QuinielaML - Data Capture with Embedded Python
We continue with the series of articles based on the QuinielaML application.
.png)
In today's article I will describe how to work with the Embedded Python functionality available in InterSystems products.
Embedded Python allows us to use Python as a programming language within our productions, being able to take advantage of all the features available in Python. Here you can expand information about it.
First of all, let's remember what the designer of the architecture of our project is like:
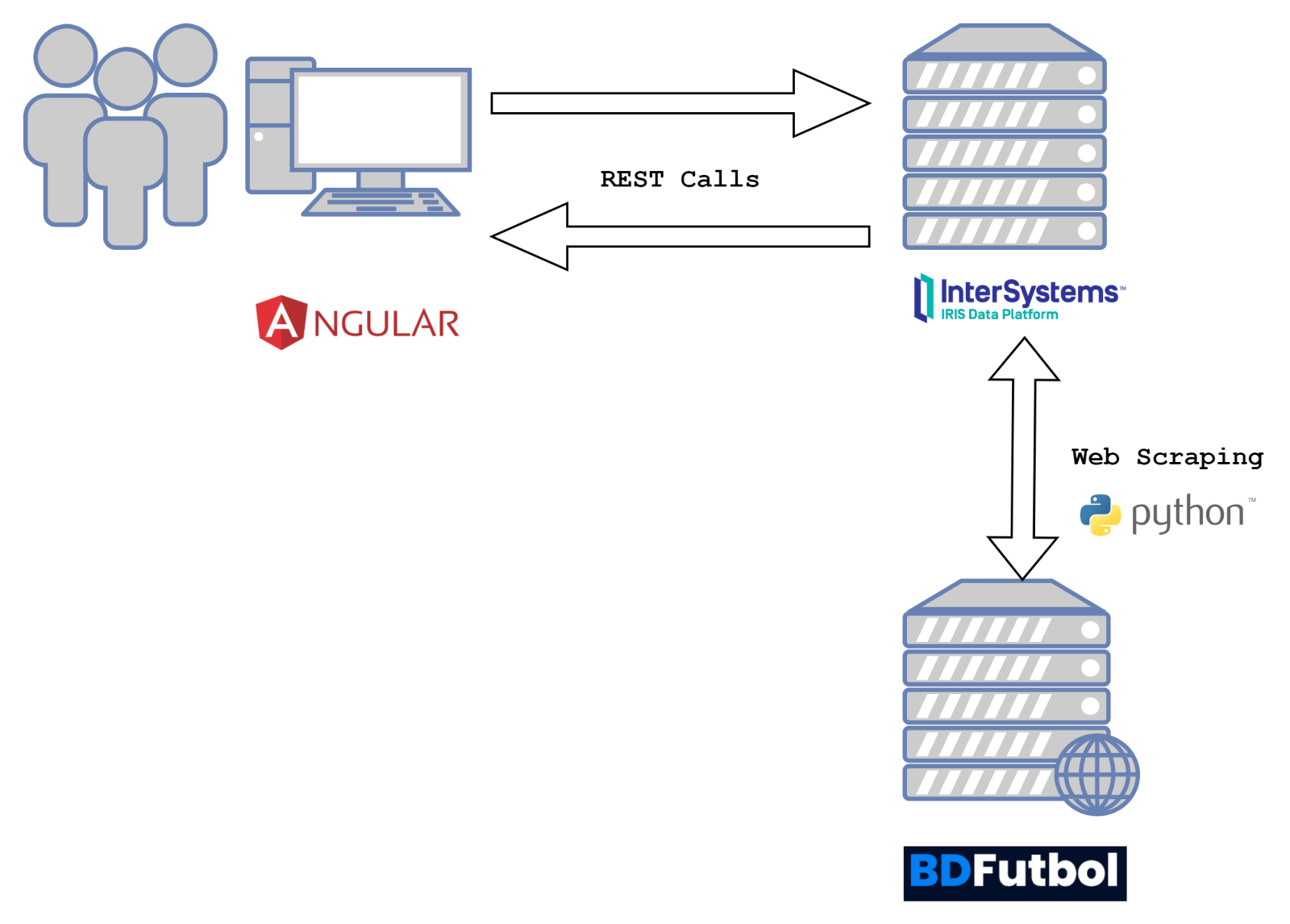
Problematic to solve
In our case, we need to obtain the historical results of the First and Second Division matches since the year 2000. We have found a BDFutbol website, which provides us with all this data, so web scraping seems the most appropriate solution.
