New
Hello,
I have problem to get working my web application in IIS. On apache just works fine.
I had an app in wwwroot called test, there is index.html file where is tag
Hypertext Markup Language (HTML) is the standard markup language for creating web pages and web applications.
Hello,
I have problem to get working my web application in IIS. On apache just works fine.
I had an app in wwwroot called test, there is index.html file where is tag
The Clinical Staff Master Data Management (CSMDM) system is a full-stack healthcare integration application built on InterSystems IRIS for Health. It centralizes and standardizes clinical staff metadata into a single authoritative repository, exposed through RESTful CRUD APIs and reusable backend methods.
The platform eliminates fragmented lookup tables and hardcoded mappings that commonly cause errors in HL7 and FHIR integration workflows, ensuring data consistency and interface reliability.
According to the Documentation EnsLib.Workflow.TaskRequest has the following fields...
I want to be able to capture the Source, Session ID, and any other Identifiers outside of the Error so it will show up on the Task List.
I am struggling how to build a csp template for me to be able to capture additional fields to send to the Workflow
I would like to share with you a little trick to customize how messages are displayed in the Message Viewer. In particular, how you can display messages as JSON (instead of the default XML representation).
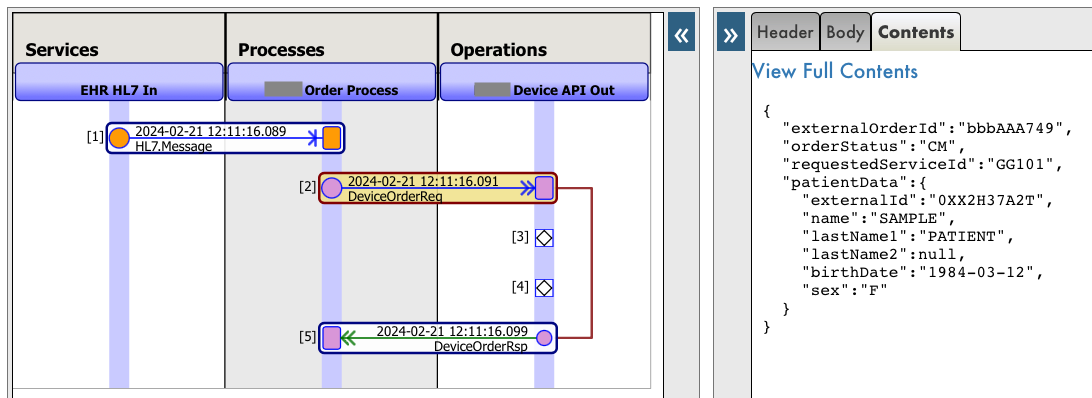
Messages are objects that are used to communicate interoperability productions components. In my example I have defined a message that later I serialize as JSON to send to an external API. This message is defined as a regular message and also as a %JSON.Adaptor so I can export / import directly to or from JSON.
Class interop.msg.DeviceOrderReq Extends (Ens.Request, %JSON.Hello, thanks for your time reading this question.
We are receiving each day, alerts from one of our four Production nodes. It always has the same text:
[InterSystems IRIS SEVERE ERROR gchciris4.canariasalud:ENSEMBLE] [Utility.Event] [SYSTEM MONITOR] CSPGatewayLatency(127.0.0.1:443) Alert: CSPGatewayLatency = 5001.304, 5001.233, 5000.964 (Max value is 2000).
We have looked for it in the documentation here:
https://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?
I have an API set up in IRIS which is secured using an IRIS authentication service, so there is a bearer token being passed down in the request header.
I've already set
Given the code below, I need help with getting the collected column widths from the Demo.Configuration table and stored in the columnWidths zne page property. As I understand it, I should be able to retrieve it using zenPage.columnWidths in the setColumnWidths or dgRender clientMethods but the alert is showing that it cannot be retrieved as it shows a value of Null. Once I can retrieve those values, then I want to set the widths of the colmns of the dynaGrid according to the values in the ^Demo.Configuration table. The data pulled in from the CSV file that creates ^Demo.
