Este artigo apresenta uma solução em potencial para a busca semântica de código no TrakCare usando o IRIS Vector Search.
Aqui está uma breve visão geral dos resultados da busca semântica de código do TrakCare para a consulta: "Validação antes de salvar o objeto no banco de dados".
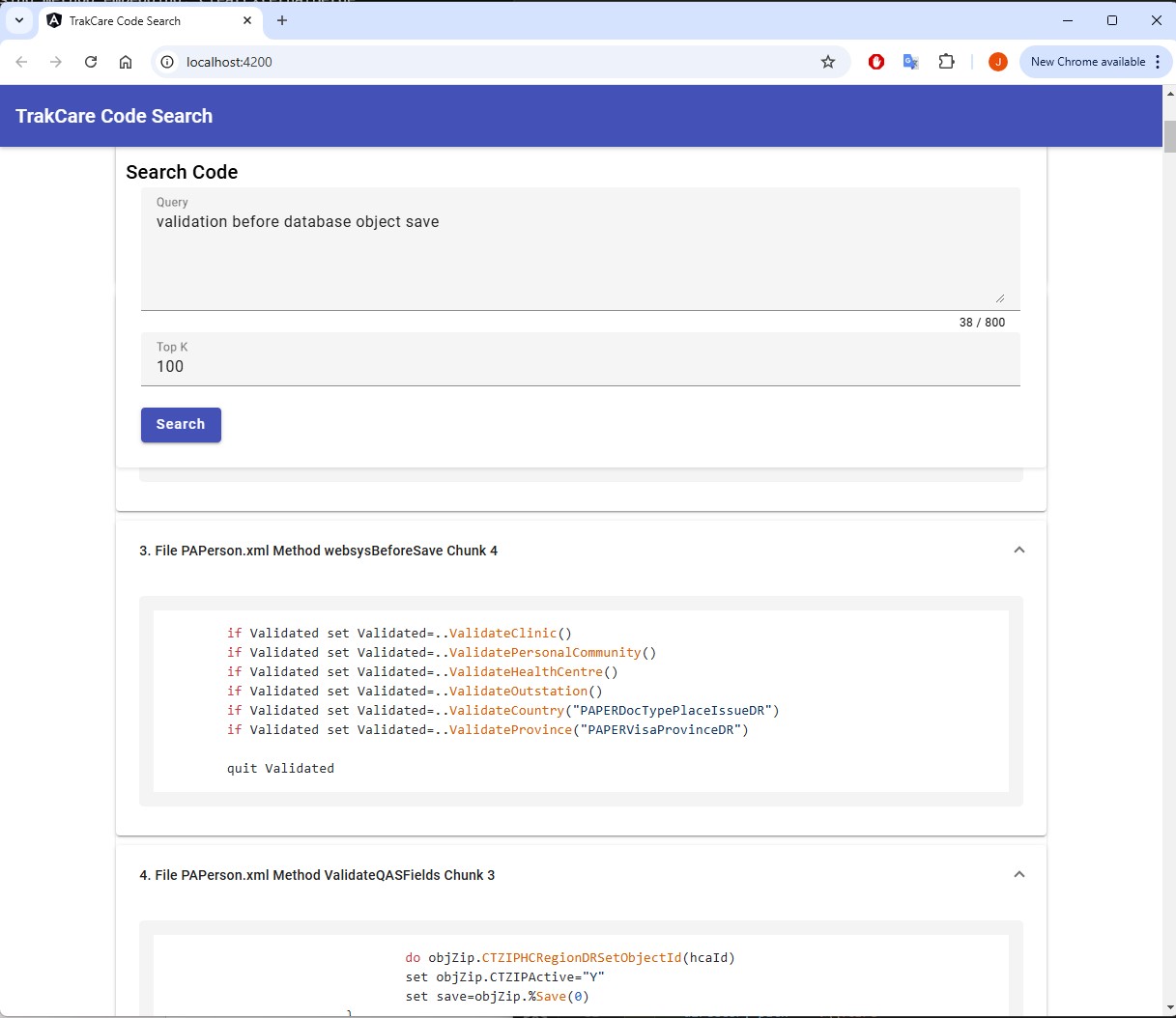
-
Modelo de Embedding de Código
Existem diversos modelos de embedding desenvolvidos para frases e parágrafos, mas eles não são ideais para embeddings específicos de código.