What is web scraping?
Web scraping is the technique of automatically capturing information from web pages by simulating navigation in the same way that a human would.
In order to carry out web scraping we must look for two types of libraries, the first that allows us to invoke the URLs from which we want to obtain the information and the second that allows us to go through the captured web page and extract the necessary information. For the first case we will use the requests library, while for the second we have found beautifulsoup4, you can take a look at its documentation.
Embedded Python configuration with Docker
In order to make use of the Python libraries from our IRIS instance in Docker we must add the following commands in our Dockerfile:
RUN apt-get update && apt-get install -y python3
RUN apt-get update && \
apt-get install -y libgl1-mesa-glx libglib2.0-0With these commands we are installing Python in our container, then we will install the necessary libraries that we have registered in the requirements.txt file.
beautifulsoup4==4.12.2
requests==2.31.0To install it, it will be enough with the following command in our Dockerfile:
RUN pip3 install -r /requirements.txtYa tendríamos todo preparado en nuestro contenedor para utilizar las librerías de Python necesarias en nuestra producción.
IRIS Production configuration
The first step will be to configure in our class responsible for receiving calls from the frontend a specific method to manage data import requests:
Class QUINIELA.WS.Service Extends %CSP.REST
{
Parameter HandleCorsRequest = 0;
Parameter CHARSET = "utf-8";
XData UrlMap [ XMLNamespace = "https://www.intersystems.com/urlmap" ]
{
<Routes>
<Route Url="/getPrediction" Method="GET" Call="GetPrediction" />
<Route Url="/import" Method="GET" Call="ImportRawMatches" />
<Route Url="/getStatus/:operation" Method="GET" Call="GetStatus" />
<Route Url="/prepare" Method="GET" Call="PrepareData" />
<Route Url="/train" Method="GET" Call="TrainData" />
<Route Url="/getReferees" Method="GET" Call="GetReferees" />
<Route Url="/getTeams" Method="GET" Call="GetTeams" />
<Route Url="/saveMatch" Method="POST" Call="SaveMatch" />
<Route Url="/deleteMatch/:matchId" Method="DELETE" Call="DeleteMatch" />
<Route Url="/saveResult" Method="POST" Call="SaveResult" />
<Route Url="/getMatches/:division" Method="GET" Call="GetMatches" />
</Routes>
}Any call with a URL ending in /import will be handled from the ImportRawMatches method, let's see the method in more detail:
ClassMethod ImportRawMatches() As %DynamicObject
{
Try {
Do ##class(%REST.Impl).%SetContentType("application/json")
If '##class(%REST.Impl).%CheckAccepts("application/json") Do ##class(%REST.Impl).%ReportRESTError(..#HTTP406NOTACCEPTABLE,$$$ERROR($$$RESTBadAccepts)) Quit
set newRequest = ##class(QUINIELA.Message.OperationRequest).%New()
set newRequest.Operation = "Import"
set status = ##class(Ens.Director).CreateBusinessService("QUINIELA.BS.FromWSBS", .instance)
set response = ##class(QUINIELA.Message.ImportResponse).%New()
set response.Status = "In Process"
set response.Operation = "Import"
set status = instance.SendRequestAsync("QUINIELA.BP.ImportBPL", newRequest, .response)
if $ISOBJECT(response) {
Do ##class(%REST.Impl).%SetStatusCode("200")
return response.%JSONExport()
}
} Catch (ex) {
Do ##class(%REST.Impl).%SetStatusCode("400")
return ex.DisplayString()
}
}As we can see we are calling the BPL ImportBPL in an asynchronous way, in such a way that we avoid possible timeout problems. Let's take a look at the production layout:
.png)
Let's open ImportBPL and see how we manage the import of the matches:
.png)
In a first task we create a message that indicates the status of the import, then we invoke a Business Operation that will be in charge of cleaning the tables in charge of storing the match data, once the import has been completed and confirmed. success in the preparation of the tables we will move on to the part in which we will perform the web scraping:
.png)
As you can see in the task flow, we will asynchronously launch a call to the Business Operation QUINIELA.BO.ImportBO in which, using Python, we will retrieve the information on historical results. To speed up data retrieval we have divided the results retrieval into two asynchronous tasks, one for the First Division and one for the Second Division that will be executed in parallel.
