Q&A Chatbot with IRIS and langchain
TL;DR
This article introduces using the langchain framework supported by IRIS for implementing a Q&A chatbot, focusing on Retrieval Augmented Generation (RAG). It explores how IRIS Vector Search within langchain-iris facilitates storage, retrieval, and semantic search of data, enabling precise and up-to-date responses to user queries. Through seamless integration and processes like indexing and retrieval/generation, RAG applications powered by IRIS enable the capabilities of GenAI systems for InterSystems developers.
A notebook and a complete Q&A chatbot application using the topics discussed here are provided to help readers to fix the concepts.
Table of contents:
- Langchain Q&A chatbot example
- What is RAG and its role in Q&A chatbots
- IRIS Vector search
- langchain-iris
- Using IRIS as the langchain vector store
- A deeper look on the whole process
- Final words
Langchain Q&A chatbot example
This article explores the langchain's Q&A chatbot example, focusing on its indexing and retrieval/generation components for building RAG applications. It details data loading, segmentation, and indexing, alongside retrieval and answer generation processes. You can find the original example here and an adaptation to use IRIS as its vector store by using Vector Search and langchain-iris here.
Note that in this article we are going to focus on explaining the concepts used by implementing the Q&A chatbot. So, you should to refer to those sources in order to get the full source code.
What is RAG and its role in Q&A chatbots
RAG, or Retrieval Augmented Generation, stands as a technique for enriching the knowledge base of Language Model (LLM) systems by integrating supplementary data beyond their initial training set. While LLMs possess the ability to reason across diverse topics, they are confined to the public data they were trained on up to a particular cutoff date. To empower AI applications to process private or more recent data effectively, RAG supplements the model's knowledge with specific information as required. This is an alternative way to fine tuning LLMs, which could be expensive.
Within the realm of Q&A chatbots, RAG plays a pivotal role in handling unstructured data queries, comprising two key components: indexing and retrieval/generation.
Indexing commences with the ingestion of data from a source, followed by its segmentation into smaller, more manageable chunks for efficient processing. These segmented chunks are then stored and indexed, often utilizing embeddings models and vector databases, ensuring swift and accurate retrieval during runtime.
During retrieval and generation, upon receiving a user query, the system generates an embedding vector using the same embedding model used in the indexing phase, and then retrieves pertinent data chunks from the index utilizing a retriever component. These retrieved segments are then passed to the LLM for answer generation.
Thus, RAG empowers Q&A chatbots to access and leverage both structured and unstructured data sources, thereby enhancing their capability to furnish precise and up-to-date responses to user queries through the utilization of embeddings models and vector databases as an alternative to LLM fine tuning.
IRIS Vector search
InterSystems IRIS Vector Search is a new feature which enables semantic search and generative AI capabilities within databases. It allows users to query data based on its meaning rather than its raw content, leveraging retrieval-augmented generation (RAG) architecture. This technology transforms unstructured data, like text, into structured vectors, facilitating efficient processing and response generation.
The platform supports the storage of vectors in a compressed and performant VECTOR type within relational schemas, allowing for seamless integration with existing data structures. Vectors represent the semantic meaning of language through embeddings, with similar meanings reflected by proximity in a high-dimensional geometric space.
By comparing input vectors with stored vectors using operations like dot product, users can algorithmically determine semantic similarity, making it ideal for tasks like information retrieval. IRIS also offers efficient storage and manipulation of vectors through dedicated VECTOR types, enhancing performance for operations on large datasets.
To utilize this capability, text must be transformed into embeddings through a series of steps involving text preprocessing and model instantiation. InterSystems IRIS supports seamless integration of Python code for embedding generation alongside ObjectScript for database interaction, enabling smooth implementation of vector-based applications.
You can check out the Vector Search documentation and usage examples here.
langchain-iris
In short, langchain-iris is the way to use IRIS Vector Search with the langchain framework.
InterSystems IRIS Vector Search aligns closely with langchain's vector store requirements. IRIS stores and retrieves embedded data, crucial for similarity searches. With its VECTOR type, IRIS supports storing embeddings, enabling semantic search over unstructured data and facilitating seamless document processing into the vector store.
By leveraging operations like dot product comparisons, IRIS facilitates algorithmic determination of semantic similarity, ideal for langchain's similarity search.
Thus, langchain-iris allows the development of RAG applications with langchain framework supported by InterSystems IRIS data platform. For more information on langchain-iris, check out here.