Foram avaliados três modelos de embedding específicos para código: voyage-code-2, CodeBERT e GraphCodeBERT. Embora nenhum desses modelos tenha sido pré-treinado para a linguagem ObjectScripts, eles ainda superaram os modelos de embedding de propósito geral nesse contexto.
O CodeBERT foi escolhido como o modelo de embedding para esta solução, oferecendo desempenho confiável sem a necessidade de uma chave de API.😁
class GraphCodeBERTEmbeddingModel:
def __init__(self, model_name="microsoft/codebert-base"):
self.tokenizer = RobertaTokenizer.from_pretrained(model_name)
self.model = RobertaModel.from_pretrained(model_name)
def get_embedding(self, text):
"""
Generate a CodeBERT embedding for the given text.
"""
inputs = self.tokenizer(text, return_tensors="pt", max_length=512, truncation=True, padding="max_length")
with torch.no_grad():
outputs = self.model(**inputs)
cls_embedding = outputs.last_hidden_state[:, 0, :].squeeze().numpy()
return cls_embedding
-
Banco de Dados Vetorial IRIS
Uma tabela é definida com uma coluna do tipo VECTOR para armazenar os embeddings. Observe que o índice COLUMNAR não é suportado para colunas do tipo VECTOR.
Os embeddings do CodeBERT possuem 768 dimensões. Ele pode processar textos com comprimento máximo de 512 tokens.
CREATE TABLE TrakCareCodeVector (
file VARCHAR(150),
codes VARCHAR(2000),
codes_vector VECTOR(DOUBLE,768)
)
A API DB Python é utilizada para estabelecer uma conexão com a instância IRIS e executar as instruções SQL.
- Construir o Banco de Dados Vetorial para o Código Fonte TrakCare
- Recuperar os Top_K Embeddings de Código com Maior DOT_PRODUCT do Banco de Dados Vetorial IRIS
import iris
import os
from dotenv import load_dotenv
load_dotenv()
class IrisConn:
"""Connection with IRIS instance to execute the SQL statements """
def __init__(self) -> None:
connection_string = os.getenv("CONNECTION_STRING")
username = os.getenv("IRISUSERNAME")
password = os.getenv("PASSWORD")
self.connection = iris.connect(
connectionstr=connection_string,
username=username,
password=password,
timeout=10000,
)
self.cursor = self.connection.cursor()
def insert(self, params: list):
try:
sql = "INSERT INTO TrakCareCodeVector (file, codes, codes_vector) VALUES (?, ?, TO_VECTOR(?,double))"
self.cursor.execute(sql,params)
except Exception as ex:
print(ex)
def fetch_query(self, query: str):
self.cursor.execute(query)
return self.cursor.fetchall()
def close_db(self):
self.cursor.close()
self.connection.close()
from transformers import AutoTokenizer, AutoModel, RobertaTokenizer, RobertaModel, logging
import torch
import numpy as np
import os
from db import IrisConn
from GraphcodebertEmbeddings import MethodEmbeddingGenerator
from IRISClassParser import parse_directory
import sys, getopt
class GraphCodeBERTEmbeddingModel:
def __init__(self, model_name="microsoft/codebert-base"):
self.tokenizer = RobertaTokenizer.from_pretrained(model_name)
self.model = RobertaModel.from_pretrained(model_name)
def get_embedding(self, text):
"""
Generate a CodeBERT embedding for the given text.
"""
inputs = self.tokenizer(text, return_tensors="pt", max_length=512, truncation=True, padding="max_length")
with torch.no_grad():
outputs = self.model(**inputs)
cls_embedding = outputs.last_hidden_state[:, 0, :].squeeze().numpy()
return cls_embedding
class IrisVectorDB:
def __init__(self, vector_dim):
"""
Initialize the IRIS vector database.
