これは InterSystems FAQ サイトの記事です。
InterSystems IRIS では、シャドウイングは非推奨機能となりました。
こちらのトピックでは、これまでにCachéでシャドウイングを使用していたお客様に対して、IRISへの移行後に、代わりに使用できるミラーリングの構成方法をご紹介します。
ミラーリングには機能的に2つの種類があります。
1.同期ミラーによるフェールオーバー(常にデータベースが同期されて複製、障害時に自動でフェールオーバー)
2.非同期ミラー(シャドウイングと同様の機能を提供)
- DR非同期(DR構成で利用、フェールオーバーへの昇格が可能、複製DBへの書き込み不可)
- レポーティング非同期(データマイニング/BIアプリでの利用、複製DBへの書き込み可能)
シャドウイングに代わって、IRISでは「プライマリ・フェイルオーバー」+「非同期ミラー」でミラーリングを構成する機能を利用することができます。
以下は、シャドウイングとミラーリングのサーバ役割の対比表になります。
※ミラー構成内の1つのインスタンスを “ミラーメンバ” または単に “メンバ” と呼びます。
では、ミラーの構成手順をご紹介します。手順は以下になります。
1) それぞれのサーバでISCAgent の構成・起動
2) それぞれのサーバでMIRRORDATAネームスペース(データベース)を作成
3) 正サーバでミラーを作成し、フェイルオーバー・メンバを構成・ミラーへデータベースの追加
4) 副サーバで非同期ミラー・メンバを構成・ミラーへのデータベースの追加
(IRIS.DATのファイル自体をコピーして複製する場合は、必ずディスマウントした状態で行ってください。)
今回は、各設定を管理ポータルを使用して行う方法をご紹介します。
【今回のサンプル・ミラー構成について】
ISCAgent は、IRISインストール時にインストールされます。
こちらは、IRIS起動時に開始するよう設定する必要があります。
開始/停止方法は、OSごとに異なりますのでドキュメントをご覧ください。
ISCAgent は、各ミラーメンバ上の専用ポート (既定値は 2188) を使用します。
それぞれのサーバで、MIRRORDATAという名前の新しいネームスペースを作成し、参照するデータベースとしてMIRRORDATAデータベースをデフォルト設定の状態で作成します。
.png)
1.ミラーサービスを有効にします
管理ポータル:
[システム管理] > [構成] > [ミラー設定] > [ミラーサービス有効]
サービス有効 にチェックをして保存します。
.png)
2.ミラーを作成します
管理ポータル:
[システム管理] > [構成] > [ミラー設定] > [ミラーサービス作成]
[ミラー情報] セクションに以下の情報を入力して保存します。
.png)
※プライマリ-非同期ミラー構成の場合は、アービターを使用する必要はありません。
※ミラーメンバ名は、既定で $sysytem 変数の内容が設定されています。
(<デバイス名>/<インスタンス名> 例:JP001ISJ/IRIS)
こちらをそのまま使用するのでも構いません。
3.TESTMIRRORへMIRRORDATAデータベースを追加します。ミラーデータベース名には、MIRRORDATAを使用します
管理ポータル:
[システム管理] > [構成] > [システム構成] > [ローカルデータベース]
MIRRORDATAの編集 → ミラー○○に追加
メモ:もし、画面中に「ミラーに追加」のリンクが表示されない場合、ディスマウントを実行し、マウントし直してください。
.png)
※ミラーが有効なライセンスを使用していない場合、以下のようなエラーになりますのでご注意ください。
エラー #2076: 'TESTMIRROR' のミラーメンバ情報取得中にエラーが発生しました。
エラー情報: Failed to create InterSystems IRIS context, error = -1
1.ミラーサービスを有効にします
管理ポータル:[システム管理] > [構成] > [ミラー設定] > [ミラーサービス有効]
サービス有効 にチェックをして保存します。
2.ミラーに非同期として参加します
管理ポータル:[システム管理] > [構成] > [ミラー設定] > [非同期として参加]