Class Method to import data using Python
Next we are going to analyze the Class Method that is in charge of carrying out the Web scraping.
ClassMethod ImportFromWeb(division As %String) As %String [ Language = python ]
{
from os import path
from pathlib import PurePath
import sys
from bs4 import BeautifulSoup
import requests
import iris
directory = '/shared/files/urls'+division+'.txt'
responses = 1
with open(directory.replace('\\', '\\\\'), 'r') as fh:
urls = fh.readlines()
urls = [url.strip() for url in urls] # strip `\n`
for url in urls:
file_name = PurePath(url).name
file_path = path.join('.', file_name)
raw_html = ''
try:
response = requests.get(url)
if response.ok:
raw_html = response.text
html = BeautifulSoup(raw_html, 'html.parser')
for match in html.body.find_all('tr', 'jornadai'):
count = 0
matchObject = iris.cls('QUINIELA.Object.RawMatch')._New()
matchObject.Journey = match.get('data-jornada')
for specificMatch in match.children:
if specificMatch.name is not None and specificMatch.name == 'td' and len(specificMatch.contents) > 0:
match count:
case 0:
matchObject.Day = specificMatch.contents[0].text
case 1:
matchObject.LocalTeam = specificMatch.contents[0].text
case 2:
if specificMatch.div is not None and specificMatch.div.a is not None and specificMatch.div.a.contents is not None and len(specificMatch.div.a.contents) > 1:
matchObject.GoalsLocal = specificMatch.div.a.contents[0].text
matchObject.GoalsVisitor = specificMatch.div.a.contents[1].text
case 3:
matchObject.VisitorTeam = specificMatch.contents[0].text
case 5:
matchObject.Referee = specificMatch.contents[0].text
matchObject.Division = division
count = count + 1
if (matchObject.Day != '' and matchObject.GoalsLocal != '' and matchObject.GoalsVisitor != ''):
status = matchObject._Save()
except requests.exceptions.ConnectionError as exc:
print(exc)
return exc
return responses
}Let's see in detail the most relevant lines of this method.
- Importing the required libraries request, BeautifulSoup, and iris:
from bs4 import BeautifulSoup import requests import iris
- Invoking the URL and capturing its response in a variable:
response = requests.get(url) if response.ok: raw_html = response.text html = BeautifulSoup(raw_html, 'html.parser')
- Analysis and extraction of relevant data from each match and creation of a QUINIELA.Object.RawMatch type object that will be stored in the IRIS database:
for match in html.body.find_all('tr', 'jornadai'): count = 0 matchObject = iris.cls('QUINIELA.Object.RawMatch')._New() matchObject.Journey = match.get('data-jornada') for specificMatch in match.children: if specificMatch.name is not None and specificMatch.name == 'td' and len(specificMatch.contents) > 0: match count: case 0: matchObject.Day = specificMatch.contents[0].text case 1: matchObject.LocalTeam = specificMatch.contents[0].text case 2: if specificMatch.div is not None and specificMatch.div.a is not None and specificMatch.div.a.contents is not None and len(specificMatch.div.a.contents) > 1: matchObject.GoalsLocal = specificMatch.div.a.contents[0].text matchObject.GoalsVisitor = specificMatch.div.a.contents[1].text case 3: matchObject.VisitorTeam = specificMatch.contents[0].text case 5: matchObject.Referee = specificMatch.contents[0].text matchObject.Division = division count = count + 1 if (matchObject.Day != '' and matchObject.GoalsLocal != '' and matchObject.GoalsVisitor != ''): status = matchObject._Save()
As you can see, we have imported the IRIS Python library that allows us to use classes defined in our Namespace, in such a way that we can populate our database directly from the Python method. With this simple method we can now recover all the data we need in a simple and agile way.
This web scraping functionality can be very useful for integrations of closed systems in which no other way of interconnection is possible.
I hope that this functionality can be useful to you and if you have any questions, do not hesitate to write a comment.
Thank you for your attention!
Comments
I like it!
I wonder if this would work also for Horse Races or Roulette or BlackJack or Baccarat.
Just give me the URL to get the data and I'll do it!