Clear filter
Announcement
Anastasia Dyubaylo · Jun 24, 2020
Hi Community!
We are pleased to invite all the developers to the upcoming InterSystems AI Programming Contest Kick-Off Webinar! The topic of this webinar is dedicated to the InterSystems IRIS AI Programming Contest.
On this webinar, we will talk and demo how to use IntegratedML and PythonGateway to build AI solutions using InterSystems IRIS.
Date & Time: Monday, June 29 — 11:00 AM EDT
Speakers: 🗣 @tomd, Product Specialist - Machine Learning, InterSystems 🗣 @Eduard.Lebedyuk, Sales Engineer, InterSystems
➡️ IntegratedML is a new technology Introduced in InterSystems IRIS which you can use with InterSystems IRIS 2020.2 Advanced Analytics Preview release. IntegratedML:
Gives users the ability to create, train, and deploy powerful models from simple SQL syntax without requiring data scientists.
Wraps "best of breed" open source and proprietary "AutoML" frameworks including DataRobot.
Focuses on easy deployment to IRIS, so you can easily add machine learning to your applications.
Learn more in IntegratedML Resource Guide.
Also, you can use with IntegratedML template.
➡️ PythonGateway is an addon to InterSystems IRIS which gives you the way to use Python in InterSystems IRIS environment:
Execute arbitrary Python code.
Seamlessly transfer data from InterSystems IRIS into Python.
Build intelligent Interoperability business processes with Python Interoperability Adapter.
Save, examine, modify and restore Python context from InterSystems IRIS.
Learn more about Python Gateway.
Also, you can use the Python Gateway template, which includes IntegratedML too.
So!
We will be happy to talk to you at our webinar!
➡️ REGISTER TODAY! Today! Don't miss our webinar!
➡️ JOIN US HERE ⬅️ Hey Developers!
Now this webinar recording is available on InterSystems Developers YouTube Channel:
Enjoy watching this video!
And big applause to @tomd and @Eduard.Lebedyuk! 👏🏼
Announcement
Stefan Wittmann · Jul 20, 2020
Preview releases are now available for the 2020.3 version of InterSystems IRIS, IRIS for Health, and IRIS Studio!
The build number for these releases is 2020.3.0.200.0.
Container images, components, and evaluation license keys are available via the WRC's preview download site.
Community Edition containers can also be pulled from the Docker store using the following commands:
docker pull store/intersystems/iris-community:2020.3.0.200.0
docker pull store/intersystems/iris-community-arm64:2020.3.0.200.0
docker pull store/intersystems/irishealth-community:2020.3.0.200.0
docker pull store/intersystems/irishealth-community-arm64:2020.3.0.200.0
InterSystems IRIS Data Platform 2020.3 makes it even easier to develop and deploy real-time, machine learning-enabled applications that bridge data and application silos. It has many new capabilities including:
Enhancements to the deployment and operations experience, both in the cloud and on-prem:
IKO - configuring a Kubernetes cluster just got way easier with the new InterSystems Kubernetes Operator (IKO)
ICM adds support for IAM deployments
Asynchronous mirroring support for sharded clusters
Work Queues are now manageable from the System Management Portal
Enhancements to the developer experience, including new facilities, higher performance, and compatibility with recent versions of key technology stacks:
Python Gateway - invoke Python code snippets for your analytics and machine-learning related tasks
Support for JDBC and Java Gateway reentrancy
.NET Core 2.1 support for the .NET Gateway
XEP adds support for deferred indexing
Support for Spark 2.4.4
InterSystems IRIS for Health 2020.3 includes all of the enhancements of InterSystems IRIS. In addition, this release includes
APIs for sending and receiving FHIR request/response messages, for performing client-side FHIR operations.
eGate support in the HL7 Migration Tooling
Documentation can be found here:
InterSystems IRIS 2020.3 documentation and release notes
InterSystems IRIS for Health 2020.3 documentation and release notes
InterSystems IRIS Studio 2020.3 is a standalone development image supported on Microsoft Windows. It works with InterSystems IRIS and IRIS for Health version 2020.3 and below, as well as with Caché and Ensemble.
As this is a CD release, it is only available in OCI (Open Container Initiative) a.k.a. Docker container format. Container images are available for OCI compliant run-time engines for Linux x86-64 and Linux ARM64, as detailed in the Supported Platforms document.
Give it a try and let us know what you think. Thanks,
Stefan Thanks, Stefan!
