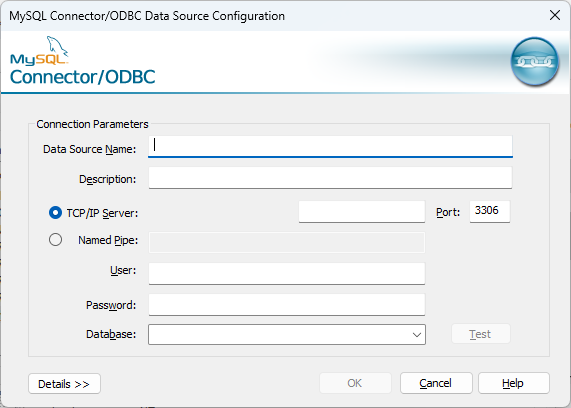
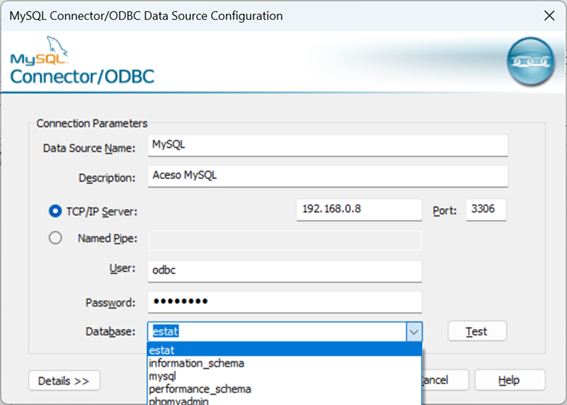
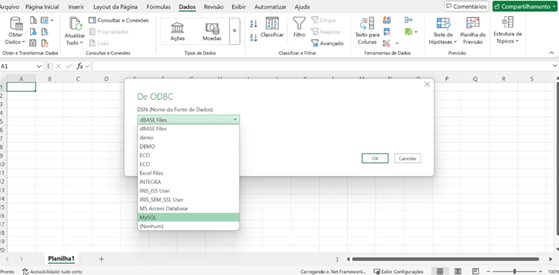
Utilizando o Gateway SQL com Python, Vector Search e Interoperabilidade no InterSystems Iris
Parte 3 – REST e Interoperabilidade
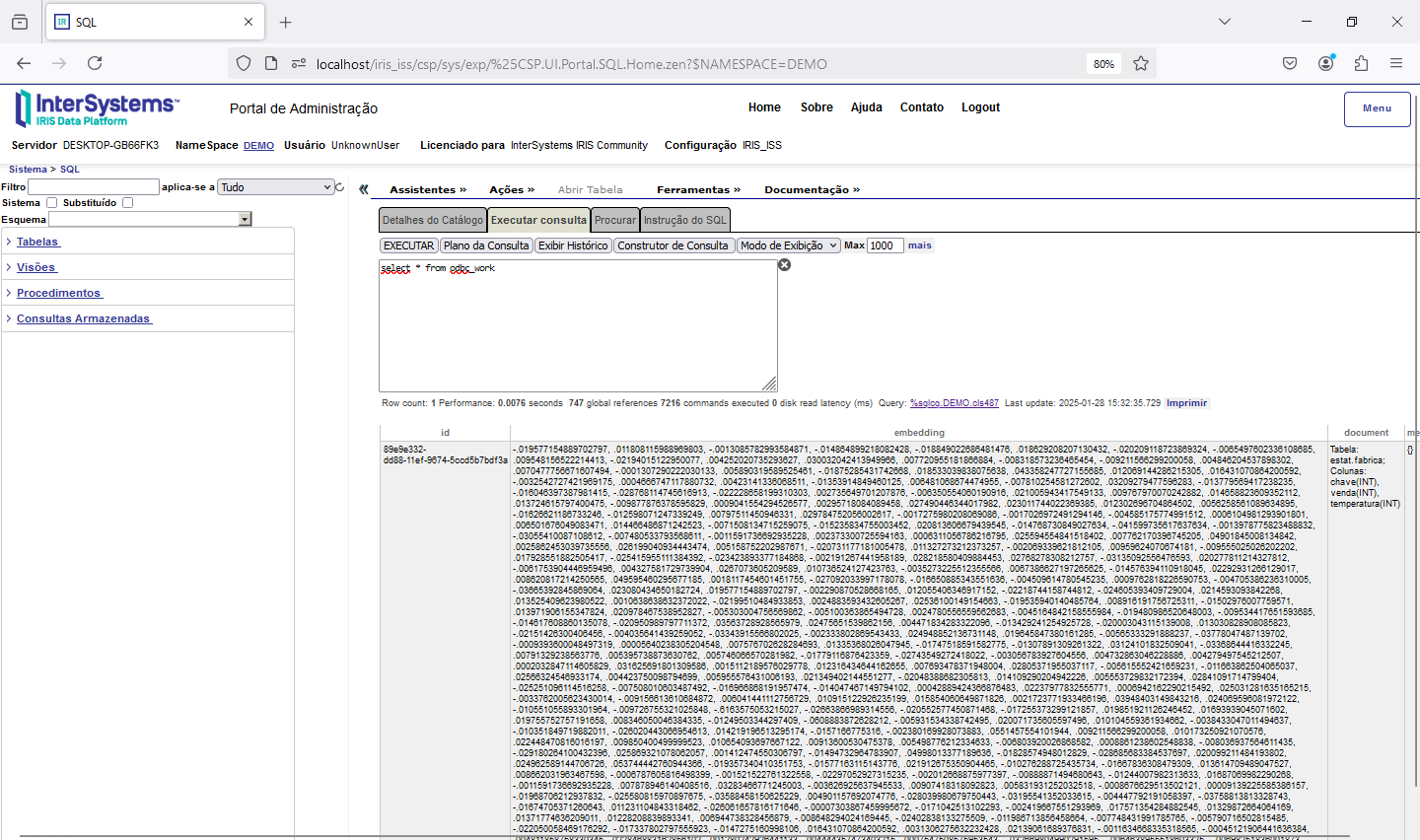
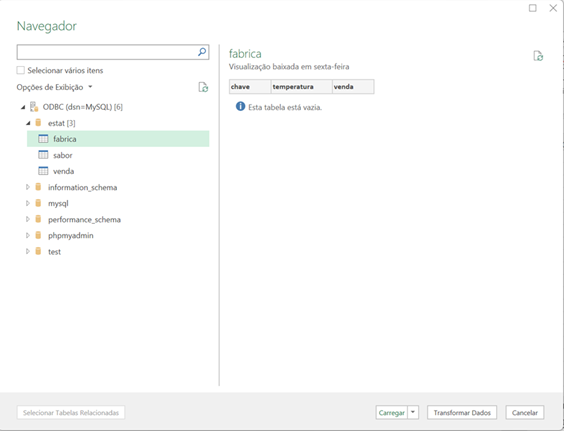