Using IRIS as the langchain vector store
In order to use IRIS as the vector storage to RAG application using langchain, you must first import langchain-iris, like this:
pip install langchain-iris
After that, you can use the method from_documents() from IRISVector class, like this:
db = IRISVector.from_documents(
embedding=embeddings,
documents=docs,
collection_name=COLLECTION_NAME,
connection_string=CONNECTION_STRING,
)
Where:
embeddingsis alangchain.embeddingsinstance of some embedding model - like OpenAI or Hugging Faces, for instance.documentsis an array of strings that will be applied to the embedding model and the resulting vectors stored in IRIS. Generally, the document should be splitted due size limitations of embedding models and better managing of it; the langchain framework provides several splitters.collection_nameis the table name where the documents (or its fragments) and its embedding vectors will be stored.connections_stringis a DBAPI connection string to IRIS, in this format:iris://: @ : /
Check out the complete code of the hello world example in langchain-iris repo.
A deeper look on the whole process
Here, we are going to focus on how to use IRIS as langchain’s vector store through langchain-iris and how it works. To get a better understanding, please first refer to the langchain Q&A chatbot example, which provides a great explanation on each section of its code.
As you can see in the original example, the Chroma vector database is used, by its langchain’s vector store implementation:
from langchain_chroma import Chroma
…
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
So, in order to use IRIS instead, just change the Chroma vector store by langchain-iris:
vectorstore = IRISVector.from_documents(
embedding=OpenAIEmbeddings(),
documents=splits,
collection_name="chatbot_docs",
connection_string=iris://_SYSTEM:SYS@localhost:1972/USER',
)
Now, you are all set to use IRIS in the langchain’s Q&A chatbot example. You can check out the whole example source code in this notebook.
After running the example, a table is created in the SQLUser schema (IRIS default schema) by langchain-iris. Note that its name came from the collection name set in langchain-iris:
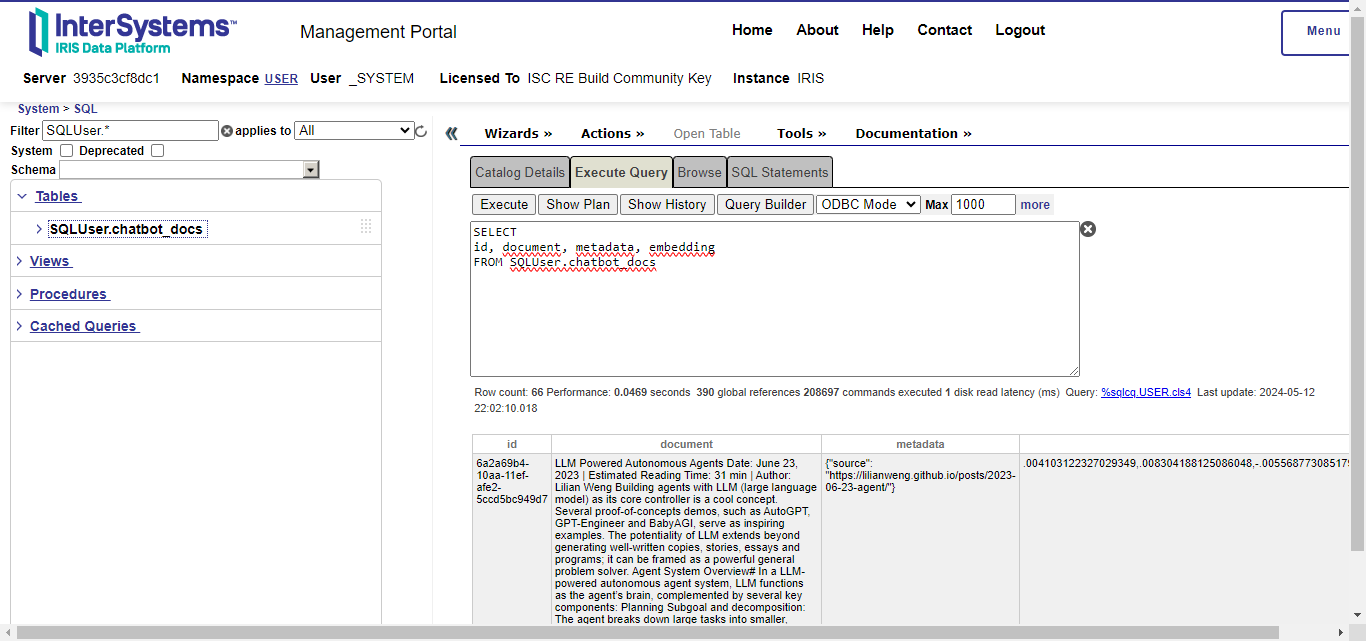
You can also note four columns:
id: the document ID.document: the document or a fragment of it, if a text splitter was used.metadata: a JSON object containing information about the document.embedding: the embedding vector which represents the document in a high vectorial space; this is the VECTOR type of IRIS Vector Search.