What about integratedML image store/intersystems/iris-aa-community:2020.3.0AA.331.0 released a while ago. Was it updated too? Hi Evgeny,
no. The Advanced Analytics image is staying on build 331. Docker Images with IRIS 2020.3 and ZPM 0.2.4:
intersystemsdc/iris-community:2020.3.0.200.0-zpm
intersystemsdc/iris-community:2020.2.0.204.0-zpm
intersystemsdc/irishealth-community:2020.3.0.200.0-zpm
intersystemsdc/irishealth-community:2020.2.0.204.0-zpm
intersystemsdc/iris-aa-community:2020.3.0AA.331.0-zpm
And to launch IRIS do:
docker run --name my-iris -d --publish 9091:51773 --publish 9092:52773 intersystemsdc/iris-community:2020.3.0.200.0-zpm
docker run --name my-iris -d --publish 9091:51773 --publish 9092:52773 intersystemsdc/iris-community:2020.2.0.204.0-zpm
docker run --name my-iris -d --publish 9091:51773 --publish 9092:52773 intersystemsdc/irishealth-community:2020.3.0.200.0-zpm
docker run --name my-iris -d --publish 9091:51773 --publish 9092:52773 intersystemsdc/irishealth-community:2020.2.0.204.0-zpm
docker run --name my-iris -d --publish 9091:51773 --publish 9092:52773 intersystemsdc/iris-aa-community:2020.3.0AA.331.0-zpm
And for terminal do:
docker exec -it my-iris iris session IRIS
and to start the control panel:
http://localhost:9092/csp/sys/UtilHome.csp
Python Gateway - invoke Python code snippets for your analytics and machine-learning related tasks
Are there any docs or guides on that feature?
Announcement
Anastasia Dyubaylo · Feb 24, 2021
Hi Community,
See how X12 SNIP validation can be used in InterSystems IRIS data platform and how to create a fully functional X12 mapping in a single data transformation language (DTL):
⏯ Building X12 Interfaces in InterSystems IRIS
Subscribe to InterSystems Developers YouTube and stay tuned!
Announcement
Nikolay Solovyev · Apr 8, 2021
We released a new version of ZPM (Package Manager)
New in ZPM 0.2.14 release:
Publishing timeout
Embedded vars usage in module parameters
Package installation from Github repo
Transaction support for install, load and publish.
See the details below.
New configuration setting - publish timeout zpm:USER>config set PublishTimeout 120Use this setting if you are unable to publish the package due to a bad connection or other problems
Support embedded vars in Default values in Module.xml <Default Name="MyDir" Value="${mgrdir}MySubDir"></Default> Thanks to @Lorenzo.Scalese for the suggested changes
Load packages from repo (git) zpm:USER>load https://github.com/intersystems-community/zpm-registrygit must be installed
Transactions Now Load, Install, Publish commands are executed in a transaction, which allows you to be sure that no changes will remain in the system in case of problems during these operations
Many bug fixes and improvements
All Docker images https://github.com/intersystems-community/zpm/wiki/04.-Docker-Images are updated and include ZPM 0.2.14
To launch IRIS do:
docker run --name my-iris -d --publish 9091:51773 --publish 9092:52773 intersystemsdc/iris-community:2020.4.0.524.0-zpm
docker run --name my-iris -d --publish 9091:51773 --publish 9092:52773 intersystemsdc/iris-community:2020.3.0.221.0-zpm
docker run --name my-iris -d --publish 9091:51773 --publish 9092:52773 intersystemsdc/iris-ml-community:2020.3.0.302.0-zpm
docker run --name my-iris -d --publish 9091:51773 --publish 9092:52773 intersystemsdc/irishealth-community:2020.4.0.524.0-zpm
docker run --name my-iris -d --publish 9091:51773 --publish 9092:52773 intersystemsdc/irishealth-community:2020.3.0.221.0-zpm
Robert Thanks @Nikolay.Soloviev!
How to use load "github repo" feature using docker container? It says there is no git inside. in DockerFile
USER root## add gitRUN apt update && apt-get -y install git This works, thank you, Robert!
Announcement
Anastasia Dyubaylo · Apr 6, 2021
Hi Community,
Find out how to work with FHIR profiles and conformance resources when building FHIR applications on InterSystems IRIS for Health:
⏯ Working with FHIR Profiles in InterSystems IRIS for Health
👉🏼 Subscribe to InterSystems Developers YouTube.
Enjoy and stay tuned!
Question
Maik Gode · Jun 30, 2020
Hey,
I am pretty new to Docker and everything around that. I installed the container image from DockerHub and followed the instructions (https://hub.docker.com/_/intersystems-iris-data-platform/plans/222f869e-567c-4928-b572-eb6a29706fbd?tab=instructions). Everything is working fine except for the part where I want to change the default password.
I followed the instructions from this article (https://community.intersystems.com/post/using-intersystems-iris-containers-docker-windows) and the result was:
docker run --name iris3 --detach --publish 9091:51773 --publish 9092:52773 --volume C:\Users\user1\Desktop\TL5\DockerProjekt\warenverwaltung\container\IRISDataPlatform\password:/external 92ecaf86671c --before "cp /external/password.txt /external/password_copied.txt && /usr/irissys/dev/Cloud/ICM/changePassword.sh /durable/password_copied.txt"
The problem was that "changePassword.sh" doesnt exist inside the container. So I deleted the --before part to start the container and get inside it. I followed the path and saw that there are just "changePasswordHash.sh" and "changePasswordCSP.sh". Using "changePasswordCSP.sh" resulted in a permission denied error, but "changePasswordHash.sh" seems to work - The container is up and running and i am able to open the management portal.
