensive: it must walk the string up to the end of the ith piece. This can be improved by using $ListBuild lists. For example, using $ListFromString, $ListLength, and $List:
Set list = $ListFromString(string,",")
Set n = $ListLength(list)
For i=1:1:n {
Set piece = $List(list,i)
//Do something with piece...
}
This will typically perform better than $Length/$Piece, particularly when the pieces are longer. In the $Length/$Piece approach, each of the n iterations scans the characters in the first i pieces. In the $ListFromString/$ListLength/$List approach, it now follows i pointers in the $ListBuild structure for each of the n iterations. We would expect this to perform better, and it does, but the execution time is still O(n2). Assuming that the loop will not change the list, we can do better - O(n) - by using $ListNext:
Set list = $ListFromString(string,",")
Set pointer = 0
While $ListNext(list,pointer,piece) {
//Do something with piece...
}
Rather than following pointers through the list from the beginning to the ith piece each time like $List does, the variable “pointer” keeps track of the current position in the list. Therefore, instead of n(n+1)/2 total “follow the pointer” operations (i in each of the n iterations for $List), there are now just n of them (one in each iteration for $ListNext).
Finally, converting the string's pieces to array with integer subscripts may be a good option; in general, iterating over a local array with $Order may be slightly to significantly faster than $ListNext (depending on the length of the list elements). Of course, if you're starting out with a delimited string, it'll take a bit of work to convert it into an array. If you're iterating repeatedly, need to modify the parts of the list, or need to iterate backwards, this additional work would likely be worth it.
Here are some sample execution times (including all required conversions) for some different input sizes:
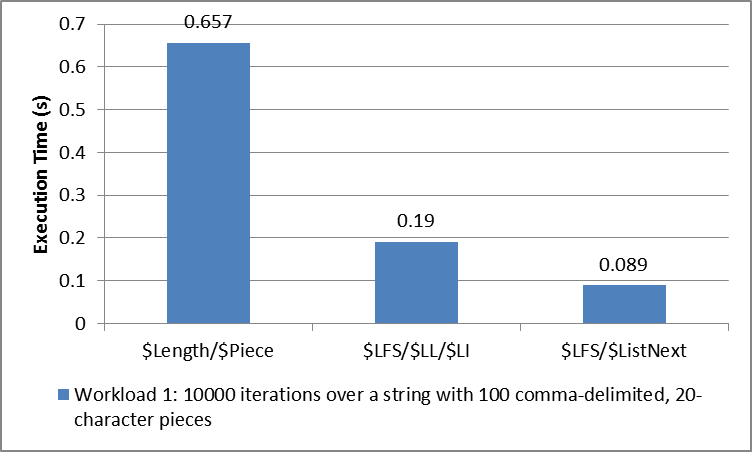

These numbers came from:
USER>d ##class(DC.LoopPerformance).Run(10000,20,100) Iterating 10000 times over all the pieces of a string with 100 ,-delimited pieces of length 20: Using $Length/$Piece (hardcoded delimiter): .657383 seconds Using $Length/$Piece: 1.083932 seconds Using $ListFromString/$ListLength/$List (hardcoded delimiter): .189867 seconds Using $ListFromString/$ListLength/$List: .189938 seconds Using $ListFromString/$ListNext (hardcoded delimiter): .089618 seconds Using $ListFromString/$ListNext: .089242 seconds Using $Order over an equivalent local array with integer subscripts: .072485 seconds **************************************************** Using $ListFromString/$ListNext (not including conversion to $ListBuild list): .058329 seconds Using one-argument $Order over an equivalent local array with integer subscripts: .060327 seconds Using three-argument $Order over an equivalent local array with integer subscripts: .069508 seconds USER>d ##class(DC.LoopPerformance).Run(2,1000,2000) Iterating 2 times over all the pieces of a string with 2000 ,-delimited pieces of length 1000: Using $Length/$Piece (hardcoded delimiter): 3.372927 seconds Using $Length/$Piece: 11.739316 seconds Using $ListFromString/$ListLength/$List (hardcoded delimiter): 1.004757 seconds Using $ListFromString/$ListLength/$List: .997821 seconds Using $ListFromString/$ListNext (hardcoded delimiter): .010489 seconds Using $ListFromString/$ListNext: .010268 seconds Using $Order over an equivalent local array with integer subscripts: .000839 seconds **************************************************** Using $ListFromString/$ListNext (not including conversion to $ListBuild list): .003053 seconds Using one-argument $Order over an equivalent local array with integer subscripts: .000938 seconds Using three-argument $Order over an equivalent local array with integer subscripts: .000677 seconds
View the code (DC.LoopPerformance) on Gist
Update:
The discussion has turned up a few other interesting variations with good performance, which are worth comparing to each other. See the RunLinearOnly method and the different implementations tested in the updated Gist.