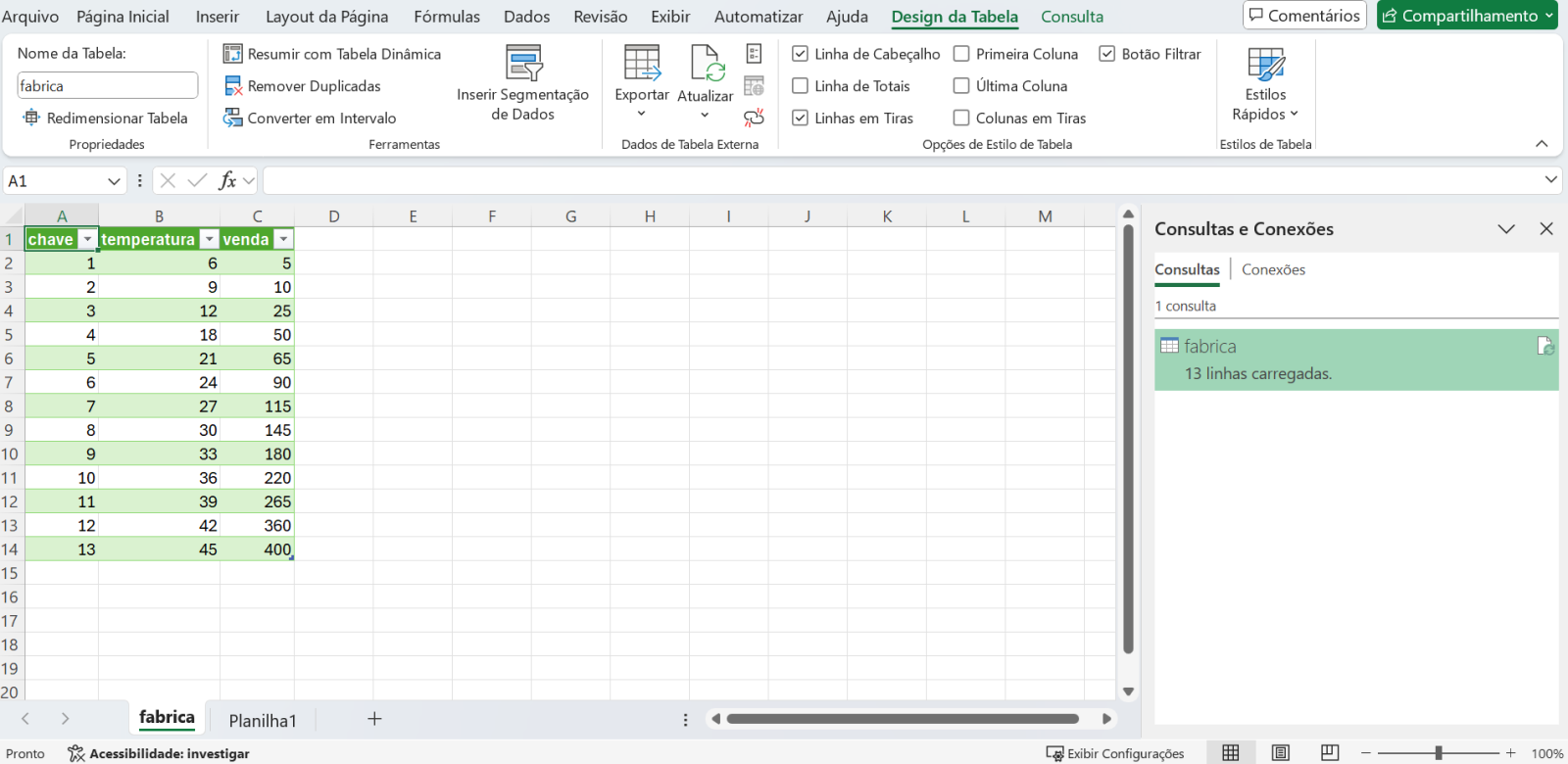
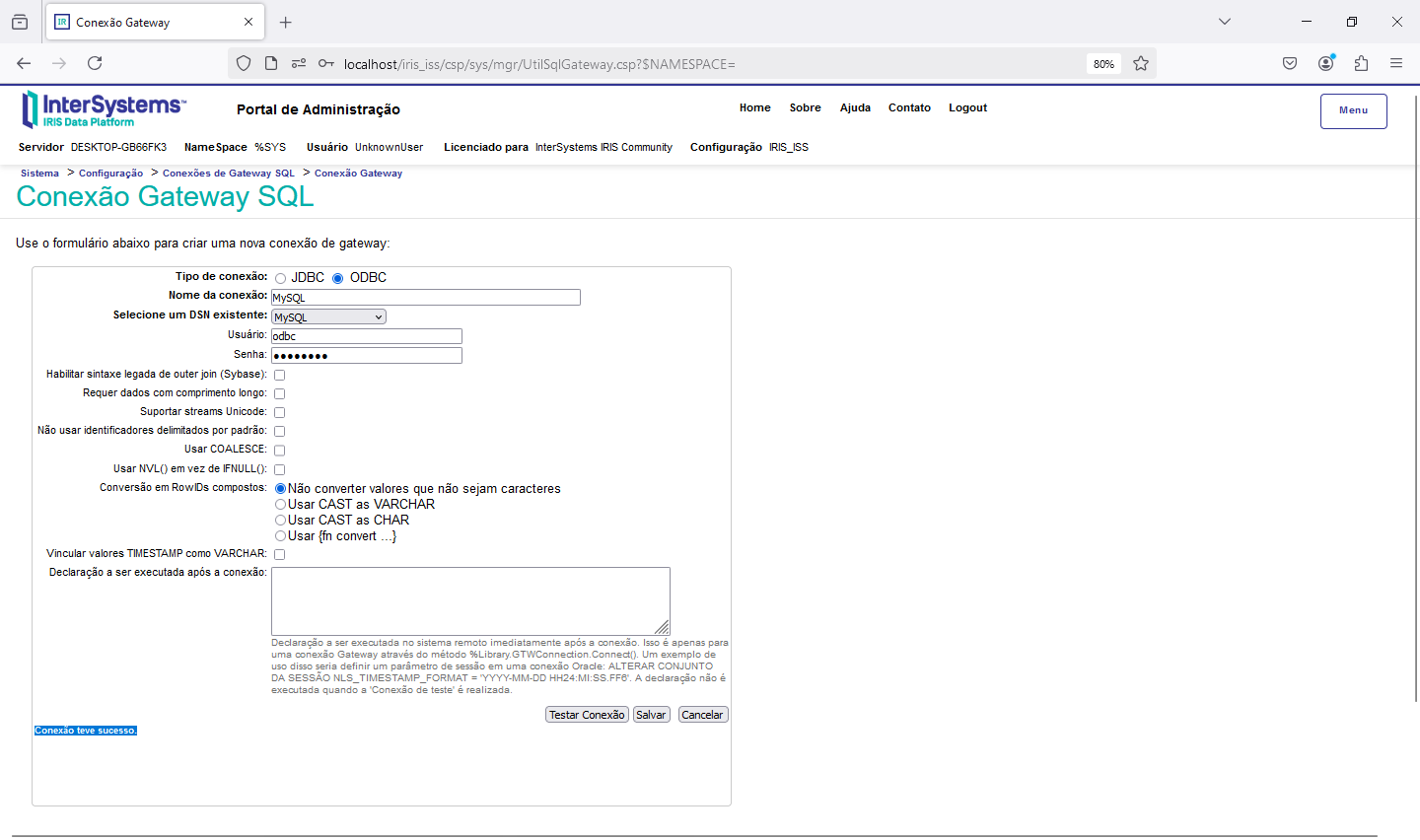
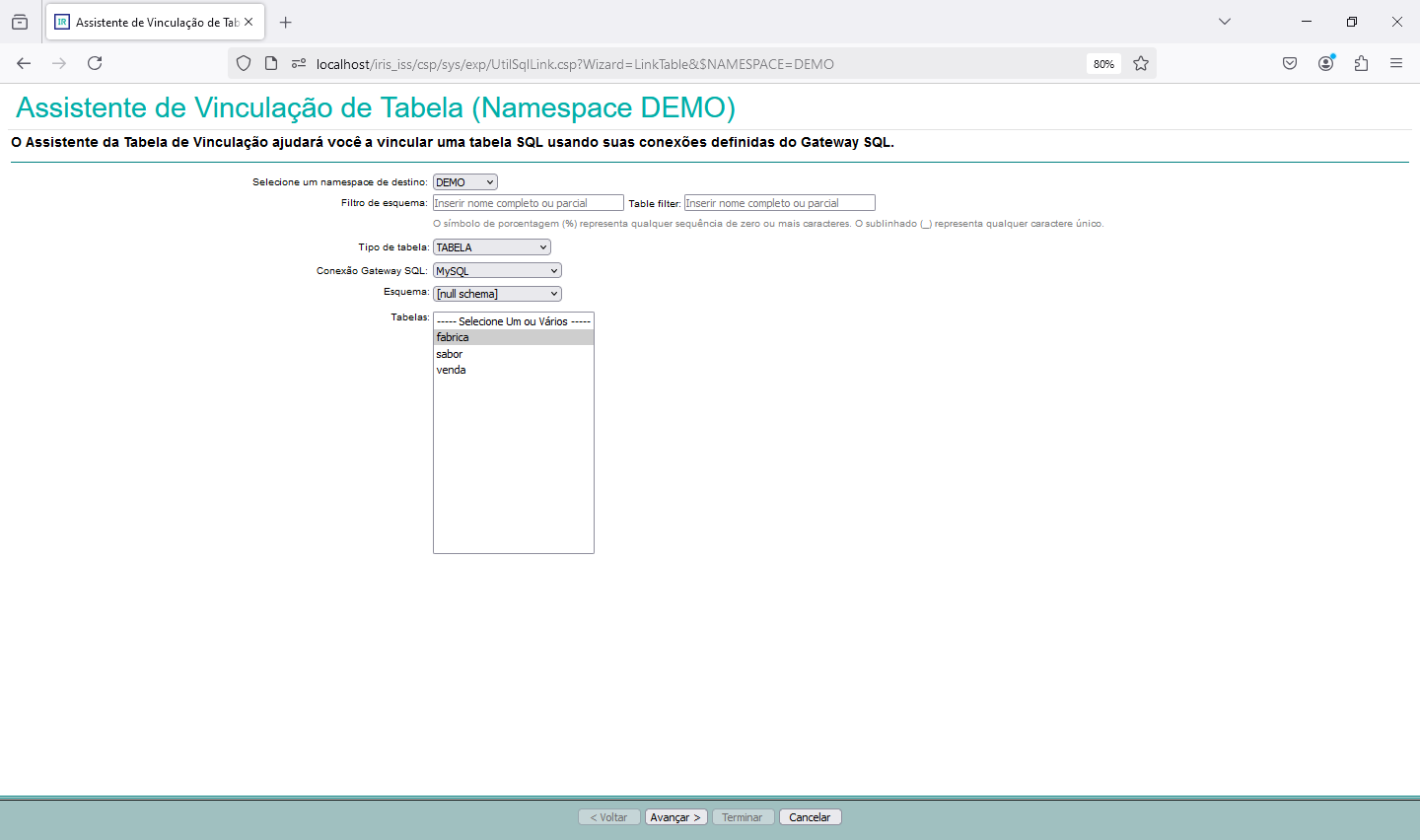
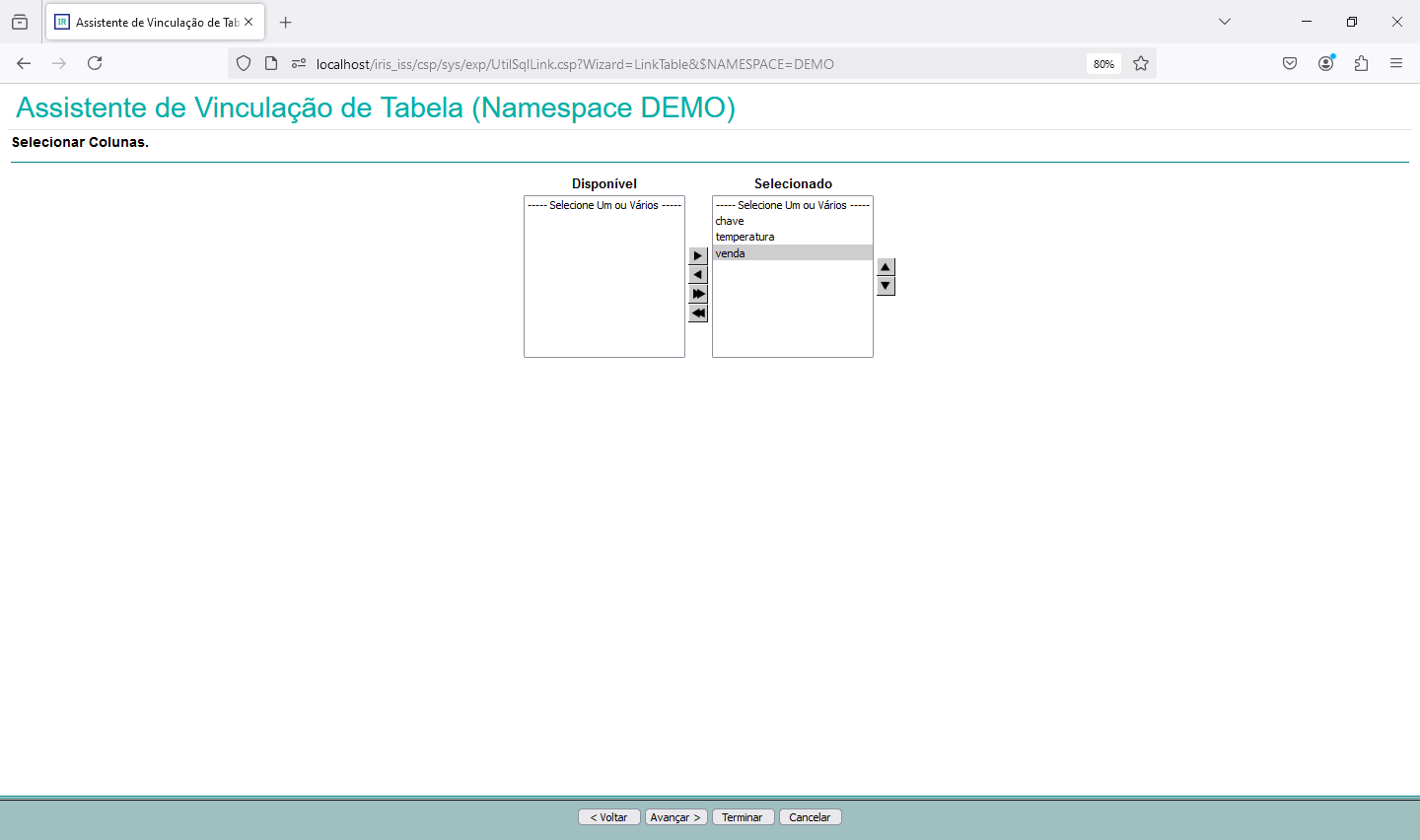
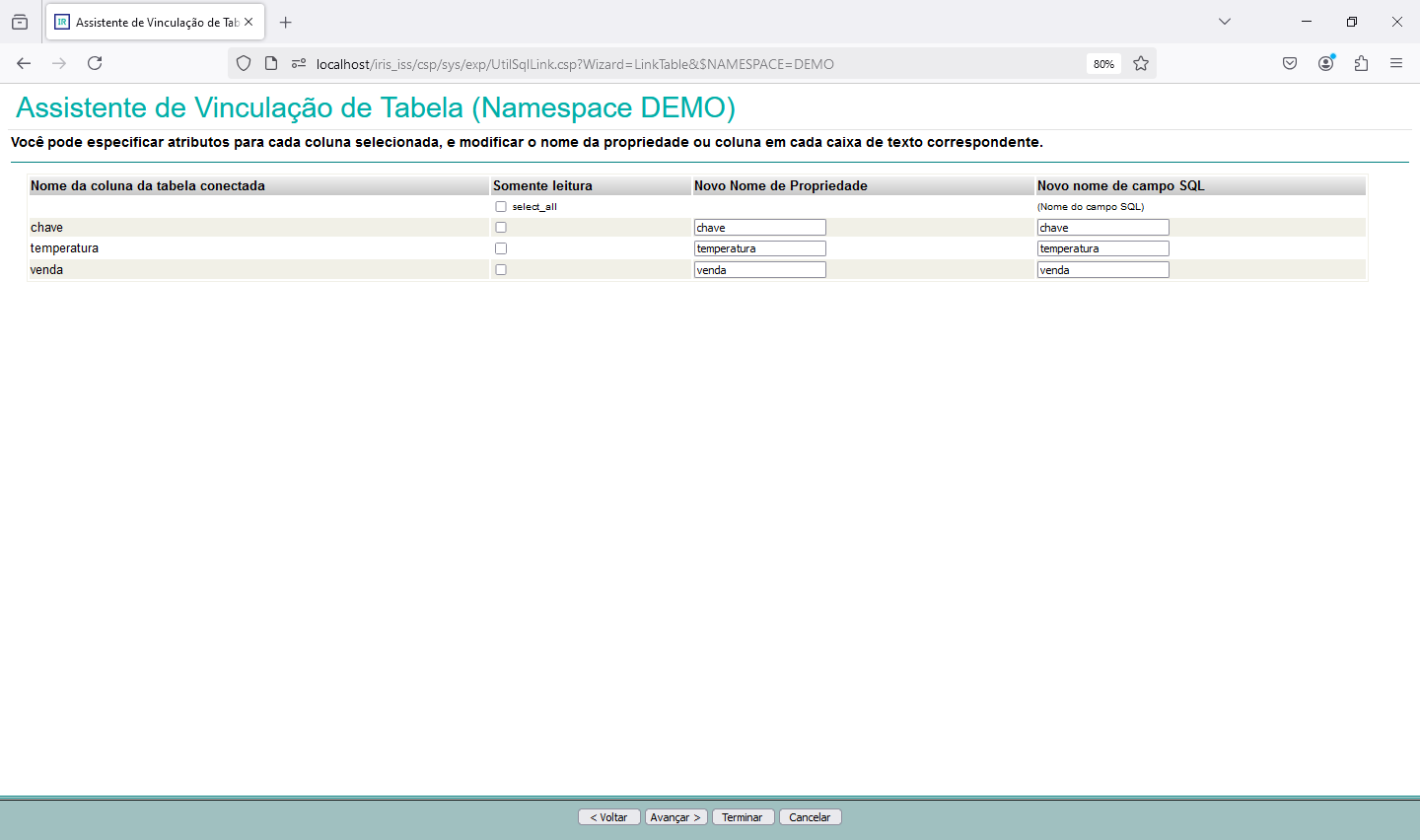
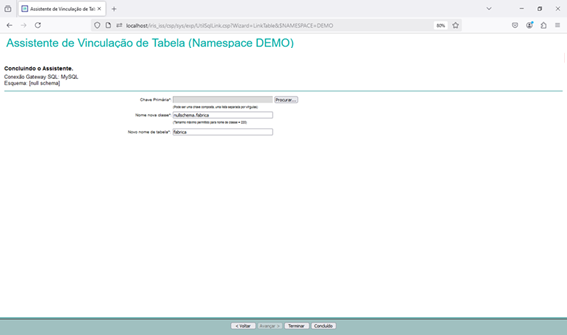
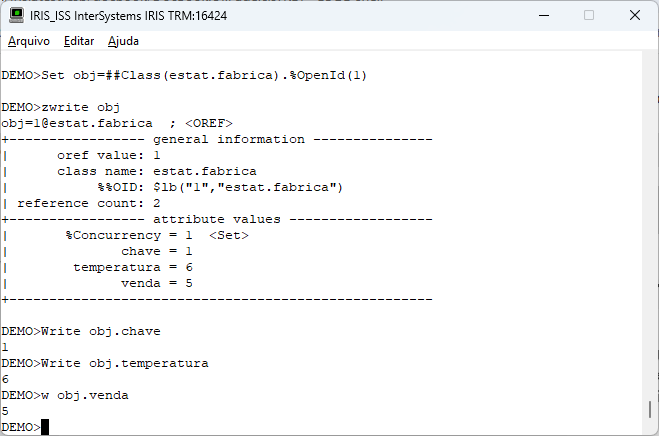
Agora que finalizamos a configuração do Gateway SQL e conseguimos acessar os dados do banco externo via python, e montamos nossa base vetorizada, podemos realizar algumas consultas. Para isso nessa parte do artigo vamos utilizar uma aplicação que desenvolvida com CSP, HTML e Javascript que acessará uma integração no Iris, que então realiza a pesquisa por similaridade dos dados, faz o envio para a LLM e por fim devolve o SQL gerado. A página CSP chama uma API no Iris que recebe os dados a serem utilizados na consulta, chamando a integração. Para mais informações sobre REST nop Iris veja a documentação disponível em https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls...