[ミラー情報] セクションに、2) で設定した正サーバの情報を入力し、「次へ」をクリックします。
.png)
3.非同期メンバとして登録したいマシンの情報を指定して保存します
今回は、非同期メンバシステムタイプ=災害復旧(DR)の構成とします。
※ミラーメンバ名は、既定で $sysytem 変数の内容が設定されています。こちらをそのまま使用するのでも構いません。
.png)
4.非同期ミラーへデータベースの追加・キャッチアップを行います
非同期データベースにMACHINEA(正サーバ)のバックアップファイルをリストアします。
【補足】
データベースファイル(IRIS.DAT)のコピーによるバックアップの場合は(=Backup.GeneralクラスのExternalFreeze()/ExternalThaw() を利用してバックアップを取っている場合)、非同期データベースをディスマウントした状態でデータベースファイル(IRIS.DAT)を置換します。
※外部/オンラインバックアップ・リストアについては、以下の記事で詳細手順を説明していますので、参考になさってください。
・外部バックアップについて
・オンラインバックアップについて
※バックアップからのリストアの場合、
Limit restore to mirrored databases? →Yes でリストアします(リストア後、ミラーが有効化&キャッチアップされます)
★2025/07/25 追記★
※2025.1以降のバージョンでは、「ミラーメンバーからの自動データベースダウンロード」機能を使用して、プライマリから簡単にミラーデータベースをダウンロードすることができるようになりました。
手順は、ローカルデータベース作成時に、「ミラーデータベース?(はい)」を選択し、「ミラーデータベース名」を指定するだけです。
この設定のみで、プライマリのミラー環境から、対象のデータベースを自動でダウンロードし、非同期DR環境に設定します。
こちらの機能を使用する場合、5と6の手順は必要ありません。7のミラーモニタでステータスを確認して終了です。
※この機能は、新規作成ミラーデータベースに対しては非常に便利ですが、元のデータベースのサイズが大きい場合は非常に時間がかかるため、注意が必要です。サイズの大きいデータベースの場合は従来の方法をお勧めします。
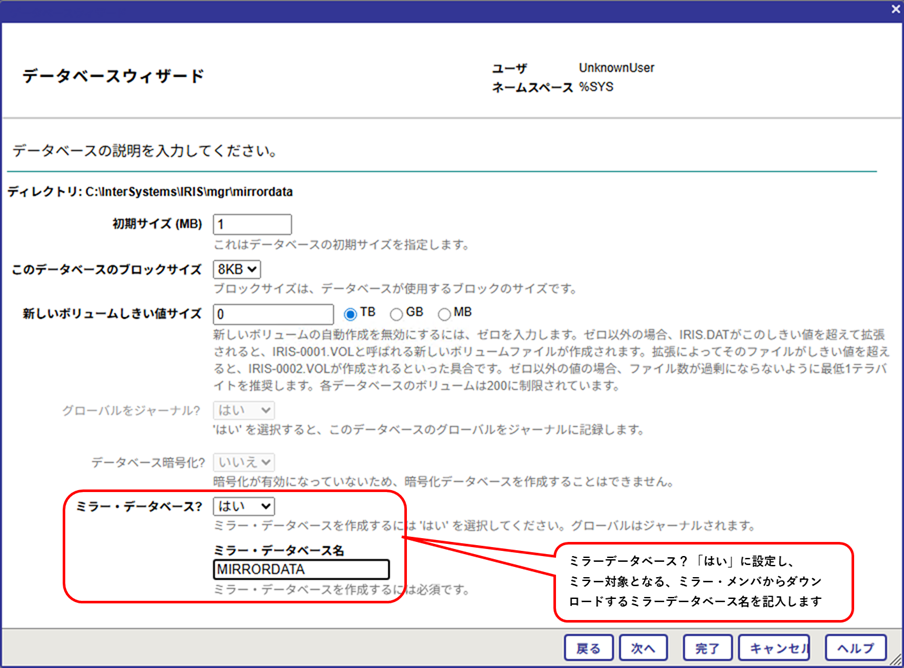
5.リストア(置換)後、ミラーモニタ画面にて非同期データベースに対するミラーの「有効化」を行います
※「ミラーメンバーからの自動データベースダウンロード」機能を使用しない場合
管理ポータル:
[システムシステムオペレーション] > [ミラーモニタ]
.png)
6.有効化した後、キャッチアップします
※「ミラーメンバーからの自動データベースダウンロード」機能を使用しない場合
.png)
7.キャッチアップしたことを確認します(こちらで構成は終了です)
.png)
※非同期メンバのシステム・タイプを変更したい場合(DR非同期 --> レポーティング非同期)
管理ポータルで変更できます。
管理ポータル:
[システム管理] > [構成] > [ミラー設定] > [非同期を編集]
1.非同期メンバシステムタイプを「読み書き可能なレポーティング」に変更します。
2.非同期レポーティング(読み書き可能)は、フェールオーバーメンバに昇格する条件を満たしません。
読み書き可能に変更するためには、フェールオーバーデータベースフラグをクリア します。
※ [FailoverDB] フラグをクリアすると、データベースは読み書き可能に変更されます。
そのため、ミラーのプライマリコピーとしては使用できなくなります。
非同期レポーティング(読み取り専用)の場合、この設定は推奨されません。
3.保存します。
※詳細は、ドキュメント をご覧ください。
.png)
【注意】
[読み書き可能] または [読み取り専用のレポート] から [災害復旧 (DR)] に変更することはできません。
※一部の条件を満たした場合を除きます。詳細は ドキュメント をご覧ください。
 【ご参考】
【ご参考】
Cache Mirroring 101:簡単なガイドとよくある質問
ミラーリングの機能について
ミラージャーナルファイルの削除のタイミングと要件
IRISでシャドウイングの代わりにミラーリングを構成する方法-プログラム編