USER>d ##class(DC.LoopPerformance).RunLinearOnly(100000,20,100) Iterating 100000 times over all the pieces of a string with 100 ,-delimited pieces of length 20: Using $ListFromString/$ListNext (While): .781055 seconds Using $ListFromString/$ListNext (For/Quit): .8438 seconds Using $ListFromString/$ListNext (While, not including conversion to $ListBuild list): .37448 seconds Using $Find/$Extract (Do...While): .675877 seconds Using $Find/$Extract (For/Quit): .746064 seconds Using one-argument $Order (For): .589697 seconds Using one-argument $Order (While): .570996 seconds Using three-argument $Order (For): .688088 seconds Using three-argument $Order (While): .617205 seconds USER>d ##class(DC.LoopPerformance).RunLinearOnly(200,2000,1000) Iterating 200 times over all the pieces of a string with 1000 ,-delimited pieces of length 2000: Using $ListFromString/$ListNext (While): .913844 seconds Using $ListFromString/$ListNext (For/Quit): .925076 seconds Using $ListFromString/$ListNext (While, not including conversion to $ListBuild list): .21842 seconds Using $Find/$Extract (Do...While): .572115 seconds Using $Find/$Extract (For/Quit): .610531 seconds Using one-argument $Order (For): .044251 seconds Using one-argument $Order (While): .04467 seconds Using three-argument $Order (For): .043631 seconds Using three-argument $Order (While): .042568 seconds
The following chart compares the While/Do...While versions of these methods. Particularly, see the relative performance of $ListFromString/$ListNext compared to $Extract/$Find, and of $ListNext (without conversion from string to $ListBuild list) compared to $Order over a local array with integer subscripts.

In summary:
- If you're starting with a delimited string, $Find/$Extract is the best-performing option, although the code is slightly less intuitive than $ListFromString/$ListNext.
- Given a choice of data structures, traversal of $ListBuild lists seems to have a slight performance edge over an equivalent local array for small inputs, while the local array offers significantly better performance for larger inputs. I'm not sure why there's such a huge difference in performance. (Relatedly, it would be worth comparing the cost of random inserts and removals in a $ListBuild list vs. a local array with integer subscripts; I suspect that set $list would be much faster than shifting the values in such an array.)
- A While or Do...While loop performs slightly better than an equivalent argumentless For loop.
Comments
than
I fully agree with hoisting constants out of a loop and have recently spent a while optimizing code to use $listnext in SQL and so agree it is a much faster way to iterate over $listbuild structures.
However in your first case of a 'For' loop the end condition is evaluated when entering the loop the first time and is not re-evaluated at all, for example run this:
CACHE20164:USER>set a=2 for i=1:1:a { set a=10 write i,! }
1
2As you can see it always stops at '2' rather than going on to '10'.
Also there is overhead in converting from a delimited string into a $list format in order to use the more efficient $listnext, you can avoid the O(n^2) overhead with the regular $piece(string,",",i) code in a loop using $find with a starting position and then $extract the item you need. This should perform better than $listnext version of the loop at least for mid sized strings as it avoids the conversion overhead.