"""
self.conn = IrisConn()
self.vector_dim = vector_dim
def insert(self, description: str, codes: str, vector):
params=[description, codes, f'{vector.tolist()}']
self.conn.insert(params)
def search(self, query_vector, top_k=5):
query_vectorStr = query_vector.tolist()
query = f"SELECT TOP {top_k} file,codes FROM TrakCareCodeVector ORDER BY VECTOR_COSINE(codes_vector, TO_VECTOR('{query_vectorStr}',double)) DESC"
results = self.conn.fetch_query(query)
return results
class CodeRetrieveChatbot:
def __init__(self, embedding_model, vector_db):
self.embedding_model = embedding_model
self.vector_db = vector_db
def add_to_database(self, description, code_snippet, embedding = None):
if embedding is None:
embedding = self.embedding_model.get_embedding(code_snippet)
self.vector_db.insert(description, code_snippet, embedding)
def retrieve_code(self, query, top_k=5):
"""
Retrieve the most relevant code snippets for the given query.
"""
query_embedding = self.embedding_model.get_embedding(query)
results = self.vector_db.search(query_embedding, top_k)
return results
-
Fragmentos de Código (Code Chunks)
Como o CodeBERT consegue processar textos com um comprimento máximo de 512 tokens, classes e métodos muito grandes precisam ser divididos em partes menores. Cada uma dessas partes, ou fragmentos de código, é então incorporada (embedded) e armazenada no banco de dados vetorial.
from transformers import AutoTokenizer, AutoModel, RobertaTokenizer, RobertaModel
import torch
from IRISClassParser import parse_directory
class MethodEmbeddingGenerator:
def __init__(self, model_name="microsoft/codebert-base"):
"""
Initialize the embedding generator with CodeBERT.
:param model_name: The name of the pretrained CodeBERT model.
"""
self.tokenizer = RobertaTokenizer.from_pretrained(model_name)
self.model = RobertaModel.from_pretrained(model_name)
self.max_tokens = self.tokenizer.model_max_length
def chunk_method(self, method_implementation):
"""
Split method implementation into chunks based on lines of code that approximate the token limit.
:param method_implementation: The method implementation as a string.
:return: A list of chunks.
"""
lines = method_implementation.splitlines()
chunks = []
current_chunk = []
current_length = 0
for line in lines:
line_token_estimate = len(self.tokenizer.tokenize(line))
if current_length + line_token_estimate <= self.max_tokens - 2:
current_chunk.append(line)
current_length += line_token_estimate
else:
chunks.append("\n".join(current_chunk))
current_chunk = [line]
current_length = line_token_estimate
if current_chunk:
chunks.append("\n".join(current_chunk))
return chunks
def get_embeddings(self, method_implementation):
"""
Generate embeddings for a method implementation, handling large methods by chunking.
:param method_implementation: The method implementation as a string.
:return: A list of embeddings (one for each chunk).
"""
chunks = self.chunk_method(method_implementation)
embeddings = {}
for chunk in chunks:
inputs = self.tokenizer(chunk, return_tensors="pt", truncation=True, padding=True, max_length=self.max_tokens)
with torch.no_grad():
outputs = self.model(**inputs)
cls_embedding = outputs.last_hidden_state[:, 0, :].squeeze(0)
embeddings[chunk] = cls_embedding.numpy()
return embeddings
def process_methods(self, methods):
"""
Process a list of methods to generate embeddings for each.
:param methods: A list of dictionaries with method names and implementations.
:return: A dictionary with method names as keys and embeddings as values.
"""
method_embeddings = {}
for method in methods:
method_name = method["name"]
implementation = method["implementation"]
print(f"Processing method embedding: {method_name}")
method_embeddings[method_name] = self.get_embeddings(implementation)
return method_embeddings
-
Interface do Usuário - O Aplicativo Angular
A arquitetura utiliza Angular como frontend e Python (Flask) como backend.

O resultado da busca não é perfeito porque o modelo de embedding não foi pré-treinado para ObjectScripts.
.jpg)
.png)
.png)
.png)