Hi all,
Let's do some more work about the testing data generation and export the result by REST API.😁
Here, I would like to reuse the datagen.restservice class which built in the pervious article Writing a REST api service for exporting the generated patient data in .csv
This time, we are planning to generate a FHIR bundle include multiple resources for testing the FHIR repository.
Here is some reference for you, if you want to know mare about FHIR The Concept of FHIR: A Healthcare Data Standard Designed for the Future
OK... Let's start😆
1. Create a new utility class datagen.utli.genfhirjson.cls for hosting the FHIR data generation functions
Class datagen.utli.genfhirjson Extends %RegisteredObject
{
}
2. Write a Python function genfhirbundle to generate FHIR bundle in JSON string (this part I asked Chat-GPT to help me😂🤫)
- here, I added an argument isirisfhir (default value is 0) to indicate if this FHIR bundle is sending to IRIS FHIR repository or not.
The reason of doing this is the different syntax of resource reference while using uuid
For example some of the FHIR repository by referencing a patient resource using uuid looks like the following
"subject": {
"reference": "Patient/3ce18a5b-b904-4c77-8a33-b09c3f8c79cc"
}
While IRIS FHIR repository by referencing a patient resource using uuid looks like the following
"subject": {
"reference": "3ce18a5b-b904-4c77-8a33-b09c3f8c79cc"
}
As a result, an argument is added as a selector
Class datagen.utli.genfhirjson Extends %RegisteredObject
{
ClassMethod genfhirbundle(isirisfhir = 0) As %String [ Language = python ]
{
# w ##class(datagen.utli.genfhirjson).genfhirbundle(0)
# w ##class(datagen.utli.genfhirjson).genfhirbundle(1)
from faker import Faker
import random
import json
import uuid
from datetime import datetime
import base64
fake = Faker()
# ----------------------
# Patient
# ----------------------
def generate_fhir_patient():
patient_id = str(uuid.uuid4())
return {
"resourceType": "Patient",
"id": patient_id,
"identifier": [{
"use": "usual",
"system": "http://hospital.smarthealth.org/patient-ids",
"value": str(random.randint(100000, 999999))
}],
"name": [{
"use": "official",
"family": fake.last_name(),
"given": [fake.first_name()]
}],
"gender": random.choice(["male", "female"]),
"birthDate": fake.date_of_birth(minimum_age=0, maximum_age=100).strftime("%Y-%m-%d"),
"address": [{
"use": "home",
"line": [fake.street_address()],
"city": fake.city(),
"state": fake.state(),
"postalCode": fake.postcode(),
"country": fake.country()
}],
"telecom": [{
"system": "phone",
"value": fake.phone_number(),
"use": "mobile"
}],
"meta": {"lastUpdated": datetime.utcnow().strftime("%Y-%m-%dT%H:%M:%SZ")}
}
# ----------------------
# Practitioner
# ----------------------
def generate_fhir_practitioner():
practitioner_id = str(uuid.uuid4())
return {
"resourceType": "Practitioner",
"id": practitioner_id,
"identifier": [{
"system": "http://hospital.smarthealth.org/staff-ids",
"value": str(random.randint(1000, 9999))
}],
"name": [{
"family": fake.last_name(),
"given": [fake.first_name()],
"prefix": ["Dr."]