The next problem is that I cant login with my password written in password.txt. I just typed "admin" in password.txt but when I try to login with
Username: _SYSTEM
PW: admin
it fails. Same for
Username: Admin
PW: admin
Even the login via _SYSTEM and SYS isnt working anymore.
Do you know what I am doing wrong?
Info: 92ecaf is my Container Image ID becauer I used a Dockerfile to build a new image for testing. Also i am using a Windows Machine with Docker Desktop installed Hi Maik,
changePassword.sh is still in the container, but its location has moved. It is in the PATH for your container, so if you delete the absolute-path portion and use "changePassword.sh /durable/password_copied.txt" you should be up and running.
changePasswordHash.sh is an internal tool and we don't recommend customers use it.
Hope this helps.
Announcement
Anastasia Dyubaylo · Aug 7, 2020
Hi Community!
We are pleased to invite all the developers to the upcoming InterSystems IRIS for Health FHIR Contest Kick-Off Webinar! The topic of this webinar is dedicated to the FHIR Programming Contest.
On this webinar, we will talk and demo how to use the IRIS-FHIR-Template to build FHIR solutions using InterSystems IRIS for Health.
Date & Time: Tuesday, August 11 — 11:00 AM EDT
Speakers: 🗣 @Evgeny.Shvarov, InterSystems Developer Ecosystem Manager🗣 @Guillaume.Rongier7183, InterSystems Sales Engineer🗣 @Patrick.Jamieson3621, InterSystems Product Manager - Health Informatics Platform
What awaits you at this webinar?
Demo the typical scenarios of FHIR usage with InterSystems IRIS for Health
Building FHIR solutions using FHIR contest template
Answering questions about FHIR
So!
We will be happy to talk to you at our webinar!
✅ JOIN THE KICK-OFF WEBINAR! Today! Don't miss our webinar!
➡️ JOIN US HERE ⬅️ Hey Developers!
The recording of this webinar is available on InterSystems Developers YouTube! Please welcome:
⏯ InterSystems IRIS for Health FHIR Contest Kick-Off Webinar
Big applause to all the speakers: @Patrick.Jamieson3621, @Evgeny.Shvarov and @Guillaume.Rongier7183! 👏🏼
And thanks to everyone for joining our webinar!
Article
Alexey Maslov · Oct 20, 2020
As we all well know, InterSystems IRIS has an extensive range of tools for improving the scalability of application systems. In particular, much has been done to facilitate the parallel processing of data, including the use of parallelism in SQL query processing and the most attention-grabbing feature of IRIS: sharding. However, many mature developments that started back in Caché and have been carried over into IRIS actively use the multi-model features of this DBMS, which are understood as allowing the coexistence of different data models within a single database. For example, the [HIS qMS](https://openexchange.intersystems.com/package/HIS-qMS) database contains both semantic relational (electronic medical records) as well as traditional relational (interaction with PACS) and hierarchical data models (laboratory data and integration with other systems). Most of the listed models are implemented using [SP.ARM](https://openexchange.intersystems.com/company/SP-ARM)'s qWORD tool (a mini-DBMS that is based on direct access to globals). Therefore, unfortunately, it is not possible to use the new capabilities of parallel query processing for scaling, since these queries do not use IRIS SQL access.
Meanwhile, as the size of the database grows, most of the problems inherent to large relational databases become right for non-relational ones. So, this is a major reason why we are interested in parallel data processing as one of the tools that can be used for scaling.
In this article, I would like to discuss those aspects of parallel data processing that I have been dealing with over the years when solving tasks that are rarely mentioned in discussions of Big Data. I am going to be focusing on the technological transformation of databases, or, rather, technologies for transforming databases.
It's no secret that the data model, storage architecture, and software and hardware platform are usually chosen at the early stages of system development, often when the project is still far from completion. However, some time will pass, and it is quite often the case when several years after the system was deployed, the data needs to be migrated for one reason or another. Here are just a few of the commonly encountered tasks (all examples are taken from real life):
1. A company is planning to go international, and its database with 8-bit encoding must be converted to Unicode.
2. An outdated server is being replaced with a new one, but it is either impossible to seamlessly transfer journals between servers (using Mirroring or Shadowing IRIS system features) due to licensing restrictions or lack of capabilities to meet existing needs, such as, for example, when you are trying to solve task (1).
3. You find that you need to change the distribution of globals among databases, for example, moving a large global with images to a separate database.
You might be wondering what is so difficult about these scenarios. All you need to do is stop the old system, export the data, and then import it into the new system. But if you are dealing with a database that is several hundred gigabytes (or even several terabytes) in size, and your system is running in 7x24 mode, you won't be able to solve any of the mentioned tasks using the standard IRIS tools.
## Basic approaches to task parallelization
### "Vertical" parallelization
Suppose that you could break a task down into several component tasks. If you are lucky, you find out that you can solve some of them in parallel. For example,
- Preparing data for a report (calculations, data aggregation…)
- Applying style rules
- Printing out reports
can all be performed at the same time for several reports: one report is still in the preparation phase, another is already being printed out at the same time, etc. This approach is nothing new. It has been used ever since the advent of batch data processing, that is, for the last 60 years. However, even though it is not a new concept, it is still quite useful. However, you will only realize a noticeable acceleration effect when all subtasks have a comparable execution time, and this is not always the case.
