IRIS AI Studio: Connectors to Transform your Files into Vector Embeddings for GenAI Capabilities
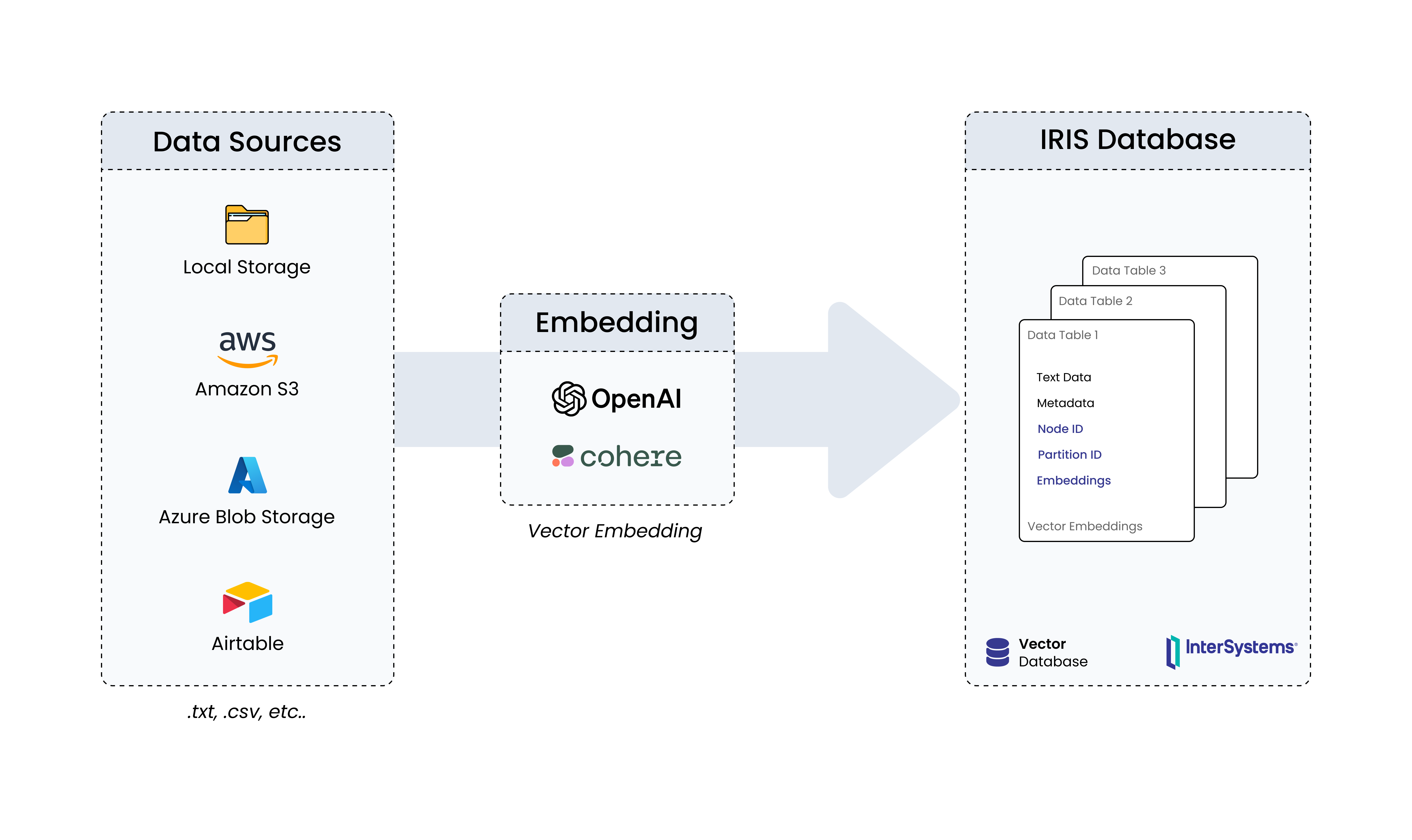
In the previous article, we saw different modules in IRIS AI Studio and how it could help explore GenAI capabilities out of IRIS DB seamlessly, even for a non-technical stakeholder. In this article, we will deep dive into "Connectors" module, the one that enables users to seamlessly load data from local or cloud sources (AWS S3, Airtable, Azure Blob) into IRIS DB as vector embeddings, by also configuring embedding settings like model and dimensions.