This is the indexing step, i.e, when langchain applies the embedding model to each document splitted fragment and stores its vector in IRIS with the fragment itself and a metadata.
As said before, langchaing provides splitters to break documents into fragments that fit the limits of embedding models and for enhance the retrieval process. Also we saw that those fragments and its corresponding embedding vectors are stored into a table in IRIS by langchain-iris. Now, in order to implement a RAG application, it’s necessary to query for most relevant documents stored into IRIS, given a query string. This is done by implementation of langchain retrievers.
You can create a retriever for documents stored in IRIS like this:
retriever = vectorstore.as_retriever()
With this retriever, you can query for most similar documents given a natural language query. The langchain framework will use the same embedding model used in the indexing step to extract a vector from the query. This way, document fragments with similar semantic content to the query could be retrieved.
For illustration, let’s use the langchain example, which indexes a web page with information about LLM agents. This page explaing several concepts, like task decomposition. Let's check out what the retriever returns given a query like “What are the approaches to Task Decomposition?":
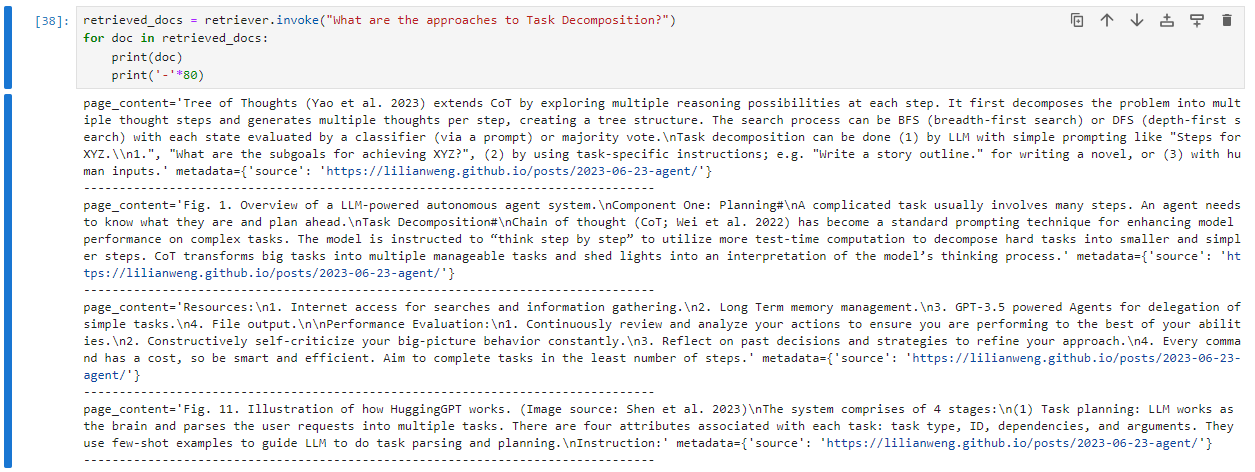
Now, let's do the same query - semantically speaking but syntactically different, i.e., using different words with similar meaning and see what the Vector Search engine returns:
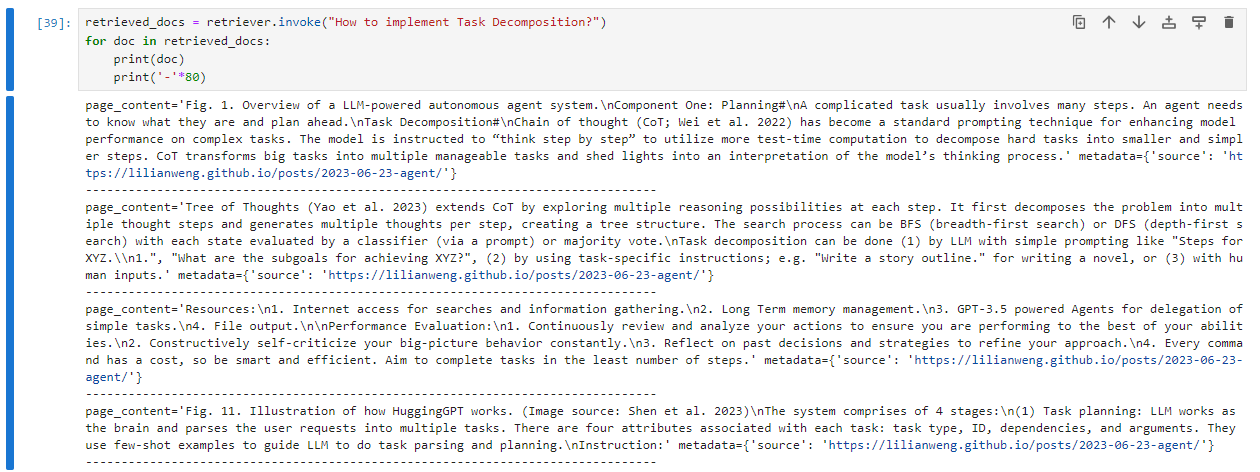
You can note that the results are practically the same, even with passing different query strings. This means that the embedding vectors are somehow abstracting the semantics in documents and query strings.