### "Horizontal" parallelization
When the order of operations for solving a task consists of iterations that can be performed in an arbitrary order, they can be performed at the same time. For example:
- Contextual search in the global:
- You can split the global into sub-globals ($order by the first index).
- Search separately in each of them.
- Assemble the search results.
- Transferring the global to another server via a socket or ECP:
- Break the global into parts.
- Pass each of them separately.
Common features of these tasks:
- Identical processing in subtasks (down to sharing the same parameters),
- The correctness of the final result does not depend on the order of execution of these subtasks,
- There is a weak connection between the subtasks and the "parent" task only at the level of result reporting, where any required postprocessing is not a resource-intensive operation.
These simple examples suggest that horizontal parallelism is natural for data transformation tasks, and indeed, it is. In what follows, we will mainly focus on this type of parallel processing.
## "Horizontal" parallelization
### One of the approaches: MapReduce
MapReduce is a distributed computing model that was introduced by [Google](https://ru.bmstu.wiki/Google_Inc.). It is also used to execute such operations to process large amounts of information at the same time. Popular open source implementations are built on a combination of [Apache Hadoop](https://ru.bmstu.wiki/Apache_Hadoop) ([https://ru.bmstu.wiki/Apache\_Hadoop](https://ru.bmstu.wiki/Apache_Hadoop)) and [Mahout](https://ru.bmstu.wiki/Apache_Mahout)[https://ru.bmstu.wiki/Apache\_Mahout](https://ru.bmstu.wiki/Apache_Mahout).
Basic steps of the model: [Map](https://ru.bmstu.wiki/index.php?title=Map&action=edit&redlink=1) (distribution of tasks between handlers), the actual processing, and [Reduce](https://ru.bmstu.wiki/index.php?title=Reduce&action=edit&redlink=1) (combining the processing results).
For the interested reader who would like to know more, I can recommend the series of articles by Timur Safin on his approach to creating the MapReduce tool in IRIS/Caché, which starts with [Caché MapReduce - an Introduction to BigData and the MapReduce Concept (Part I)](https://community.intersystems.com/post/cach%C3%A9-mapreduce-introduction-bigdata-and-mapreduce-concept).
Note that due to the "innate ability" of IRIS to write data to the database quickly, the Reduce step, as a rule, turns out to be trivial, as in the [distributed version of WordCount](https://community.intersystems.com/post/cach%C3%A9-mapreduce-putting-it-all-together-%E2%80%93-wordcount-example-part-iii#comment-14196). When dealing with database transformation tasks, it may turn out to be completely unnecessary. For example, if you used parallel handlers to move a large global to a separate database, then we do not need anything else.
### How many servers?
The creators of parallel computing models, such as MapReduce, usually extend it to several servers, the so-called data processing nodes, but in database transformation tasks, one such node is usually sufficient. The fact of the matter is that it does not make sense to connect several processing nodes (for example, via the Enterprise Cache Protocol (ECP)), since the CPU load required for data transformation is relatively small, which cannot be said about the amount of data involved in processing. In this case, the initial data is used once, which means that you should not expect any performance gain from distributed caching.
Experience has shown that it is often convenient to use two servers whose roles are asymmetric. To simplify the picture somewhat:
- The source database is mounted on one server (*Source DB*).
- The converted database is mounted on the second server (*Destination DB*).
- Horizontal parallel data processing is configured only on one of these servers; the operating processes on this server are the *master* processes to
- the processes running on the second server, which are, in turn, the *slave* processes; when you use ECP, these are the DBMS system processes (ECPSrvR, ECPSrvW, and ECPWork), and when using a socket-oriented data transfer mechanism, these are the child processes of TCP connections.
We can say that this approach to distributing tasks combines horizontal parallelism (which is used to distribute the load within the master server) with vertical parallelism (which is used to distribute "responsibilities" between the master and slave servers).
## Tasks and tools
Let us consider the most general task of transforming a database: transferring all or part of the data from the source database to the destination database while possibly performing some kind of re-encoding of globals (this can be a change of encoding, change of collation, etc.). In this case, the old and new databases are local on different database servers. Let us list the subtasks to be solved by the architect and developer:
1. Distribution of roles between servers.
2. Choice of data transmission mechanism.
3. Choice of the strategy for transferring globals.
4. Choice of the tool for distributing tasks among several processes.
Let's take a bird's eye view of them.
### Distribution of roles between servers
As you are already well familiar with, even if IRIS is being installed with Unicode support, it is also able to mount 8-bit databases (both local and remote). However, the opposite is not true: the 8-bit version of IRIS will not work with a Unicode database, and there will be inevitable <WIDE CHAR> errors if you try to do so. This must be taken into account when deciding which of the servers – the source or the destination – will be the master if the character encoding is changed during data transformation. However, it is impossible here to decide on an ultimate solution without considering the next task, which is the
### Choice of data transmission mechanism
You can choose from the following options here:
1. If the license and DBMS versions on both servers allow the ECP to be used, consider ECP as a transport.
2. If not, then the simplest solution is to deal with both databases (the source and destination) locally on the destination system. To do this, the source database file must be copied to the appropriate server via any available file transport, which, of course, will take additional time (for copying the database file over the network) and space (to store a copy of the database file).