New Updates ⛴️
- Online Demo of the application is now available at https://iris-ai-studio.vercel.app
- Connectors module can now load data from (OpenAI/Cohere embeddings)
- Local Storage
- AWS S3
- Azure Blob Storage
- Airtable
- Playground module is fully functional with
- Semantic Search
- Chat with Docs
- Recommendation Engine
- Cohere Re-rank
- OpenAI Re-rank
- Similarity Engine
Connectors
If you have used ChatGPT 4 or other LLM services where they get the context and run the intelligence on top of that context, that ideally adds business value over a generic LLM. Simply the intelligence on your data. This module out of box gives a no-code interface to load data from different sources, do embeddings on it and load it to IRIS DB. This connectors module mainly go through 3 steps
- Fetching data from different sources
- Getting the data embedded using OpenAI/Cohere embedding models
- Loading the embeddings and text into IRIS DB
Step 1: Fetching data from different source
1. Local Storage - Upload files. I have used Llama Index's SimpleDirectoryReader to load data from files.
(a limitation of up to 10 files in one go is put to handle the load on tiny server that I used for demo purpose. Can be negated on your own implementation)
# Check for uploaded files
if "files" not in request.files:
return jsonify({"error": "No files uploaded"}), 400
uploaded_files = request.files.getlist("files")
if len(uploaded_files) > 10:
return jsonify({"error": "Exceeded maximum file limit (10)"}), 400
temp_paths = []
for uploaded_file in uploaded_files:
fd, temp_path = tempfile.mkstemp()
with os.fdopen(fd, "wb") as temp:
uploaded_file.save(temp)
temp_paths.append(temp_path)
# Load data from files
documents = SimpleDirectoryReader(input_files=temp_paths).load_data()
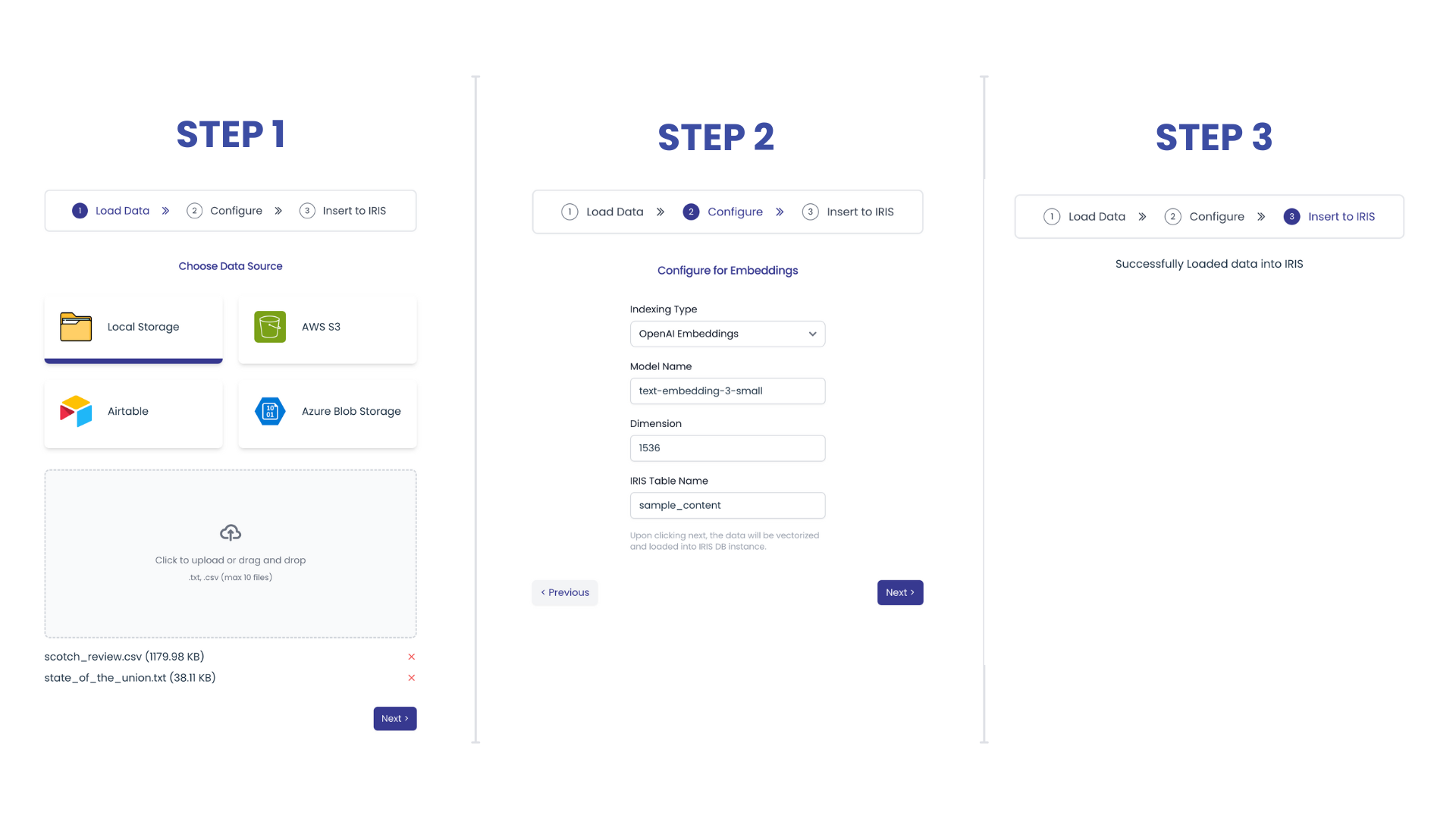 2. AWS S3
2. AWS S3
Input Parameters: Client ID, Client Secret and Bucket Name. You may get the client id and secret from the AWS console - IAM or creating read permissions for your bucket over there.
I have used "s3fs" library to fetch the contents from AWS S3 and Llama Index's SimpleDirectoryReader to load data from the fetched files.