I am trying to use upload.csp as a template for choosing a CDV file to process. I am calling it from a zen page using this:
controlStyle="width:500px; height:100px; font-size:1.5em;"
onclick="zenPage.importExtract();"/>
{
// Open CSP popup to upload the CSV
//alert('importExtract called.');
zenPage.launchPopupWindow(zenLink('Upload.
I am trying to get the value of a Submit button on a CSP object page.
<input type="Submit" value="Assign" name="action" id="action">
I tried getting it thru $GET(%Request.Data("action")), but it throws an Undefined error. Isnt $GET supposed to handle it if its undefined anyway?
How do I get the "value" of the button pushed when the form is set to POST?
Hi,
How do I create CSP page in IIS to be loaded from the class?
Im able to open my index.html but I have class webapp.init.cls which extends %CSP.Page which should generate html. If I write localhost/myapp/webapp.init.cls I just got an error Invalid action.
In IIS Handler Mappings I did setup for *.cls and *.csp files.
I followed this
https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cl…
When I created index.csp my IIS just return NOT FOUND. With the old APACHE server I had no issue with all, but Im trying to migrate to IIS.
I need to remove multiple languages from the language selection drop down which appears at top of Navigation app top bar. I need to keep only English.
Is there any way I can do that?
Or I can completly remove the language option?
Good morning dear community,
This is like my first post in this community. Let's see how this turns out.
I have a question about the Intersystems Kubernetes Operator and the deployment of the webgateways.
I am responsible for the hosting and deployment of the apps. For the future we are planning to host our application in a kubernetes cluster. I am using the IKO for this.
I am using webgateways, for external access as separate pods. And sidecar containers for internal access, like the management portal.
My current Problem is the configuration of the webgateways.
Hello, I want to create PDF from HTML source. I found pandoc. I installed pandoc on IRIS container image. I created Interoperability production. I have setup REST service to receive HTML file in request body. I call pandoc command pandoc -o output.pdf input.html from a BPL process. I copy output.pdf file stream into response body. I save the response at the source. I get a file named output.pdf but it does not load in Acrobat. I suspect I am doing something wrong with headers (accept-encoding?) or maybe do I need to base64 encode the pdf file to transfer it via REST?
Hello Community,
I'm a beginner and currently working on a project to convert CCDA files to FHIR using InterSystems IRIS. I have developed a web form to upload CCDA files, and I'm attempting to convert the uploaded CCDA files to FHIR. However, I am encountering an issue where the conversion process results in an empty entry.
Here's the Output it displays on HTML page:
Size of CCDA Stream: 74152
vR4
{"resourceType":"Bundle","type":"transaction","entry":[]}Here is my code: CCDtoFHIR.csp
<!Hello,
First of all thanks for your help.
We have the following scenario: some responses include special characters as ">" and "<" which are being put inside a property defined as:
So then, when we observe the LOG SOAP it shows that the Target System replies to the ESB as follows:
➡️ <PAC_PROBLEMAS>46807#278.
Hi,
I have over 36 years of experience developing solutions with MUMPS and Cache. Additionally, I also develop in Python and HTML.
I have no experience in Vista or PSL, but I would be very happy to have the opportunity to learn it. I'm looking for a job opportunity.
Best,
Carlos
Hi, Community!
Since this article is an overview of Flask Login, let's begin with Flask Introduction!
In the realm of web development, Python has emerged as a formidable force, offering its versatility and robustness to create dynamic and scalable applications. For that reason, tools and services compatible with this language are in demand these days. Flask is a lightweight and easy-to-use web framework for Python. It stands out as a lightweight and user-friendly option. Its simplicity and flexibility have made it a popular choice for developers, particularly for creating smaller-scale applications. It is based on the Werkzeug toolkit and provides a simple but powerful API for building web applications.
Unlike its full-stack counterparts, Flask provides a core set of features, focusing on URL routing, template rendering, and request handling. This minimalist approach makes Flask lightweight and easy to learn, allowing developers to build web applications quickly and without the burden of unnecessary complexity.
Hi
Is there any build in solution to convert HTML to PDF? if yes please how
Thank you
Hi Community,
This article is a continuation of my article about Getting to know Python Flask Web Framework
In this article, we will cover the basics of topics listed below:
So, let's begin.