}],
"telecom": [{
"system": "phone",
"value": fake.phone_number(),
"use": "work"
}],
"meta": {"lastUpdated": datetime.utcnow().strftime("%Y-%m-%dT%H:%M:%SZ")}
}
# ----------------------
# Encounter
# ----------------------
def generate_fhir_encounter(patient_id, practitioner_id):
encounter_id = str(uuid.uuid4())
if isirisfhir==0:
patient_ref=f"Patient/{patient_id}"
practitioner_ref=f"Practitioner/{practitioner_id}"
else:
patient_ref=patient_id
practitioner_ref=practitioner_id
return {
"resourceType": "Encounter",
"id": encounter_id,
"status": "finished",
"class": {
"system": "http://terminology.hl7.org/CodeSystem/v3-ActCode",
"code": "AMB",
"display": "ambulatory"
},
"subject": {"reference": patient_ref},
"participant": [{
"individual": {"reference": practitioner_ref}
}],
"period": {
"start": datetime.utcnow().strftime("%Y-%m-%dT%H:%M:%SZ"),
"end": datetime.utcnow().strftime("%Y-%m-%dT%H:%M:%SZ")
}
}
# ----------------------
# Condition
# ----------------------
def generate_fhir_condition(patient_id, encounter_id, practitioner_id):
condition_id = str(uuid.uuid4())
code_choice = random.choice([
("44054006", "Diabetes mellitus"),
("195967001", "Asthma"),
("38341003", "Hypertension"),
("254637007", "Viral upper respiratory tract infection")
])
if isirisfhir==0:
patient_ref=f"Patient/{patient_id}"
practitioner_ref=f"Practitioner/{practitioner_id}"
encounter_ref=f"Encounter/{encounter_id}"
else:
patient_ref=patient_id
practitioner_ref=practitioner_id
encounter_ref=encounter_id
return {
"resourceType": "Condition",
"id": condition_id,
"clinicalStatus": {
"coding": [{
"system": "http://terminology.hl7.org/CodeSystem/condition-clinical",
"code": "active"
}]
},
"code": {
"coding": [{
"system": "http://snomed.info/sct",
"code": code_choice[0],
"display": code_choice[1]
}]
},
"subject": {"reference": patient_ref},
"encounter": {"reference": encounter_ref},
"asserter": {"reference": practitioner_ref},
"onsetDateTime": datetime.utcnow().strftime("%Y-%m-%dT%H:%M:%SZ")
}
# ----------------------
# Vitals Observation
# ----------------------
def generate_fhir_vitals(patient_id, encounter_id, practitioner_id):
observation_id = str(uuid.uuid4())
if isirisfhir==0:
patient_ref=f"Patient/{patient_id}"
practitioner_ref=f"Practitioner/{practitioner_id}"
encounter_ref=f"Encounter/{encounter_id}"
else:
patient_ref=patient_id
practitioner_ref=practitioner_id
encounter_ref=encounter_id
return {
"resourceType": "Observation",
"id": observation_id,
"status": "final",
"category": [{
"coding": [{
"system": "http://terminology.hl7.org/CodeSystem/observation-category",
"code": "vital-signs",
"display": "Vital Signs"
}]
}],
"code": {
"coding": [{
"system": "http://loinc.org",
"code": "85354-9",
"display": "Blood pressure panel"
}]
},
"subject": {"reference": patient_ref},
"encounter": {"reference": encounter_ref},
"performer": [{"reference": practitioner_ref}],
"effectiveDateTime": datetime.utcnow().strftime("%Y-%m-%dT%H:%M:%SZ"),
"component": [
{
"code": {
"coding": [{
"system": "http://loinc.org",
"code": "8480-6",
"display": "Systolic blood pressure"
}]
},
"valueQuantity": {
"value": random.randint(100, 140),
"unit": "mmHg",
"system": "http://unitsofmeasure.org",
"code": "mm[Hg]"
}
},
{
"code": {
"coding": [{
"system": "http://loinc.org",
"code": "8462-4",
"display": "Diastolic blood pressure"
}]
},
"valueQuantity": {
"value": random.randint(60, 90),
"unit": "mmHg",
"system": "http://unitsofmeasure.org",