A seguir o código da API REST criada:
Class Rest.Vector Extends %CSP.REST
{
XData UrlMap
{
<Routes>
<Route Url="/buscar" Method="GET" Call="Buscar" Cors="true"/>
</Routes>
}
ClassMethod Buscar() As %Status
{
set arg1 = %request.Get("arg1")
set sessionID = %request.Get("sessionID")
Set saida = {}
Set obj=##Class(ws.rag.msg.Request).%New()
Set obj.question=arg1
Set obj.sessionId=sessionID
Set tSC=##Class(Ens.Director).CreateBusinessService("ws.rag.bs.Service",.tService)
If tSC
{
Set resp=tService.entrada(obj)
} Else {
Set resp=##Class(ws.rag.msg.Response).%New()
Set resp.resposta=$SYSTEM.Status.GetErrorText(tSC)
}
Set saida = {}
Set saida.resposta=resp.resposta
Set saida.sessionId=sessionID // Devolve o SessionId que chegou
//
Write saida.%ToJSON()
Quit $$$OK
}
}
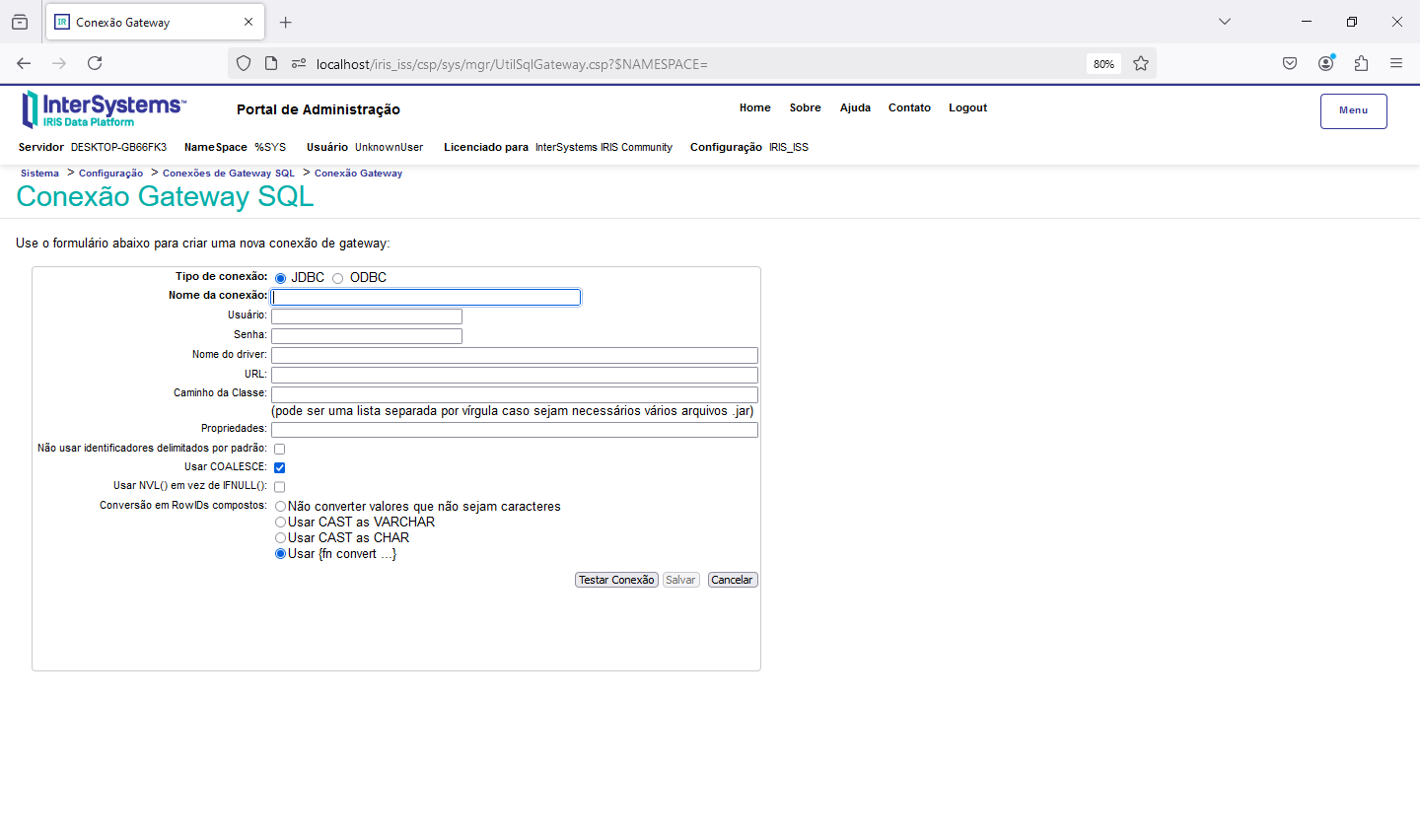
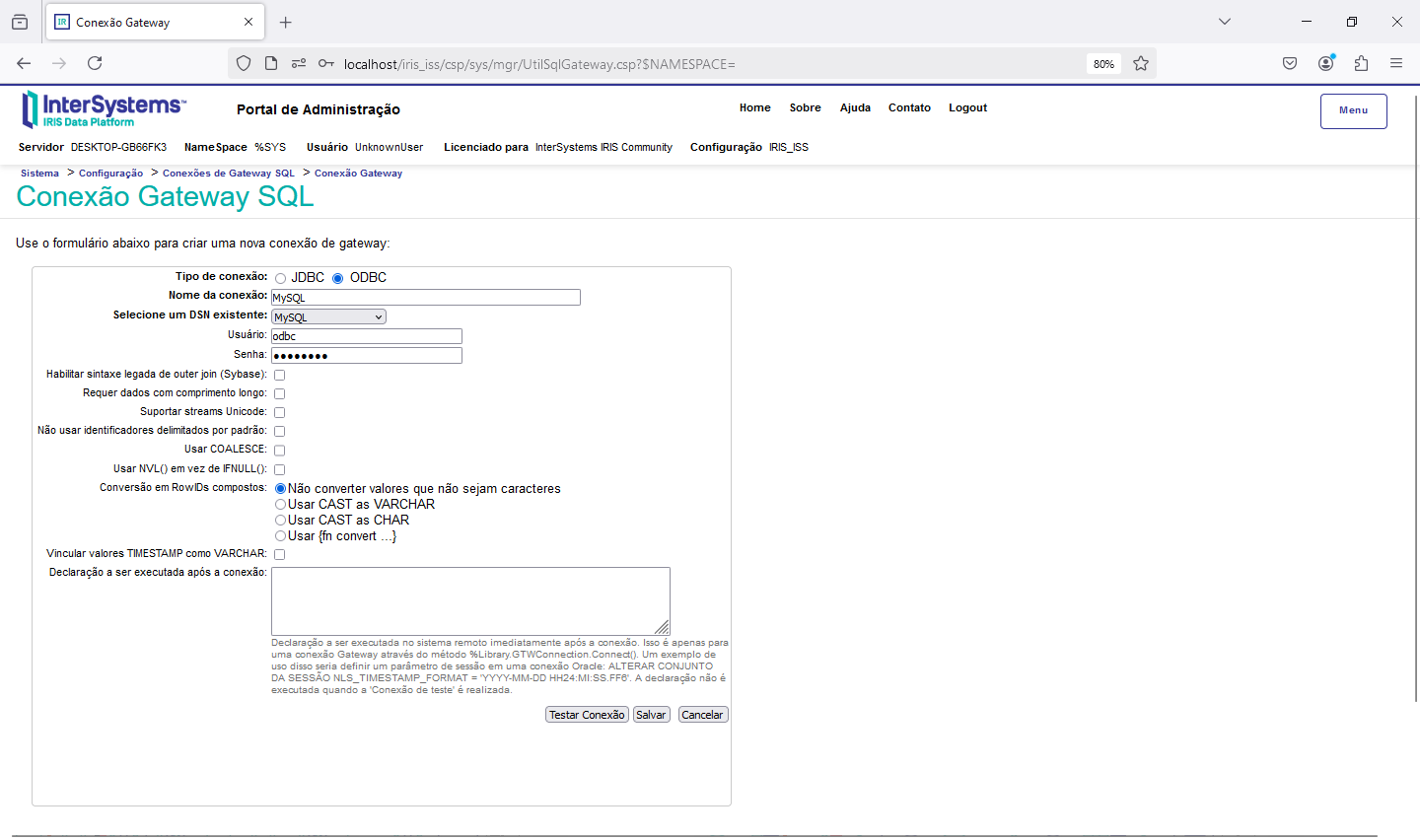
Uma vez criado o código da API REST precisamos criar a configuração da aplicação no Portal de Administração->Administração do Sistema->Segurança->Aplicações Web:

Na aplicação CSP, em Javascript, temos então a chamada da API:
...