access_key = request.form.get('aws_access_key')
secret = request.form.get('aws_secret')
bucket_name = request.form.get('aws_bucket_name')
if not all([access_key, secret, bucket_name]):
return jsonify({"error": "Missing required AWS S3 parameters"}), 400
s3_fs = S3FileSystem(key=access_key, secret=secret)
reader = SimpleDirectoryReader(input_dir=bucket_name, fs=s3_fs, recursive=True)
documents = reader.load_data()
3. Airtable
Input Parameters: Token (API Key), Base ID and Table ID. API Key can be retrieved from the Airtable's Developer Hub. Base ID and Table ID can be found from the table's URL. The one that starts with "app.." is the base ID and "tbl.." is the Table ID
I have used Airtable Reader from LlamaHub to fetch the contents from Airtable and Llama Index's SimpleDirectoryReader to load data from the fetched files.
airtable_token = request.form.get('airtable_token')
table_id = request.form.get('table_id')
base_id = request.form.get('base_id')
if not all([airtable_token, table_id, base_id]):
return jsonify({"error": "Missing required Airtable parameters"}), 400
reader = AirtableReader(airtable_token)
documents = reader.load_data(table_id=table_id, base_id=base_id)
.png)
4. Azure Blob Storage:
Input Parameters: Container name and Connection string. These information can be retrieved from Azure's AD page.
I have used AzStorageBlob Reader from LlamaHub to fetch the contents from Azure Storage and Llama Index's SimpleDirectoryReader to load data from the fetched files.
container_name = request.form.get('container_name')
connection_string = request.form.get('connection_string')
if not all([container_name, connection_string]):
return jsonify({"error": "Missing required Azure Blob Storage parameters"}), 400
loader = AzStorageBlobReader(
container_name=container_name,
connection_string=connection_string,
)
documents = loader.load_data()LlamaHub does contain 500+ connectors ranging from different file types to services. Adding a new connector based on your needs should be pretty straight forward.