3. In order to avoid wasting time copying the file (at least), you can implement your mechanism for exchanging data between the server processes via a TCP socket. This approach may be useful if:
- The ECP cannot be used for some reason, e.g. due to the incompatibility of the DBMS versions serving the source and destination databases (for example, the source DBMS is of a very legacy version),
- Or: It is impossible to stop users from working on the source system, and therefore the data modification in the source database that occurs in the process of being transferred must be reflected in the destination database.
My priorities when choosing an approach are pretty evident: if the ECP is available and the source database remains static while it is transferred – 1, if the ECP is not available, but the database is still static – 2, if the source database is modified – 3. If we combine these considerations with master server choice, then we can produce the following possibility matrix:
| **Is the source DB static during transmission?** | **Is the ECP protocol available?** | **Location of the DB source** | **Master system** |
| --- | --- | --- | --- |
| Yes | Yes | Remote on the target system | Target |
| Yes | No | Local (copy) on the target system | Target |
| No | It does not matter, as we will use our mechanism for transferring data over TCP sockets. | Local (original) on the source system | Source|
### Choice of the strategy for transferring globals
At first glance, it might seem that you can simply pass globals one by one by reading the Global Directory. However, the sizes of globals in the same database can vary greatly: I recently encountered a situation when globals in a production database ranged in size between 1 MB and 600 GB. Let's imagine that we have nWorkers worker processes at our disposal, and there is at least one global ^Big for which it is true:
Size(^Big) > (Summary Size of All ^Globals) / nWorkers
Then, no matter how successfully the task of transferring the remaining globals is distributed between the working processes, the task that ends up being assigned the transfer of the ^Big global will remain busy for the remaining allocated part of the time and will probably only finish its task long after the other processes finish processing the rest of the globals. You can improve the situation by pre-ordering the globals by size and starting the processing with the largest ones first, but in cases where the size of ^Big deviates significantly from the average value for all globals (which is a typical case for the MIS qMS database):
Size(^Big) >> (Summary Size of All ^Globals) / nWorkers
this strategy will not help you much, since it inevitably leads to a delay of many hours. Hence, you cannot avoid splitting large global into parts to allow its processing using several parallel processes. I wish to emphasize that this task (number 3 in my list) turned out to be the most difficult among others being discussed here, and took most of my (rather than CPU!) time to solve it.
### Choice of the tool for distributing tasks among several processes
The way that we interact with the parallel processing mechanism can be described as follows:
- We create a pool of background worker processes.
- A queue is created for this pool.
- The initiator process (let's call it the _local manager_), having a plan that was prepared in advance in step 3, places _work units_ in the queue; as a rule, the _work unit_ comprises the name and actual arguments of a certain class method.
- The worker processes retrieve work units from the queue and perform processing, which boils down to calling a class method with the actual arguments that are passed to the work units.
- After receiving confirmation from all worker processes that the processing of all queued work units is complete, the local manager releases the worker processes and finalizes processing if required.
Fortunately, IRIS provides an excellent parallel processing engine that fits nicely into this scheme, which is implemented in the %SYSTEM.WorkMgr class. We will use it in a running example that we will explore across a planned series of articles.
In the next article, I plan to focus on clarifying the solution to task number 3 in more detail.
In the third article, which will appear if you will show some interest in my writing, I will talk about the nuances of solving task number 4, including, in particular, about the limitations of %SYSTEM.WorkMgr and the ways of overcoming them.
Awesome! Nice article. Very much looking forward to your views on %SYSTEM.WorkMgr, which has been getting a lot of attention to help us serve the most demanding SQL workloads from our customers. You'll also be able to monitor some of its key metrics such as active worker jobs and average queue length in SAM starting with 2021.1. Interesting article, Alexey!But we are still eagerly waiting for the 2nd part, when we should expect it? Thanks for your interest. I try to fulfill it ASAP.
Announcement
Anastasia Dyubaylo · May 15, 2020
Hey Developers,
We're pleased to invite you to join the next InterSystems IRIS 2020.1 Tech Talk: DevOps on June 2nd at 10:00 AM EDT!
In this InterSystems IRIS 2020.1 Tech Talk, we focus on DevOps. We'll talk about InterSystems System Alerting and Monitoring, which offers unified cluster monitoring in a single pane for all your InterSystems IRIS instances. It is built on Prometheus and Grafana, two of the most respected open source offerings available.
Next, we'll dive into the InterSystems Kubernetes Operator, a special controller for Kubernetes that streamlines InterSystems IRIS deployments and management. It's the easiest way to deploy an InterSystems IRIS cluster on-prem or in the Cloud, and we'll show how you can configure mirroring, ECP, sharding and compute nodes, and automate it all.