async function chamaAPI(url, sessionID)
{
var div = document.getElementById('loader');
div.style.opacity=1;
fetch(url)
.then(response => {
if (!response.ok) {
throw new Error('Erro na resposta da API');
}
return response.json();
})
.then(data => {
incluiDIVRobot(data.resposta, data.sessionID);
})
.catch(error => {
incluiDIVRobot('Erro na chamada da API:: ' + error, sessionID);
});
}
//
const url = 'http://' + 'localhost' + '/api/vector/buscar?arg1=' + texto + '&sessionID=' + sessionID;
chamaAPI(url, sessionID);
...
A aplicação CSP então recebe como entrada a solicitação do usuário (por exemplo: “qual a menor temperatura registrada?”) e chama a API REST.
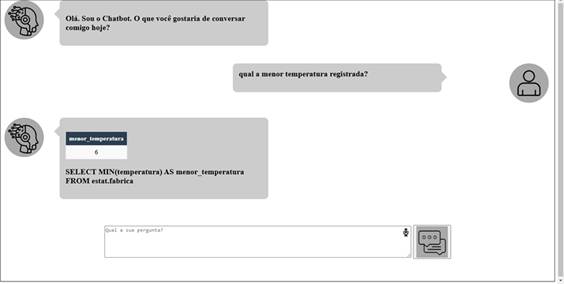
A API REST por sua vez chama uma integração no Iris composta de Service, Process e Operation. Na camada de Operation temos a chamada a LLM, que é feita por um método em python de uma classe. Vendo o trace da integração podemos verificar o processo todo ocorrendo.
Para mais informações sobre o uso de produções no Iris veja a documentação disponível em https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls...
Abaixo os códigos utilizados nas camadas de BS, BP e BO:
A seguir o código do BS (Service):
Class ws.rag.bs.Service Extends Ens.BusinessService
{
Parameter SERVICENAME = "entrada";
Method entrada(pInput As ws.rag.msg.Request) As ws.rag.msg.Response [ WebMethod ]
{
Set tSC=..SendRequestSync("bpRag",pInput,.tResponse)
Quit tResponse
}
}
E o código do BP (Process)
Class ws.rag.bp.Process Extends Ens.BusinessProcessBPL [ ClassType = persistent, ProcedureBlock ]
{
/// BPL Definition
XData BPL [ XMLNamespace = "http://www.intersystems.com/bpl" ]
{
<process language='objectscript' request='ws.rag.msg.Request' response='ws.rag.msg.Response' height='2000' width='2000' >
<sequence xend='200' yend='350' >
<call name='boRag' target='boRag' async='0' xpos='200' ypos='250' >
<request type='ws.rag.msg.Request' >
<assign property="callrequest" value="request" action="set" languageOverride="" />
</request>
<response type='ws.rag.msg.Response' >
<assign property="response" value="callresponse" action="set" languageOverride="" />
</response>
</call>
</sequence>
</process>
}
Storage Default
{
<Type>%Storage.Persistent</Type>
}
}
E o código do BO (Operation):
Class ws.rag.bo.Operation Extends Ens.BusinessOperation [ ProcedureBlock ]
{
Method retrieve(pRequest As ws.rag.msg.Request, Output pResponse As ws.rag.msg.Response) As %Library.Status
{
Set pResponse=##Class(ws.rag.msg.Response).%New()
Set pResponse.status=1
Set pResponse.mensagem=”OK”
Set pResponse.sessionId=..%SessionId
Set st=##Class(Vector.Util).RetrieveRelacional(“odbc_work”,pRequest.question,pRequest.sessionId)
Set pResponse.resposta=st
Quit $$$OK
}
XData MessageMap
{
<MapItems>
<MapItem MessageType=”ws.rag.msg.Request”>
<Method>retrieve</Method>
</MapItem>
</MapItems>
}
}
Na sequencia, as classes de Request e Response da integração:
Request:
Class ws.rag.msg.Request Extends Ens.Request
{
Property collectionName As %String;
Property question As %String(MAXLEN = "");
Property sessionId As %String;
}
Response:
Class ws.rag.msg.Response Extends Ens.Response
{
Property resposta As %String(MAXLEN = "");
Property status As %Boolean;
Property mensagem As %String(MAXLEN = "");
Property sessionId As %Integer;
}
E a classe da Production:
Class ws.rag.Production Extends Ens.Production
{
XData ProductionDefinition
{
<Production Name="ws.rag.Production" LogGeneralTraceEvents="false">
<Description>Produção do Rag DEMO</Description>
<ActorPoolSize>2</ActorPoolSize>
<Item Name="ws.rag.bs.Service" Category="rag" ClassName="ws.rag.bs.Service" PoolSize="0" Enabled="true" Foreground="false" Comment="" LogTraceEvents="false" Schedule="">
</Item>
<Item Name="bpRag" Category="rag" ClassName="ws.rag.bp.Process" PoolSize="1" Enabled="true" Foreground="false" Comment="" LogTraceEvents="false" Schedule="">
</Item>
<Item Name="boRag" Category="rag" ClassName="ws.rag.bo.Operation" PoolSize="1" Enabled="true" Foreground="false" Comment="" LogTraceEvents="false" Schedule="">
</Item>
</Production>
}
}
Ao ser executada a integração mantém os Requests e Responses armazenados permitindo a rastreabilidade no barramento, conforme vemos no trace a seguir:

Podemos ver no trace, por exemplo, que o tempo que a chamada a LLM levou para enviar os dados e devolver o SQL solicitado foi de aproximadamente 10s:

Podemos ver o retorno do BO após tratar a resposta da LLM no código python, para o nosso questionamento:

Assim, através da rastreabilidade da camada de interoperabilidade do Iris, podemos ver todo o fluxo de informação trafegado, os tempos decorridos, eventuais falhas e se for o caso, reprocessar alguma chamada, caso necessário.
