You want to use the FOR EACH syntax or the TRAVERSE function which is the equivalent of $ORDER. Here is a link to the documentation online
http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY…
- Log in to post comments
You want to use the FOR EACH syntax or the TRAVERSE function which is the equivalent of $ORDER. Here is a link to the documentation online
http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY…
this looks like a good project to do with my kids. Can you provide an inventory of the components you needed. Obviously you needed an arduino board and a bread board. What was the weather sensor you used?
While it is true that Internal does not mean deprecated it is still not recommended that you utilize such items in your application code. Internal means that this is for InterSystems internal use only. Anything with this flag can change or be removed with no warning.
In Short DeepSee is an analytics tool to incorporate Actionable BI views of your data embedded within your application. DeepSee sits right on top of your application data store so there is no extract or transformation of data. This allows the dashboards created to be as up-to-date with transactional events as is appropriate up to near real-time. Users of these dashboard can then initiate action within the application directly from the Analytical view hence the "Actionable BI" label.
A great way to get started is to go to our online learning portal. Here is a link to the learning resource guide for DeepSee. https://learning.intersystems.com/course/view.php?id=19
Let me recap what I think I understand. You have a business service that uses an inbound file adapter. The OnProcessInput method of that service builds the message that then gets sent into the production. The input parameter of the OnProcessInput is a file character stream of some kind. You want to get the filename associated to that stream to add to your message.
If all the above is true then you need to access the 'filename' property of the stream. Note that the exact property may depend on the stream class being used. 'Filename' will work with any file based stream in the %Stream package or those stream classes defined in %Library. If this stream is of type Ens.StreamContainer then use the 'OriginalFilename' property.
If I am still not clear perhaps you could share at least some of the implementation of you OnProcessInput method and the details of the message class you are building.
One other question would be how are you trying to incorporate the source filename into the output filename? Are you using the %f filespec?
Do you have any data transformations along the way? If so be sure to move the %Source property.
Thanks to the responses. Unfortunately, after testing this, the client found it did not meet his needs. What is needed is a full blown VT type terminal emulator like Cterm supports embedded in a browser window. He needs things like arrow keys.
Any further suggestions would be welcome.
Thanks Benjamin! This looks like the way to go.
There are a number of reasons why building a REST service off a CSP page would be bad. They all come down to that a CSP page does not implement all the features of a "proper" REST service. REST is really not that difficult in Cache once you get the basics down. Just to be sure you are looking at the right documentation here is a link to the most recent.
http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY…
It is not clear from your question if this is in Cache or Ensemble. In practice setting up the service itself is best done in Cache even in you are using Ensemble. EnsLib.REST.Service does not, as of yet, provide a full implementation of the %CSP.REST class that it inherits from. It WILL work, however there may be some features of %CSP.REST that you can not take advantage of. I don't have a list of those. Post a follow up question if that is of interest and the information can be dug up.
When you look at a REST service call from you need to breakdown the URL to understand how this is implement in Cache. Take www.somecompany.com/api/v1/person/1, there are three sections we are worried about
server: www.somecompany.com
CSP Web Application: /api/v1 - this is setup in the system management portal under security->Applications-
resource being accessed: /person/1 - this is mapped in a Class that inherits from %CSP.REST in an XDATA block as shown below. The '1' in this case is a data value indicating which person record you want to access and is also part of the mapping. Here is what that class might look like:
Class Example.RESTservice extends %CSP.REST {
XData UrlMap [ XMLNamespace = "http://www.intersystems.com/urlmap" ]
{
<Routes>
<Route Url="/Person/:ID" Method="Get" Call="RetrievePerson" />
<Route Url="/test" Method="GET" Call="TestService" />
</Routes>
}
Classmethod RetreivePerson(ID as %String) as %Status
{
// code to retreive the person record and format the response which is simple "written" out from this method
//be sure to put a proper HTTP status in the %response.status property and a correct content type
// (ie. application/json) in %response.ContentType
}
}
Note the :ID in the map of the URL. This indicates a data value that is to be passed to the class method that is called. If there are multiple data values they are passed to each parameter of the method in order they occur. The name in the URL has no real meaning. These data parameters can also appear in any place in the URL so www.somecompany.com/api/v1/1/person could also be a valid URL.
Now tie this together by putting your REST class name that you just created (ie Example.RESTservice) in the Dispatch Class field of the web application. Now anything that is part of the URL that is past the CSP web application will be forwarded to the dispatch class to be handled.
Hope this helps
I attempted this with the following query:
SELECT Name,%VID,ID,Age FROM
(SELECT TOP 10 * FROM Sample.Person )
ORDER BY Name
Here are the results: You can see that the %VID column does not correspond to the returned result set.
| # | Name | Literal_2 | ID | Age |
|---|---|---|---|---|
| 1 | Adam,Tara P. | 7 | 7 | 59 |
| 2 | Brown,Orson X. | 8 | 8 | 92 |
| 3 | Hernandez,Kim J. | 1 | 1 | 23 |
| 4 | Kelvin,Dick J. | 6 | 6 | 12 |
| 5 | Orwell,Andrew T. | 9 | 9 | 46 |
| 6 | Page,Lawrence C. | 3 | 3 | 67 |
| 7 | Quixote,Andrew Q. | 4 | 4 | 73 |
| 8 | Williams,Stuart O. | 10 | 10 | 77 |
| 9 | Yakulis,Fred X. | 2 | 2 | 82 |
| 10 | Zemaitis,Emilio Q. | 5 | 5 | 57 |
I had a client that had this exact problem. The JSON interfaces that exist today intentionally try to take a concise approach rather than try to provide options to handle every possible situation. Bottom-line is that this means for this situation you will need to create your own method of handling this. The good is that this is not necessarily too difficult to create a flexible methodology to do this.