Finally, we'll discuss how to speed test InterSystems IRIS using the open source Ingestion Speed Test. This tool is available on InterSystems Open Exchange for your own testing and benchmarking.
Speakers:🗣 @Luca.Ravazzolo, InterSystems Product Manager 🗣 @Robert.Kuszewski, InterSystems Product Manager - Developer Experience
Date: Tuesday, June 2, 2020Time: 10:00 AM EDT
➡️ JOIN THE TECH TALK!
Additional Resources:
SAM Documentation
SAM InterSystems-Community Github repo
Docker Hub SAM
Hi Everyone,
We’ve had a presenter change for this Tech Talk. Please welcome @Robert.Kuszewski as a speaker at the DevOps Webinar!
In addition, please check the updated Additional Resources above.
Don't forget to register here! Tomorrow! Don't miss this webinar! 😉
PLEASE REGISTER HERE! I registered last week and I have gotten the reminder on Sunday. But I cannot get into the session at all - it loops back to the page to save to your calendar. This event will start in 1.5 hours My apologies for my human error - I have a new work schedule that I am still getting used to hi, is there a replay for this? Thx!
Announcement
Anastasia Dyubaylo · May 11, 2020
Hi Developers!
Enjoy watching the new video on InterSystems Developers YouTube and explore the basics of InterSystems Open Exchange Marketplace:
⏯ How to Publish an Application on InterSystems Open Exchange
In this video, presented by @Evgeny.Shvarov, you will learn:
➡️ How to publish a new application on Open Exchange
➡️ How to make a new release
➡️ How to change the description of the application
So!
Let the world know about your solutions – upload your apps to the Open Exchange Marketplace!
And stay tuned! 👍🏼 In addition, please take a look at these tutorial articles:
InterSystems Open Exchange: How to use it?
How to Publish an Application on InterSystems Open Exchange
How to Setup a Company
How to Publish a New Release of Your Application
How to Make Open Exchange Helpful For Your InterSystems Application
Stay tuned!
Announcement
Nikolay Solovyev · Jan 11, 2021
We released a new version of ZPM (Package Manager)
New in ZPM 0.2.10 release:
1) FileCopy
Added some improvements to already existing tag FileCopy
Example of module.xml
<?xml version="1.0" encoding="UTF-8"?>
<Export generator="Cache" version="25">
<Document name="test-binary.ZPM">
<Module>
<Name>test-binary</Name>
<Version>0.0.1</Version>
<Packaging>module</Packaging>
<SourcesRoot>src</SourcesRoot>
<FileCopy Name="lib" Target="${libdir}my-lib"/> <!-- Copies content of lib folder to target -->
<FileCopy Name="somefile.jar" Target="${libdir}my-lib"/> <!-- Copies just desired file to target -->
</Module>
</Document>
</Export>
Added aliases Target and Dest to attribute InstallDirectory
Supports files as well as directories, no wildcards, just folder content of which should be copied, or particular file
${libdir}, ${bindir} added, installdir/lib and installdir/bin respectively.
Using bindir in docker environments may cause to security issues during install. Using libdir works in this case, so, recommended way.
This should work (ending slash in Target is important)
<FileCopy Name="dsw/irisapp.json" Target="${cspdir}dsw/configs/"/>
And this should be the same
<FileCopy Name="dsw/irisapp.json" Target="${cspdir}dsw/configs/irisapp.json"/>
If the Name ends with a slash, it will copy it as a folder. During uninstall it will delete Target folder
<FileCopy Name="dsw/" Target="${cspdir}dsw/configs/"/>
And added support for packaging and uninstalling module. When the module uninstalled it correctly deletes previously copied files.
2) Invoke improvements
Don't need wrapper tag anymore
Added a few more attributes:
CheckStatus (Default: false), expects that invoked method returns %Status, and use it to check the status of installation.
Phase, (Default: Configure), the phase during which it should be executed
When, (Default: After), values: Before and After. To execute before or after the main execution for the phase
added support for variables, added ${verbose} variable
<Invoke Class="%EnsembleMgr" Method="EnableNamespace" Phase="Compile" When="Before" CheckStatus="true">
<Arg>${namespace}</Arg>
<Arg>${verbose}</Arg>
</Invoke>
Docker images with IRIS 2020.4 and 2020.3 and ZPM 0.2.10 are now available.