A chamada do BO ao método em python passa a solicitação feita pelo usuário. O código em python através da busca vetorial encontra os registros mais semelhantes e os envia a LLM junto com a solicitação do usuário (no caso o modelo da nossa tabela), o histórico de conversa (se existir) e o prompt que são as orientações para balizar a atuação da LLM.
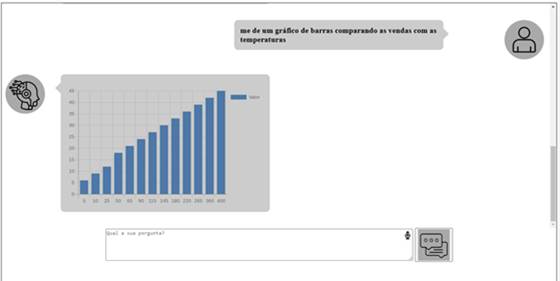
A LLM então gera o SQL que é devolvido ao método em python. O código então executa o SQL e formata a resposta para o padrão esperado, criando as listas de apresentação, gráficos ou downloads de acordo com o retorno aguardado pelo usuário.
Assim, através da aplicação CSP criada, podemos solicitar várias informações, como por exemplo, tabelas de respostas:

Ou gráficos:
Ou ainda, o download de informações:

Para o download, baixando e abrindo o arquivo temos os dados solicitados:

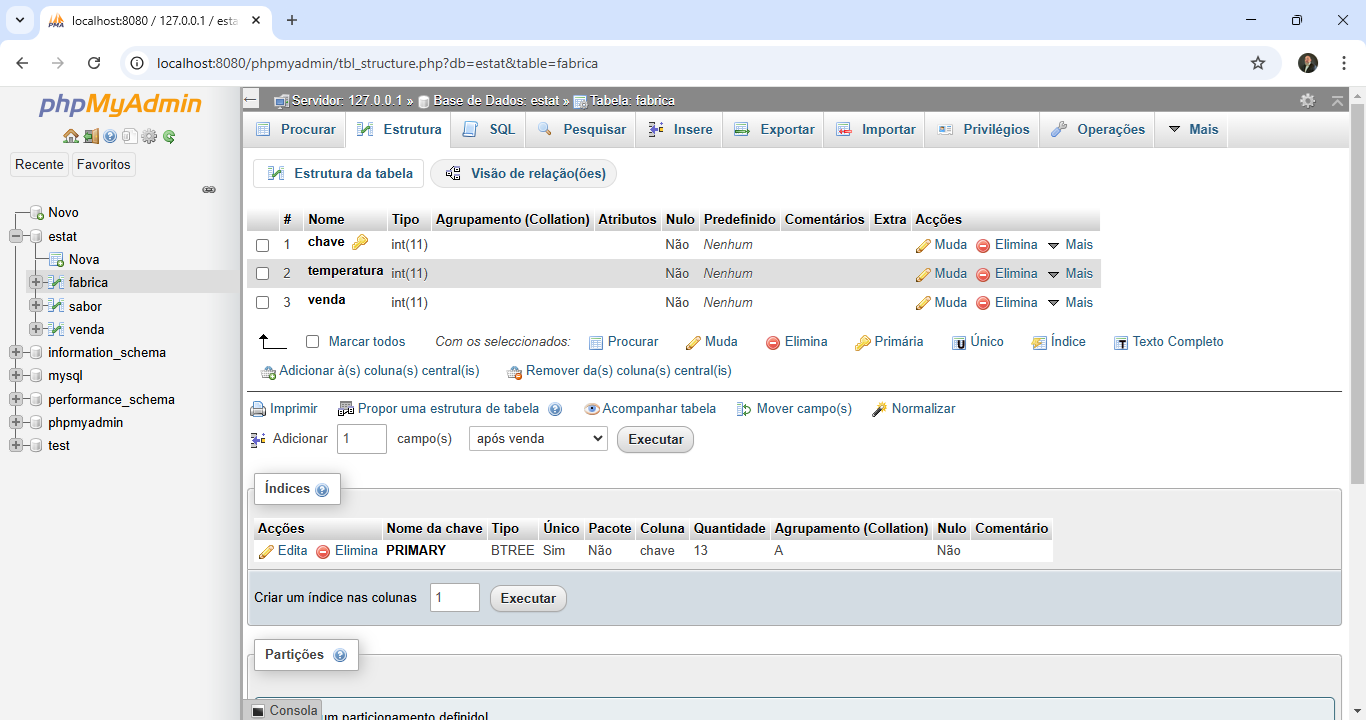
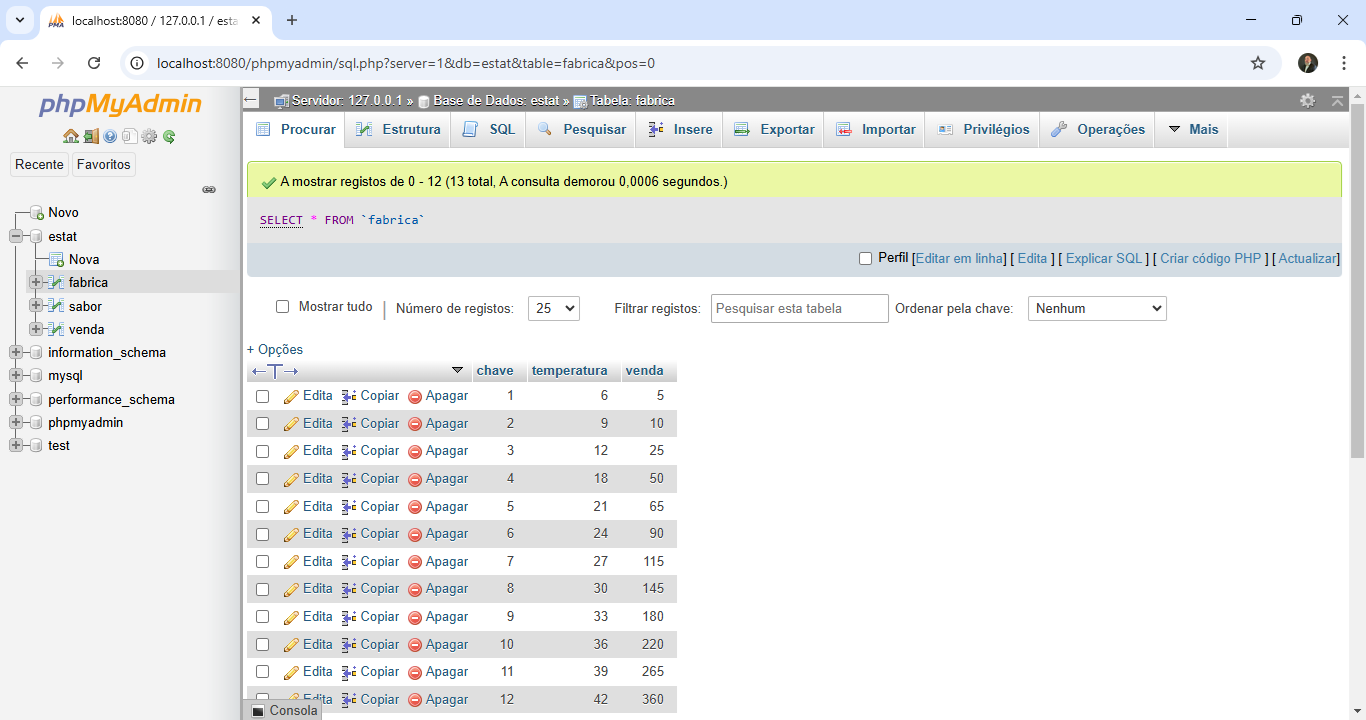
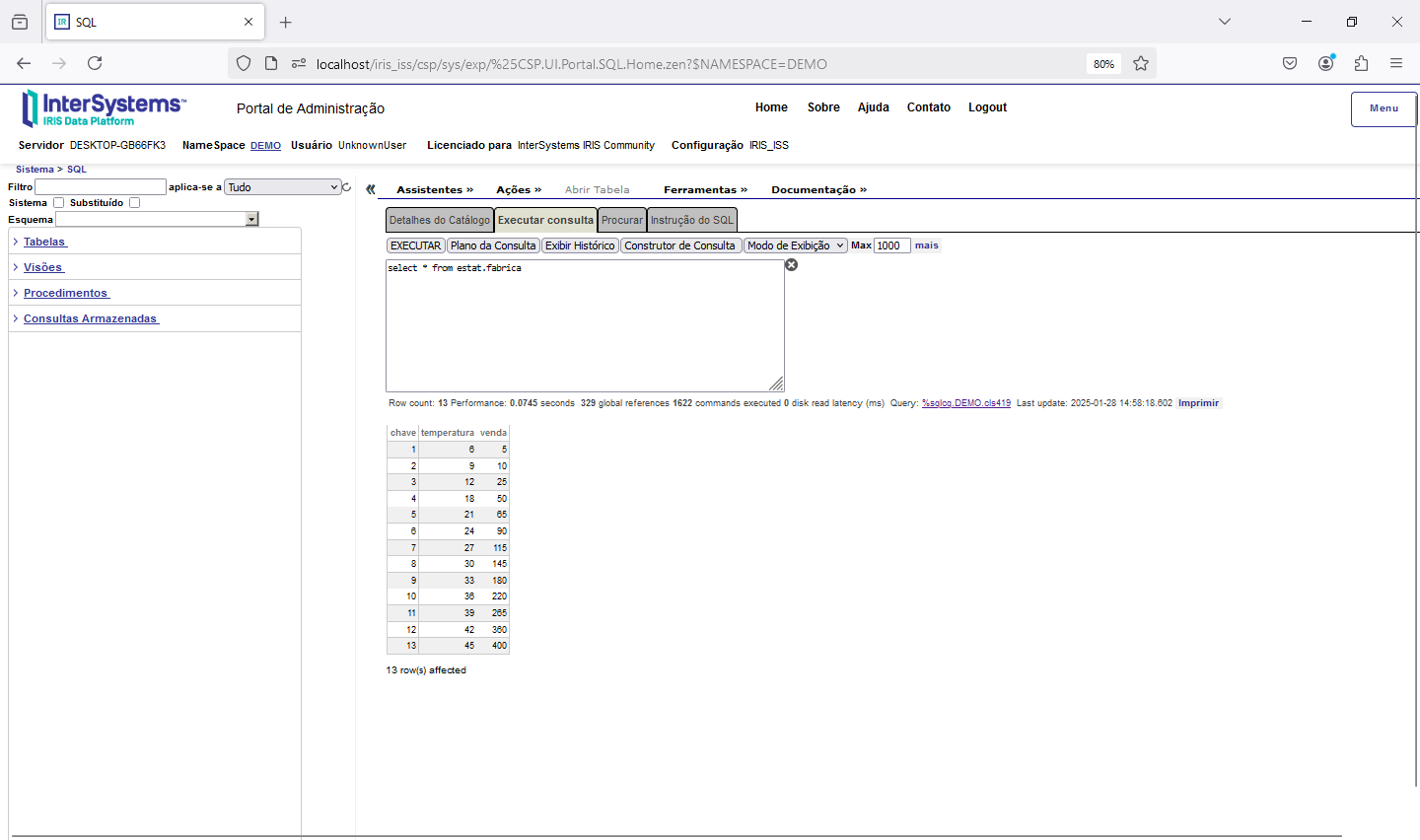
