I wondered actually, what for do you prefix all variable names with "zzzz".
- Log in to post comments
I wondered actually, what for do you prefix all variable names with "zzzz".
There is also this way:
set p = ##class(%ZEN.proxyObject).%New()
set p.a = 1
set p.b = 2
do p.%ToJSON()
kill p.%data("b")
do p.%ToJSON()kill p.%data("b") would completely remove b property. But better use Caché 2016.1 with native JSON support.
Another queue processing sample is now available in this GitHub repository, courtesy of Vladimir Prushkovskiy.
Formatted your code a little.
getst(getvars, StBeg, temp) ; Save call stack in local or global array
; In:
; getvars = 1 - save variables defined at the last stack level
; getvars = 0 or omitted - don't save; default = 0
; StBeg - starting stack level for save; default: 1
; temp - where to save ($name).
; Out:
; temp - number of stack levels saved
; temp(1) - call at StBeg level
; temp(2) - call at StBeg+1 level
; ...
; temp(temp) - call at StBeg+temp-1 level
;
; Calls are saved in format:
; label+offset^rouname +CommandNumberInsideCodeLine~CodeLine w/o leading spaces"
; E.g.:
; temp(3) = First+2^%ZUtil +3~i x=""1stAarg"" s x=x+1 s c=$$Null(x,y)"
; Sample calls:
; d getst^%ZUtil(0,1,$name(temp)) ; save calls w/o variables in temp starting from level 1
; d getst^%ZUtil(1,4,$name(^zerr($i(^zerr)))) ; save calls with variables in ^zerr starting from level 4
new loop,zzz,StEnd
set getvars = $get(getvars)
set StBeg = $get(StBeg, 1)
kill @temp
set @temp = 0
set StEnd = $STACK(-1)-2
for loop = StBeg:1:StEnd {
set @temp = @temp+1
set @temp@(@temp) = $STACK(loop, "PLACE") _ "~" _ $zstrip($STACK(loop, "MCODE"), "<W")
if getvars,(loop=StEnd) {
set zzz=""
for {
set zzz = $order(@zzz)
quit:zzz=""
set @temp@(@temp,zzz) = $get(@zzz)
}
if $zerror'="" {
set @temp@(@temp,"$ze") = $zerror
}
}
}
quit 1You can fill $zerror by passing a name into LOG^%ETN:
Do LOG^%ETN("test")
It would record your current $zerror value, replace it with "test", execute LOG captue, and at the end restore $zerror to what it was before the call.
Thank you.
Also note, that e.Log() calls LOG^%ETN.
I assume that's a comment to my answer?
If yes, here's the working code. Maybe I missed some changes in my answer. Because, again, I needed to do too much changes to run the code in the first place.
I made the following changes:
1. Changed
Set mimePart.ContentType = "application/pdf"
to
Set mimePart.ContentType = "application/x-object"
2. Commented out:
Do mimeMsg.SetHeader("Content-Disposition","attachment; name=""Files1""; filename="""_docName_"""")
Set mimeMsg.ContentTransferEncoding = "base64"3. Uncommented:
//Set req.ContentType = "multipart/form-data;boundary=" _mimeMsg.Boundary
After these change I received non-empty files object.
"files": {
"uploadedfile": "cd \\\r\n@echo start >> date.txt\r\n"
}Howether. Here's some tips on how to ask questions like these (with not working code samples):
1. It must run everywhere. Remove the calls to other code (hardcode values if needed), like:
##class(HData.SiteSettings).GetFaxLogin()2. Remove unused arguments, like coverpath
3. Remove non essential code like:
Set req.SSLConfiguration = "CardChoice"
Do req.InsertFormData("Username",##class(HData.SiteSettings).GetFaxLogin())
Do req.InsertFormData("Password",##class(HData.SiteSettings).GetFaxPassword())
Do req.InsertFormData("ProductId",##class(HData.SiteSettings).GetFaxProductId())
Do req.InsertFormData("cookies","false")
Do req.InsertFormData("header","header")
//Create job name for fax
Set sendDate = +$H
Set sendTime = $P($ZTIMESTAMP,",",2)+(15*60)
Set schedDate = $ZDATETIME(sendDate_","_sendTime,1,4)
Set schedDate = $E(schedDate,1,16)_" "_$E(schedDate,17,18)
Set docList = $LFS(docpath,"\")
Set docName = $LISTGET(docList,$LL(docList))
Do req.InsertFormData("JobName",schedDate_docName)
//format phone number and set billing code
Set num = $REPLACE(phone,"-","")
Do req.InsertFormData("BillingCode",num)
Do req.InsertFormData("Numbers1",num)
//get notification email
Set email = ##class(HData.SiteSettings).GetFaxNotifyEmail()
If (email '= "") Do req.InsertFormData("FeedbackEmail",email)4. Comment out unused and misleading code paths like
Set base64 = ##class(%SYSTEM.Encryption).Base64Encode(docStream)
Set mimeMsg.ContentTransferEncoding = "base64"5. Provide a GitHub Gist snippet of an xml file (with the code) to import and write how to run it.