"code": "mm[Hg]"
}
}
]
}
# ----------------------
# Lab Observations
# ----------------------
def generate_fhir_lab(patient_id, encounter_id, practitioner_id):
labs = [
("2339-0", "Glucose [Mass/volume] in Blood", "mg/dL", random.randint(70, 200)),
("2093-3", "Cholesterol [Mass/volume] in Serum", "mg/dL", random.randint(150, 250)),
("4548-4", "Hemoglobin A1c/Hemoglobin.total in Blood", "%", round(random.uniform(4.5, 10.0), 1))
]
lab_obs = []
if isirisfhir==0:
patient_ref=f"Patient/{patient_id}"
practitioner_ref=f"Practitioner/{practitioner_id}"
encounter_ref=f"Encounter/{encounter_id}"
else:
patient_ref=patient_id
practitioner_ref=practitioner_id
encounter_ref=encounter_id
for loinc, display, unit, value in labs:
obs_id = str(uuid.uuid4())
lab_obs.append({
"resourceType": "Observation",
"id": obs_id,
"status": "final",
"category": [{
"coding": [{
"system": "http://terminology.hl7.org/CodeSystem/observation-category",
"code": "laboratory",
"display": "Laboratory"
}]
}],
"code": {
"coding": [{
"system": "http://loinc.org",
"code": loinc,
"display": display
}]
},
"subject": {"reference": patient_ref},
"encounter": {"reference": encounter_ref},
"performer": [{"reference": practitioner_ref}],
"effectiveDateTime": datetime.utcnow().strftime("%Y-%m-%dT%H:%M:%SZ"),
"valueQuantity": {
"value": value,
"unit": unit,
"system": "http://unitsofmeasure.org",
"code": unit
}
})
return lab_obs
# ----------------------
# Medication + MedicationRequest
# ----------------------
def generate_fhir_medication(patient_id, encounter_id, practitioner_id):
meds = [
("860975", "Metformin 500mg tablet"),
("860976", "Lisinopril 10mg tablet"),
("860977", "Salbutamol inhaler"),
("860978", "Atorvastatin 20mg tablet")
]
med_code, med_name = random.choice(meds)
med_id = str(uuid.uuid4())
med_request_id = str(uuid.uuid4())
if isirisfhir==0:
patient_ref=f"Patient/{patient_id}"
practitioner_ref=f"Practitioner/{practitioner_id}"
encounter_ref=f"Encounter/{encounter_id}"
else:
patient_ref=patient_id
practitioner_ref=practitioner_id
encounter_ref=encounter_id
medication = {
"resourceType": "Medication",
"id": med_id,
"code": {
"coding": [{
"system": "http://www.nlm.nih.gov/research/umls/rxnorm",
"code": med_code,
"display": med_name
}]
}
}
medication_request = {
"resourceType": "MedicationRequest",
"id": med_request_id,
"status": "active",
"intent": "order",
"medicationReference": {"reference": f"Medication/{med_id}"},
"subject": {"reference": patient_ref},
"encounter": {"reference": encounter_ref},
"requester": {"reference": practitioner_ref},
"authoredOn": datetime.utcnow().strftime("%Y-%m-%dT%H:%M:%SZ"),
"dosageInstruction": [{
"text": f"Take {random.randint(1,2)} tablet(s) daily"
}]
}
return [medication, medication_request]
# ----------------------
# DocumentReference (Discharge Summary)
# ----------------------
def generate_fhir_documentreference(patient_id, encounter_id, practitioner_id):
doc_id = str(uuid.uuid4())
note_text = f"Discharge summary for patient {patient_id}. Diagnosis: Stable. Follow-up in 2 weeks."
encoded_note = base64.b64encode(note_text.encode("utf-8")).decode("utf-8")
if isirisfhir==0:
patient_ref=f"Patient/{patient_id}"
practitioner_ref=f"Practitioner/{practitioner_id}"
encounter_ref=f"Encounter/{encounter_id}"
else:
patient_ref=patient_id
practitioner_ref=practitioner_id
encounter_ref=encounter_id
return {
"resourceType": "DocumentReference",
"id": doc_id,
"status": "current",
