$lb vs $c for byte array
Dear community!
I'm currently working on MessagePack implementation by using Cache ObjectScript.
I try to choose suitable representation for binary array.
Should I use $lb or $c or smth else for it?
Comments
To elaborate a bit: we are currently discussing two approaches on how to store intermediary representations of Messagepack message.
One of approaches is to store message as $lb(code1, code2, ... ,codeN) so that each character in message is stored as a corresponding code in $lb.
Other approach is to store as is in strings, so it would look like: $c(166) _ "Fringe".
Let's say we want to encode string "Fringe", it would look like this:
- $listbuild(166, 70, 114, 105, 110, 103, 101)
- $c(166) _ "Fringe"
I maintain that approach ASIS (with $c) is better as it gives less overhead than $lb.
There is no option to directly read 166, 70, 114... in Caché, only reading symbols and getting their codes from $ascii. So there would be a considerable overhead on conversion to and from $lb abstraction.
What do you mean by overhead from $lb?
What is $c(166), some magic number? And why you encode the string as a list of codes, why not keep it as a string?
$lb it is also a string, but compressed for some types of values.
What do you mean by overhead from $lb?
I mean overhead from
- Converting string to/from $lb
- Converting each char to/from number
What is $c(166), some magic number?
Essentially. 166(dec) = 10100110(bin), where 101 means fixstr datatype (stores a byte array whose length is upto 31 bytes) and 00110(dec) = 6(dec) which is the length of the string.
And why you encode the string as a list of codes, why not keep it as a string?
@Maks Atygaev as an advocate of that approach can clarify his position.
so $lb($$$FIXSTR,text) since $L(text) is included there anyhow
and $$$FIXSTR tells you that it's < 32
why not $lb(166,"Fringe") ?
I'd suggest to use $LB() if you are not hit by the LongString limit.
why: all packaging, selection,.... is already done and "hard wired" in C++
with $C() you may re-invent $LB() or $Piece() or similar. And you have to do it in COS.
Same applies to local array where you may iterate over the structure in COS again.
Nothing against COS but C++ (in COS Functions) IS faster
My point starts from here.
MsgPack is a binary format of data representation.
How we can see on its specification (second link) MsgPack defines serialization/deserialization from common data types and structures into byte array.
I just want to implement the format as is.
When we see on serialization of string then we see that it looks like that:
| code (one byte) | length representation (1 or 2 or 4 bytes) | string bytes |
or for small strings:
| (code + length of string) (one byte) | string bytes |
For example for string "Fringe":
| 166 | 70 114 105 110 103 101 |
I would add support for both strings and streams, similar to what we have for other interchange formats (XML, JSON etc). This is pretty much what their reference implementation on the website does as well. Since this is a binary format, you need to be careful with character encoding.
After all details, it means, that no reasons to use $lb, or any other ways, it should be as is as a string, but with this length's header.
In Cache, we don't have binary strings as do other languages, but what is a byte, it is a symbol for text, so text will be arrays of bytes.
write $c(166, 70, 114, 105, 110, 103, 101) ¦Fringe
The only thing you should care as already mentioned above is different codepages.
Let's try for some example:
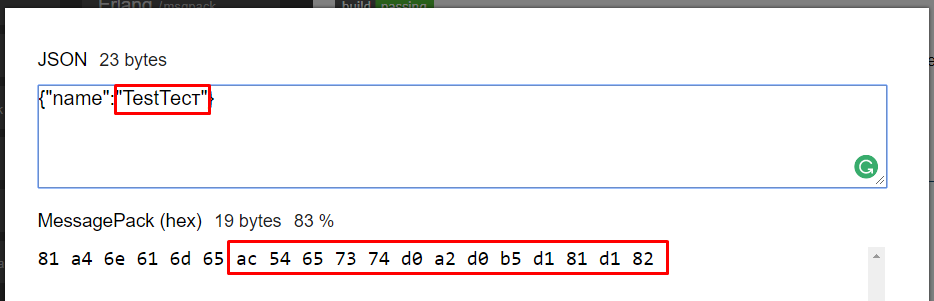
And try to get the same.
USER>set data="TestТест" USER>zzdump data 0000: 0054 0065 0073 0074 0422 0435 0441 0442 TestТест USER>set msg=$zcvt(data,"O","UTF8") ; convert from Unicode USER>set msg=$c(160+$l(msg))_msg ; of course should be changed for bigger text USER>zzdump msg 0000: AC 54 65 73 74 D0 A2 D0 B5 D1 81 D1 82 ¬TestТеÑ.Ñ.
and as you can see we got the same result