Your goal, is to make it extremely easy for everyone to take a look at your snippet. All the process must consist of these two steps:
I meant: write a new class with method generator. And inherit from it.
Since XMLEnabled class can be not persistent and, therefore, not have an extent at all, there is no such method. If you need to write XMLExportToFile() for several classes you can write method generator which generates a method that would:
And inherit all classes, in which you have a need of XMLExportToFile() method from this class.
It's for translating response status into Caché status. I have the following code:
ClassMethod GetResponseStatus(Request As %Net.HttpRequest) As %Status
{
Set Status = Request.HttpResponse.StatusCode
Quit:(Status = 200) $$$OK
Set Body = Request.HttpResponse.Data.Read($$$MaxCacheInt)
Quit $$$ERROR($$$GeneralError,"Status code: " _ Status _ " ReasonPhrase: " _ Request.HttpResponse.ReasonPhrase _ " StatusLine: " _ Request.HttpResponse.StatusLine _ " Body: " _ Body)
}And I want to add URL reporting to it.
There is more to URL then just that. For example:
Thanks. I thought it would be something like this, but hoped there was a system method somewhere.
I want to edit this answer.
Answer
I think latency is more important than bandwith. Studio works fine on 100kb/s wireless connection, but when ping goes higher than 1s it becomes kind of slow.
Missed that part. Thank you.
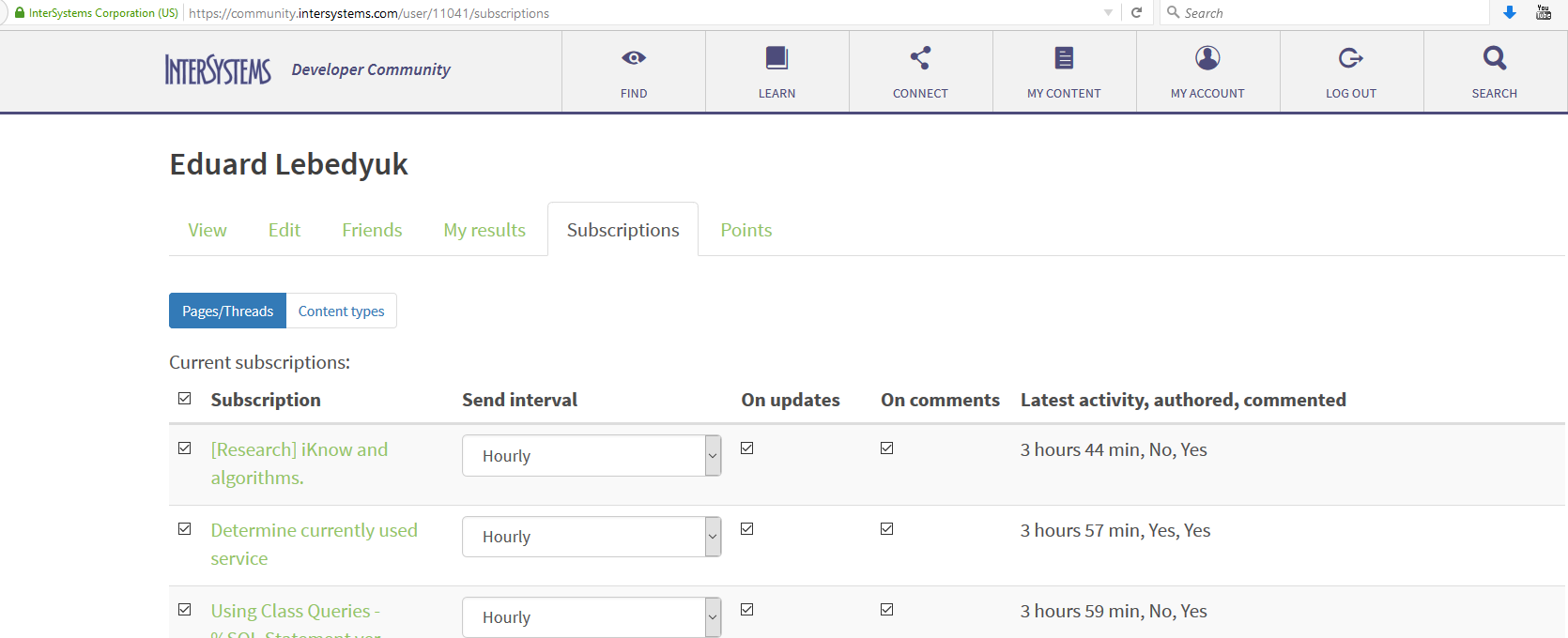
Where can I find "Settings and Preferences" in Subscriptions tab under My Account?