Tags:
intersystemsdc/iris-community:2020.4.0.524.0-zpm
intersystemsdc/iris-community:2020.3.0.221.0-zpm
intersystemsdc/iris-ml-community:2020.3.0.302.0-zpm
intersystemsdc/irishealth-community:2020.4.0.524.0-zpm
intersystemsdc/irishealth-community:2020.3.0.221.0-zpm
More info in documentation https://github.com/intersystems-community/zpm/wiki/04.-Docker-Images And to launch the image do:
docker run --name my-iris -d --publish 9091:51773 --publish 9092:52773 intersystemsdc/iris-community:2020.4.0.524.0-zpm
docker run --name my-iris -d --publish 9091:51773 --publish 9092:52773 intersystemsdc/iris-community:2020.3.0.221.0-zpm
docker run --name my-iris -d --publish 9091:51773 --publish 9092:52773 intersystemsdc/iris-ml-community:2020.3.0.302.0-zpm
docker run --name my-iris -d --publish 9091:51773 --publish 9092:52773 intersystemsdc/irishealth-community:2020.4.0.524.0-zpm
docker run --name my-iris -d --publish 9091:51773 --publish 9092:52773 intersystemsdc/irishealth-community:2020.3.0.221.0-zpm
Announcement
Anastasia Dyubaylo · Jan 11, 2021
Hey Community,
We're pleased to invite you to the InterSystems AI+ML Summit 2021, which will be held virtually from January 25 to February 4! Join us for a two-week event that ranges from thought leadership to technical sessions and even 1:1 “Ask the Expert” sessions.
The sessions will be in both German and English. And this summit is free to attend!
See details below:
Discover new perspectives. Actively shape the future.
According to Statista, an enormous amount of 74 zettabytes of data will be generated by the end of 2021. Without the help of artificial intelligence (AI) and machine learning (ML) technologies, this massive flood of information cannot be meaningfully channeled and transformed into value-added business processes.
That’s why you shouldn’t miss the virtual InterSystems AI + ML Summit 2021, where you'll learn everything you need to know about the current state of AI and ML in general and AI + ML with InterSystems in particular. The spectrum of topics ranges from "hot" AI trends to concrete use cases in different industries and interactive workshops. In the first week, we focus on AI and ML in healthcare, while in the second week we look at the topics from an industry-agnostic standpoint.
So, remember:
⏱ Time: Jan 25 - Feb 04, 2021
📍 Location: Online
✅ Registration: SAVE THE DATE
Join us to find out how you can successfully use the modern AI and ML technologies with InterSystems IRIS, IRIS for Health and HealthShare to create added value for you and your customers! Hi,
While registering I am getting German language. How can I get English one?
Thanks Unfortunately, the registration page does not provide a choice of a language other than German. ok Thanks what's the speaker's language? Is it English or German? German is the language of the conference, but some sessions are in English:
When is Artificial Intelligence Trustworthy?
Convergent Analytics
Making Machine Learning Actionable
Enriching Master Data Management product KanoMDM with AI/ML
Hi there,
I am from Sales Team China. Where could we download those videos? We would like to translate the subtitle and distribute to our partners and customers.
Thanks a lot and looking forward to your feedback!
Kind regards,
Jun Qian The recordings will be made available to all registrants on Friday this week.
Uwe Hering (uwe.hering at intersystems dot com) can send you the video files for subtitling / editing - please send him an email.
Article
Mihoko Iijima · Feb 2, 2021
Hello, everyone!
InterSystems IRIS has a menu called **Interoperability**.
It provides mechanisms to easily create system integrations (adapters, record maps, BPMs, data conversions, etc.) so different systems can be easily connected.
A variety of operations can be included in the data relay process, as examples we can cite: to connect systems that are not normally connected, data can be received (or sent) according to the specifications of the destination system. Also, information can be acquired and added from another system before sending the data. As well as, information can be acquired and updated from a database (IRIS or other).
In this series of articles, we will discuss the following topics while looking at sample code to help you understand how it works and what kind of development is required when integrating systems with Interoperability.
* How it works
* What a Production is
* Message
* Component Creation
* Business Operations
* Business Processes
* Business Services
First, let me introduce you to the case study we will be using in this series.
> A company operates a shopping site and is changing the order of displaying product information to match the seasons.However, some items sell well regardless of the season, while others sell at unexpected times, which does not match the current display rule of changing the order.Therefore, we looked into the possibility of changing the order of display to match the day's temperature instead of the season. It became necessary to survey the temperature of the purchased products at that time.Since an external Web API is available for checking weather information, we plan to collect the weather information at the time of purchase and register it in the later review database.
It’s very simple, but you need to use an “external Web API” to collect the information, and you need to combine the information obtained and the purchase information to register in the database.
Specific instructions will be discussed in a related article (not including the creation of a web site). Please take a look!
As for the "external Web API" that we are using this time, we are using OpenWeather's Current weather data.
(If you want to try it out, you need to register an account and get an API ID).
The following is the result of a GET request from a REST client (we will run this in the mechanism we will implement in Interoperability).