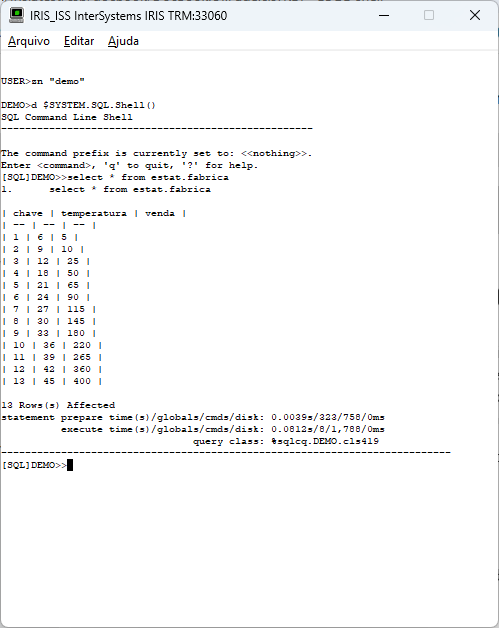
Estes exemplos mostram a leitura dos dados da tabela externa com o Gateway SQL do Iris e o seu uso com código escrito em python. Desta forma podemos utilizar todo o potencial dos dados, que não precisam estar armazenados dentro do Iris. Imagine poder montar uma estação de análise que colete dados de diversos sistemas e dê como resposta informações para tomada de decisão.
Podemos, por exemplo, ter dashboards visualizando dados dos diversos ambientes que compõem o ecossistema de uma empresa, previsões baseadas em algoritmos de ML, RAG para facilitar o levantamento de dados e muito mais.
O Iris pode ser o responsável por acessar, tratar e disponibilizar os dados dos diversos ambientes, com controle, segurança e rastreabilidade, graças às características de interoperabilidade, podendo utilizar código em COS e python, e ser acessado através de códigos em R, C, Java e muito mais. E tudo isso dentro do mesmo produto e sem a necessidade de duplicar ou mover dados entre ambientes.