Step 2: Getting the data embedded using OpenAI/Cohere embedding models
Embeddings are numerical representations that capture the semantics of text, enabling applications like search and similarity matching. Ideally the objective is, when an user asks a question, its embedding is compared to document embeddings using methods like cosine similarity – higher similarity indicates more relevant content.
Here, I'm using llama-iris library to store embeddings into IRIS DB. In the IRISVectorStore params
- Connection String is needed for interaction with DB
- For trying out in the online demo version, you may not use a locally running instance (localhost).
- You would need an IRIS instance that runs on AWS/Azure/GCP with 2024.1+ version, since those support vector storage and retrieval.
- The IRIS Community instance provided by the learning hub seems to be running with 2022.1 version, in which case that cannot be used for exploration purpose.
- Table Name is the one that will be used to create or update records into
- The library "llama-iris" appends "data_" to the table name. So, when you are trying to check the data through DB client, append "data_" to the table name. Say, you've named table as "users", you would need to retrieve as "data_users"
- Embed Dim / Embedding Dimension is the dimension of the Embedding model that the user used
- Say you've loaded "users" table by using OpenAI embeddings - "text-embedding-3-small" with 1536 dimension. You would be able to load more data into the table, but only with 1536 dimension. Same goes with vector embedding retrievals as well. So, make sure to choose the right model in the initial phases.
CONNECTION_STRING = f"iris://{username}:{password}@{hostname}:{port}/{namespace}"
vector_store = IRISVectorStore.from_params(
connection_string=CONNECTION_STRING,
table_name=table_name,
embed_dim=embedding_dimension
)
Settings.embed_model = set_embedding_model(indexing_type, model_name, api_key)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents,
storage_context=storage_context
)
Step 3: Loading the embedding and text into IRIS DB
The above written code covers the indexing and loading of data into IRIS DB. Here is how the data would look like -
.png)
Text - Raw text information that's been extracted from the files we loaded
Node ID - This would be used as a reference when we do retrievals
Embeddings - The actual numerical representations of the text data
These three steps are through which the connectors module mainly work. When it comes to required data, like DB credentials and API Keys - I get it from the user and save it to the browser's local storage (Instance Details) and session storage (API Keys). It gives more modularity to the application for anyone to explore.
By bringing together the loading of vector-embedded data from files and the retrieval of content through various channels, IRIS AI Studio enables an intuitive way to explore the Generative AI possibilities that InterSystems IRIS offers - not only for existing customers, but also for new prospects.
🚀 Vote for this application in Vector Search, GenAI and ML contest, if you find it promising!
If you can think of any potential applications using this implementation, please feel free to share them in the discussion thread.
Comments
HMMMM.
I see npm, I see python in github
Is there some IRIS hidden anywhere ??
Hi @Luc Morningstar! Thank you for asking.
I am executing SQL queries for the interactions with IRIS DB. Here are few examples on how it's used
- iris-ai-studio/backend/list_tables.py
In this file you could see a query that's being called when I wanted to fetch all the table names in the IRIS DB instance with 'SQL_User' schemaSELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'SQLUser - iris-ai-studio/backend/chat_llama.py
Here, `IRISVectorStore` function from llama-iris library being used, which does execute the SQL query needed to do operations on storing/retrieving of vector embeddings into/from IRIS DB. An example from that:CREATE OR REPLACE FUNCTION llamaindex_l2_distance(v1 VARBINARY, v2 VARBINARY) RETURNS NUMERIC(0,16) LANGUAGE OBJECTSCRIPT { set dims = $listlength(v1) set distance = 0 for i=1:1:dims { set diff = $list(v1, i) - $list(v2, i) set distance = distance + (diff * diff) } quit $zsqr(distance) }
The same `IRISVectorStore` function being used all across for loading and retrieval purposes (data_loader.py, chat_llama.py, query_llama.py, similarity_llama.py, reco_llama.py). Since this library encapsulates the needs on interaction with the IRIS DB, I didn't replicate the same functioning.
In my previous post I got inputs on leveraging IoP (Interoperability on Python) for achieving similar outcome through a more leaner way. I'm learning that and exploring if it could be incorporated along with the current functioning.
I hope this answers your query. Please let know if you may have any more questions!