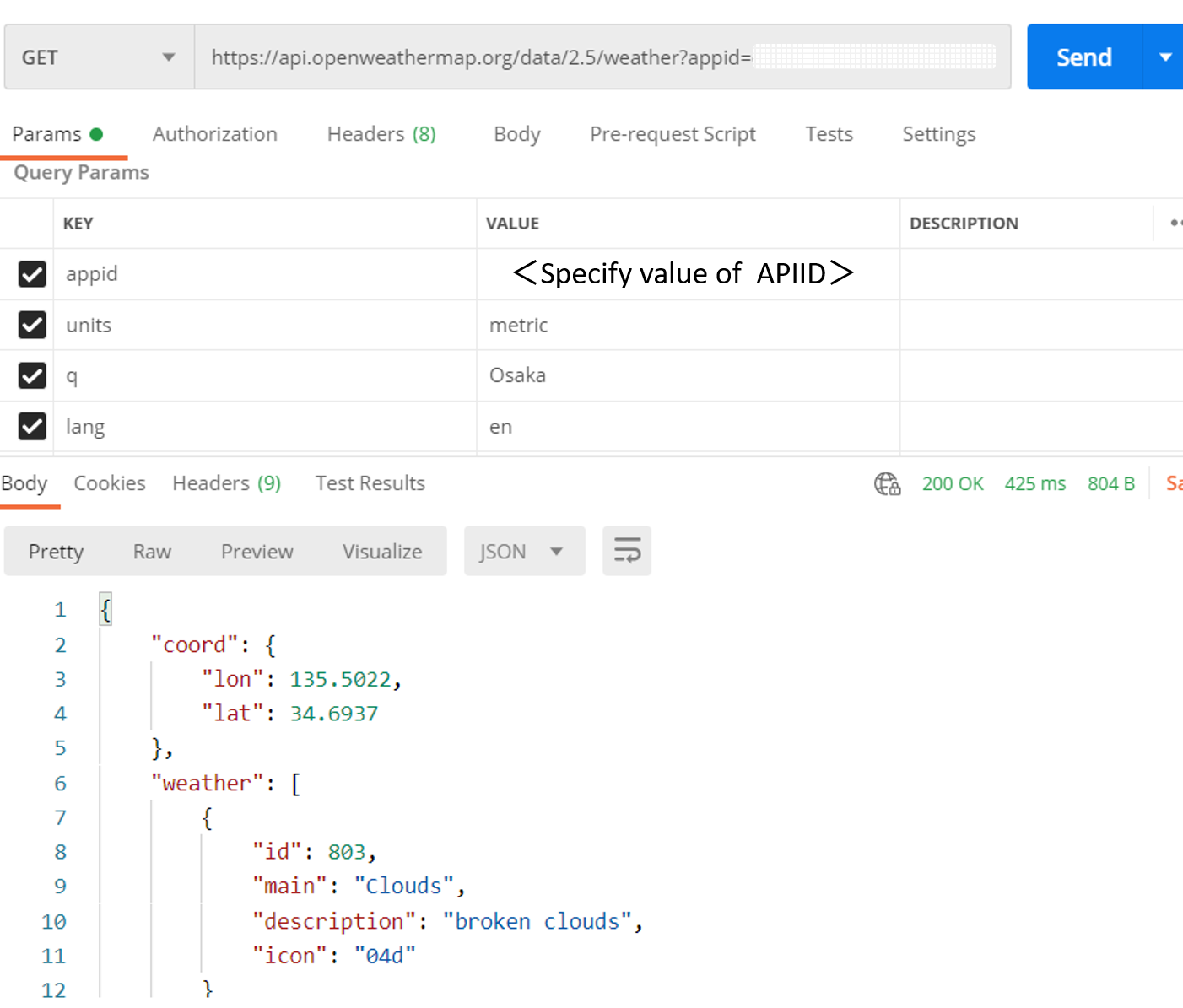
The JSON of the HTTP response is as follows:
```json
{
"coord": {
"lon": 135.5022,
"lat": 34.6937
},
"weather": [
{
"id": 803,
"main": "Clouds",
"description": "broken clouds",
"icon": "04d"
}
],
"base": "stations",
"main": {
"temp": 17.05,
"feels_like": 13.33,
"temp_min": 16,
"temp_max": 18,
"pressure": 1017,
"humidity": 55
},
"visibility": 10000,
"wind": {
"speed": 4.63,
"deg": 70
},
"clouds": {
"all": 75
},
"dt": 1611635756,
"sys": {
"type": 1,
"id": 8032,
"country": "JP",
"sunrise": 1611612020,
"sunset": 1611649221
},
"timezone": 32400,
"id": 1853909,
"name": "Osaka",
"cod": 200
}
```
In the next article, we will discuss how the Interoperability menu works for system integration.
[OpenWeather]: https://openweathermap.org/
Great article!
Announcement
Anastasia Dyubaylo · Apr 13, 2021
Hi Developers,
See how a FHIR implementation can be built in InterSystems IRIS for Health, leveraging both PEX and InterSystems Reports:
⏯ FHIR Implementation Patterns in InterSystems IRIS for Health
👉🏼 Subscribe to InterSystems Developers YouTube.
Enjoy and stay tuned!
Announcement
Anastasia Dyubaylo · May 30, 2021
Hi Developers,
Watch the execution of a speed test for a heavy-ingestion use case on InterSystems IRIS:
⏯ InterSystems IRIS Speed Test: High-Volume Ingestion
Try the full demo at https://github.com/intersystems-community/irisdemo-demo-htap
Speakers:
🗣 @Amir.Samary, InterSystems Director, Solution Architecture
🗣 @Derek.Robinson, InterSystems Senior Online Course Developer, InterSystems
Subscribe to InterSystems Developers YouTube and stay tuned!