Graphs (and measurements in a method) include conversion times.
>$find
I tried this:
$$$START("Using $find (hardcoded delimiter): ")
For i=1:1:pIterations {
Set tPosition = 0
Do {
Set tNewPosition = $Find(tString,",",tPosition)
Set tValue = $Select(tNewPosition'=0:$Extract(tString,tPosition,tNewPosition-2),1:$Extract(tString,tPosition,*))
Set tPosition = tNewPosition
} While tPosition '= 0
}
$$$ENDIt was slow. Is there any way to write this faster - eg. without select (or other condition for the last piece)?
Eduard, that actually does run faster for me than the $ListFromString/$ListNext approach (with the conversion included). Not including the conversion, $ListNext is still faster. (I've updated the Gist to include that example.)
Tried it again, got the same results as you. $find performs better on both short (20 chars per piece, 100 pieces) and long strings (2000 chars per piece, 100 pieces).
Ed, what macros $$$START and $$$END do?
They track execution time:
#define START(%msg) Write %msg Set start = $zh #define END Write ($zh - start)," seconds",!
Thank you for pointing out both of those things!
I'm not sure why I thought the end condition was evaluated each time. I'll update the post to avoid spreading misinformation.
Wow. Just wanted to say a great topic guys! Thank you
One more optimisation. This:
Set list = $ListFromString(string,",")
Set pointer = 0
While $ListNext(list,pointer,piece)
{ //Do something with piece...
}Can be changed to:
Set list = $ListFromString(string,",")
Set pointer = 0
For {
quit:'$ListNext(list,pointer,piece)
//Do something with piece...
}Which is faster, as 'for' is generally faster than 'while'.
Took from Russian Caché forum
Nice. I'll add a section comparing the O(n) variations this week.
FYI: I get consistently slower performance with the 'for' loop variation here (around 10% slower) so at least in my simple test the while loop both looks nicer and runs faster.
Thank you, Mark, good to know.
$ListNext is generally faster, however for production code the following pattern should be used:
set pointer = 0
while ($listnext(list,pointer,listpart)) {
continue:($data(listpart)=0)
#; listpart is valid
}
This correctly deals with a trailing comma in the list, e.g.
set list = $listbuild(1,2,3,)
If this is fed to $listnext then listpiece will be undefined for the last iteration
This is interesting stuff and it's good to revisit this as ObjectScript evolves. In the old days, there was advice about things like this:
- set a=1, b=1, c=1 was faster than set (a, b, c) =1
- if a]"" was faster than if a'=""
- etc.
But we always reminded people that these things could change from platform to platform, and that extra database references were usually much costlier than the differences between coding things one way vs another.
So, Tim, if you've got the time, please tell the Community if your tests show different values on Windows vs Linux vs Unix vs OS X. And (this might be harder), give us your opinion on a "tipping point" or a "when to care about this point"; that is, if the delimited or list string has fewer than N pieces/items, it really doesn't matter which method is used, but above N, use the $listlength method, and above M, use $listnext. Something like that.
I think only profiler for the exact case can really answer this kind of questions. Too many nuances in the real-life code for one-fits-all solution of any kind to be feasible.
Hey InterSystems compiler developers, why not introduce a foreach statement that compiles to the "usual best performance" approach. That way developers don't need to know about these performance tricks for day to day work. If a developer wants to squeeze the last drop of performance out of their code they can still refer to articles like this and override the behaviour, but at least if they use foreach by default they won't choose the worst performing case. Foreach would be used as:
foreach(",") piece in string {
// Do something with piece
}
Further, if the relative performance of different approaches changes with version updates or is different across different platforms, the use of foreach would also remove the need for any source code changes on the part of the developer.
Just an idea
Duncan
Maybe some $$$ForEach macro would be helpful here?
Really nice topic! Thank you.
 The article is considered as InterSystems Data Platform Best Practice.
The article is considered as InterSystems Data Platform Best Practice.
This article helped me so much !