You can open this (any) method in Studio and see the definition (with some rare exceptions, in iKnow package only %iKnow.TextTransformation.HeaderRepositorySetArray and %iKnow.TextTransformation.KeyRepositorySetArray classes are not availible). It's the best way to get an idea of how method works and the code usually even has comments.
Scrapped from GetSimilar():
And you need to do this why? I mean what is the end goal?
To show user some menu when they open Terminal?
Yes.
You can specify "Startup Tag^Routine" for this purpose:
Awesome. Didn't knew that it aplied only to terminal devices.
Thank you!
Hi. About your second question, you can easily extend Caché ObjectScript, to do it. Wouldn't recommend it for use in production, but why not add some syntax sugar on you dev instance?
Create %ZLANGC00 mac routine with the following code:
; %ZLANGC00
; custom commands for ObjectScript
; http://docs.intersystems.com/cache20141/csp/docbook/DocBook.UI.Page.cls?KEY=GSTU_customize
Quit
/// Execute Query and display the results
/// Call like this:
/// zsql "SELECT TOP 10 Name FROM Sample.Person"
ZSQL(Query)
#Dim ResultSet As %SQL.StatementResult
Set ResultSet = ##class(%SQL.Statement).%ExecDirect(, Query)
Do ResultSet.%Display()
QuitSave and compile it and then you can execute sql in a terminal like this:
zsql "SELECT TOP 10 Name FROM Sample.Person"
It would display something like this:
SAMPLES>zsql "SELECT TOP 10 Name FROM Sample.Person" Name Adam,Wolfgang F. Adams,Phil H. Ahmed,Edward V. Ahmed,Michael O. Ahmed,Patrick O. Allen,Zelda P. Alton,Samantha F. Bach,Buzz E. Bach,Fred X. Bach,Patrick Y. 10 Rows(s) Affected
That said I myself prefer executing SQL queries in SMP because you don't need to type them there (drag&drop from the left panel or copy&paste from the code) - it's very convenient.
How's your experience with EMS?
UPD. Seen last modified date, nevermind.
Yes, but if direct global iteration is used, the speed would probably be higher then sql.
The fastest query-like interface is %SQL.CustomResultSet. You need to write your owl logic, though.
It can be called like this:
Set resultset= ##class(Package.YourCustomQueryRS).%New()
While resultset.%Next() {
Write resultset.Id,!
}I don't think dropdown menu items support key property. Maybe you can use id property for your purposes instead?
Looks quite interesting. Are there any planned release date? Would there be an option to write your own checks?
Is there any way to set environmental variables before calling $zf?
For example I want to add something to PATH, but if I do it in an actual $zf call it would be a lot longer and hard to read. So is there any way to set environmental variables for current process from Cache?
2016.2 Studio does not seem to have package delete button.
Just delete all contents in a package and it would disappear. Or execute this query:
DELETE FROM %Dictionary.ClassDefinition WHERE Name %STARTSWITH 'package'To upload images click on this button (on the WYSIWYG editor): 