To get more evidences of such a semantic query capability, let's now keeping ask about task decomposition, but this time, asking for its downsides:
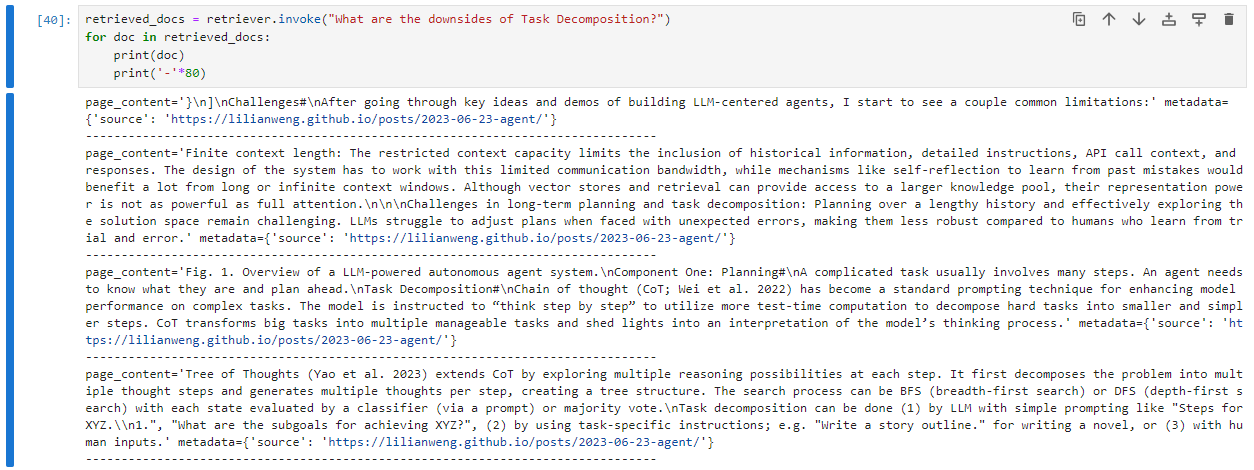
Note that this time the most relevant results are different from the previous one. Furthermore, the first results haven't the word ‘downside’, but related words like ‘challenges’, ‘limitation’ and ‘restricted’.
This reinforces the capability of semantic search of embedding vectors in vector databases.
After the retrieval step, the most relevant documents are appended as context information to the user query that will be sent to the LLM process. For instance (adapted from this page):
from langchain import hub
prompt = hub.pull("rlm/rag-prompt")
user_query = "What are the approaches to Task Decomposition?"
retrieved_docs = [doc.page_content for doc in retriever.invoke(user_query)]
example_messages = prompt.invoke(
{"context": "filler context", "question": user_query}
).to_messages()
print(example_messages[0].content)
This code will generate a prompt like this, which you can see the retrieved documents being used as context to the LLM align its response:
"""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: What are the approaches to Task Decomposition?
Context: Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple ... (truncated in the sake of brevity)
Answer:
"""
So, the RAG application can enhance its accuracy while respecting the size limits of LLM prompt.
Final words
In conclusion, the integration of IRIS Vector Search with the langchain framework opens new horizons for the development of Q&A chatbots and other applications reliant on semantic search and generative AI for InterSystems developers community.
The seamless integration of IRIS as the vector store through langchain-iris simplifies the implementation process, offering developers a robust and efficient solution for managing and querying large datasets of structured and unstructured information.
Through indexing, retrieval, and generation processes, RAG applications powered by IRIS Vector Search can effectively leverage both public and private data sources, enriching the capabilities of AI systems based on LLMs and providing users with more comprehensive and up-to-date responses.
To finalize, if you want to get more deep and see a complete application implementing these concepts along side other features like interoperability and business hosts to communicate with external APIs like OpenAI and Telegram, check out our application iris-medicopilot. We are planning to cover such an application in more detail in a next article.
See you!
Comments
Guys, tried your app - having the following error after sending text and audio to telegram bot:

Also here is the production view
.png)
Hi @Evgeny Shvarov
I apologize for this, unfortunately, we did not catch this error in our testing.
I just pushed a hotfix that should work around this issue, and we will be rolling out a permanent fix soon.
On MediCopilot Business Operation, now has a property to add the file data path..png)
Thank you very much for reporting the error, if you could please test again later.