Hi Community,
In this article, I will introduce Python Flask Web Framework. Together we will create a minimal web application to connect to IRIS and get data from it.
Below you can find the steps we will need to follow:
So Let's start with step 1
Flask is a small and lightweight Python web framework that provides useful tools and features that make creating web applications in Python easier. It gives developers flexibility and is a more accessible framework for new developers since it allows to build a web application quickly using only a single Python file. Flask is also extensible and doesn’t requires a particular directory structure or complicated boilerplate code before getting started.
For more details please view Flask Documentations.png)
Does anyone have any pointers or maybe familiarity of making Email templates in Objectscript?
I'm currently trying to implement Televisits with our system and am needing to send an email to the patient. I'd like to make it a nicer looking email which will require a good amount of inline CSS. I currently have a method, but is very much a sore sight for the eyes.
I was wondering if there was a way I could use Embedded HTML and pass that into the DO msg.TextData.Write command with the ##class(%Net.MailMessage)?
We are experience this with our own web app and even the demo/template here: intersystems-community/iris-fullstack-template: This template shows you how to build, test and deploy a simple full-stack application using InterSystems IRIS REST API (github.com)
When changes are made to CSS or HTML files, we can see the changes are saved to file in the Docker container by visiting the command line. However, after refreshing, clearing cache, etc. the changes don't appear on the web application in the browser. Viewing the source css in the browser, we see it's the old file.
I am referencing the documentation here: https://docs.intersystems.com/ens201815/csp/docbook/DocBook.UI.Page.cls…
I have embedded html within a <script language="cache" runat="server"> block. Within that I'm defining and using a macro, but it doesn't display at all. Something like:
<script language="cache" runat="server">
s stringData=obj.I started to get the following error when trying to save HTML and js files after editing in VSCode. This used to work fine, csp still works too.
ERROR #16006: Document 'xxx.html' name is invalid
Is there now a setting that I am missing? I did check but saw nothing that was obviously wrong.
Job Title: Support Engineer / Developer
Location: Sydney, Australia
Salary: Salary negotiable depending on skills and experience
Job Type: Permanent, Full time following 3 months probation
Integrated Software Solutions (ISS) is a software development company providing mainly laboratory health solutions for over 30 years to some of the most well respected hospitals/organisations around the world. Clients include laboratories in United Kingdom, United Arab Emirates, Canada and Australia.
Hello
Is there anyone who can convert this code From PHP TO CACHE in File (.mac)?
this is my function is empty :/
thank you all
.png)
| <?php $output_dir = "uploads/"; if(isset($_FILES["myfile"])) { $ret = array(); // This is for custom errors; /* $custom_error= array(); $custom_error['jquery-upload-file-error']="File already exists"; echo json_encode($custom_error); die(); */ $error =$_FILES["myfile"]["error"]; //You need to handle both cases //If Any browser does not support serializing of multiple files using FormData() if(! |
This concept may be known to some, but I just found it very useful and I would like to share as it may help someone else.
If you are working with CSP or Zen you sometimes come across the need to use embedded JavaScript. Suppose you are working with some loops, which use < or > as shown in example below:
&js<
var test = document.getElementById('seTest');
for (var i = 0; i < test.options.length; i++) {
// Do Something here with my test.options[i].
or "So you just got yelled at by your boss, for sending him an unformatted Hello World webpage"
Our previous lesson ended with us serving a Message value obtained from a Caché REST service to the client, using Angular as a runtime. While there is a lot of moving parts involved in this process, the page is not especially exciting at the moment. Before we can start adding new features, we should take a step back and review our tools.
This tutorial is using the JSON functionality built into 2016.2+ versions of Caché. This functionality is partially available in 2016.
Hi folks!
Is there any templating engine for ObjectScript similar to Jinja?
Or is there any way to use csp's built-in tools to do this?
Ideally, I want to input the template and data into the function and get the ready to use html in the output.
I want to convert the image to base64.
I have only a remote image URL.
please suggest the solution with allow cors origin.