"type": {
"coding": [{
"system": "http://loinc.org",
"code": "18842-5",
"display": "Discharge summary"
}]
},
"subject": {"reference": patient_ref},
"author": [{"reference": practitioner_ref}],
"context": {"encounter": [{"reference": encounter_ref}]},
"content": [{
"attachment": {
"contentType": "text/plain",
"language": "en",
"data": encoded_note,
"title": "Discharge Summary Note"
}
}]
}
# ----------------------
# Bundle Generator (transaction)
# ----------------------
def generate_patient_bundle(n=1):
bundle = {
"resourceType": "Bundle",
"type": "transaction",
"id": str(uuid.uuid4()),
"meta": {"lastUpdated": datetime.utcnow().strftime("%Y-%m-%dT%H:%M:%SZ")},
"entry": []
}
for _ in range(n):
patient = generate_fhir_patient()
practitioner = generate_fhir_practitioner()
encounter = generate_fhir_encounter(patient["id"], practitioner["id"])
condition = generate_fhir_condition(patient["id"], encounter["id"], practitioner["id"])
vitals = generate_fhir_vitals(patient["id"], encounter["id"], practitioner["id"])
labs = generate_fhir_lab(patient["id"], encounter["id"], practitioner["id"])
meds = generate_fhir_medication(patient["id"], encounter["id"], practitioner["id"])
docref = generate_fhir_documentreference(patient["id"], encounter["id"], practitioner["id"])
all_resources = [patient, practitioner, encounter, condition, vitals] + labs + meds + [docref]
for resource in all_resources:
bundle["entry"].append({
"fullUrl": f"urn:uuid:{resource['id']}",
"resource": resource,
"request": {
"method": "POST",
"url": resource["resourceType"]
}
})
return bundle
# ----------------------
# Example Run
# ----------------------
fhir_bundle = generate_patient_bundle(1)
return json.dumps(fhir_bundle, indent=2)
}
}
Let's test the function by the following script, for generating FHIR bundle for non IRIS FHIR repository
w ##class(datagen.utli.genfhirjson).genfhirbundle(0)
.png)
and check the reference syntax
.png)
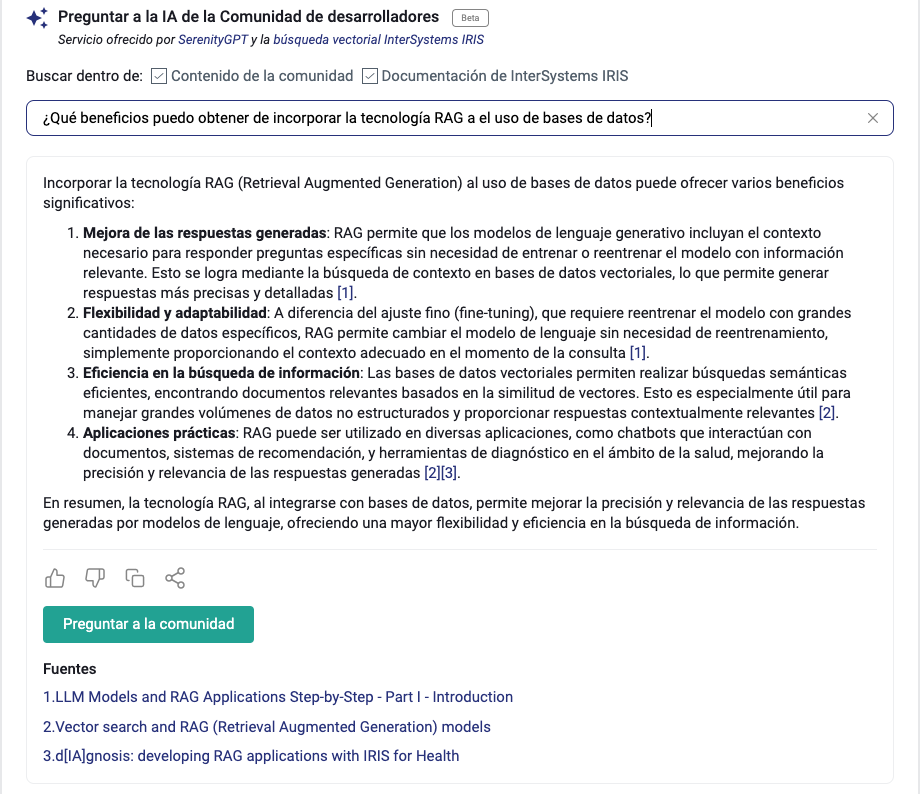
Now test the function by the following script, for generating FHIR bundle for IRIS FHIR repository😁
w ##class(datagen.utli.genfhirjson).genfhirbundle(1)
.png)
and check the reference syntax
.png)
Great! Now go back the pervious article Writing a REST api service for exporting the generated patient data in .csv
We would like to add a new function and update the route for the datagen.restservice class.
1. Add a new function GenFHIRBundle, with an parameter isirisfhir for indicating which kind of reference syntax we prefer.
If no parameters are input, it will out put the reference syntax for non IRIS FHIR repository
ClassMethod GenFHIRBundle() As %Status
{
set isirisfhir=$GET(%request.Data("isirisfhir",1),"")
if isirisfhir="" set isirisfhir=0
w ##class(datagen.utli.genfhirjson).genfhirbundle(isirisfhir)
return $$$OK
}
2. Then we add a route for the REST service and compile😀
<Route Url="/gen/fhirbundle" Method="GET" Call="GenFHIRBundle"/>
the updated datagen.restservice class will look like the following.
.png)
Great!! That's all we need to do!😁
Let's test in postman!!
Try to GET by the following URL for generating FHIR bundle for non IRIS FHIR repository
localhost/irishealth/csp/mpapp/gen/fhirbundle
.png)
Looks good!!
Now Try to GET by the following URL for generating FHIR bundle for IRIS FHIR repository
localhost/irishealth/csp/mpapp/gen/fhirbundle?isirisfhir=1
.png)
Works well!!!😆😉
Thank you very much for reading. 😘
.png)
.png)
.png)
.png)