What my client did was to create a code generation method that would introspect on the class definition at compile time and produce a method that would build a Proxy object (old way, 2016 and higher would use Dynamic Object structures) of exactly what they wanted to have in the JSON. Then the method to produce the JSON from an object would use the Proxy or Dynamic object. For this client they created a parameter on the class that provided direction regarding how to handle collection properties.
It may also be possible to create a general utility class that defines new property parameters to manage this and the code generation method. Then have the your classes inherit from this to add in the desired functionality.
David,
You win the prize. Version miss-match was the issue. This caused several different errors depending on the class I was attempting to query. Upgrading to the same version across the board resolved them all at least to this point.
If you are publishing a RESTful service then you don't set the Accepted Content type. This is for the client to inform you as to what they responses they can accept. So your rest service would examine this value to verify that you can supply the type of response the client will accept. You would access this value using this syntax:
%request.CgiEnvs("HTTP_ACCEPT")
The Cache Version is Cache for Windows (x86-64) 2016.1.2 (Build 206) Mon Jul 25 2016 16:59:55 EDT. The attached image shows the error.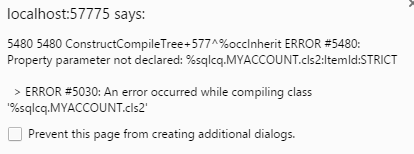
Problem with giving recommendations on how to minimize this is that there are many causes and many potential resolutions. Some solutions will not be acceptable. The simplest solution would be to create a database to hold this global and any other you don't need journaled. Set this database to not be journaled and map that global to this database. Of course you may want to have the database journaled. Now you have to dig in further as others have suggested and determine why there is so much activity hitting this global. It could be a routine that can be adjusted to generate less global activity. I had a similar situation where the problem was traced to the fact that for every iteration of a process loop the global was updated. The same record could be touched hundreds of times. The solution was to hold the updates in a process private global (not journaled) and then do a single pass to update the records.
Hope this helps.
This is happening on Windows also in Version: 1.1.121. Deleting storage and restarting Atelier solved this problem.
Evgeny,
This too looks very interesting. With REST services not built into 2016.1 that should make this easier. One question if I decide to mess around with this myself. Do you really need GULP to work with this project? I already have a boat load of tools installed.
Rich
Evgeny,
Thanks for this! Unfortunately it still appears to have the same limitation that you cannot inject your own Google API key. There is a prodlog in play to possibly add in the ability to define this in a configuration setting of some kind.
I did download it and I am looking at playing around with what you have done.
Rich
Just so happens I just installed an instance on CentOS. I can edit my config. Here is the permissions that are on my cache.cpf file. Compare them to yours. The xxxx is the user I chose as the owner.
-rw-rw-r--. 1 xxxx cacheusr 21901 Apr 22 22:15 cache.cpf
I will leave the logging issue alone as I don't see it as being the main point of the example. It could also be a thread by itself.
The issue of using a bunch of $$$ISERR or other error condition checks is exactly why I like using throw with try/catch. I disagree that it should only be for errors outside of the application's control. However it is true that most of the time you are dealing with a fatal error. Fatal that is to the current unit of work being performed, not necessarily to the entire process.
I will often use code like
set RetStatus = MyObj.Method()
throw:$$$ISERR(RetStatus) ##class(%Exception.StatusException).CreateFromStatus(RetStatus)
The post conditional on the throw can take many forms, this is just one example.
Where I put the Try/Catch depends on many factors such as:
I the case of nested loops mentioned I think this is a great way to abort the process and return to a point, whether in this program or one farther up the stack, where the process can be cleanly recovered or aborted.
Status codes still have a place along side of Try/Catch in my opinion. They really only serve to indicate the ending state of the method called. This is not necessarily an error. I agree that throwing an exception for truly fatal errors is the best and most efficient error handling method. The issues is what does "truly fatal" mean? There can be a lot of grey area to contend with. There are methods where the calling program needs to determine the correct response. For example take a method that calculates commission on a sale. Clearly this is a serious problem on a Sales order. However, it is less of an issue on a quotation. In the case of the latter the process may simply desire to return an empty commissions structure.
Placement of try/catch blocks is a separate conversation. Personally I find using try/catch blocks for error handling to be clean and efficient. The programs are easier to read and any recovery can be consolidated in one place, either in or right after the catch. I have found that any performance cost is unnoticeable in a typical transactional process. It surely beats adding IF statements to handle to handle the flow. For readability and maintainability I also dislike QUITing from a method or program in multiple places.
So where is the "right" place for a try/catch? If I had to pick one general rule I would say you should put the try/catch in anyplace where a meaningful recovery from the error/exception can be done and as close to the point where the error occurred as possible. I the above example of a Commission calculation method I would not put a try/catch in the method itself since the method can not perform any real recovery. However I would put one in the Sales order and Quotation code.
There are many methods to manage program flow under error/exception situations; Try/Catch, Quit and Continue in loops are a couple off the top of my head. Used appropriately they can create code that is robust, readable and maintainable with little cost in performance.
I think this would be useful to show in the project explorer too or at least in the properties of the project.
Two suggestions:
These are just suggestions as I have not had the chance to try either yet.
No reponse yet. I am really in need of a real world LDAP schema that if more complex (has been customized) than the provided schema. If anyone has the ability to share something like this it would be greatly appreciated.
Note that this is for a Global Summit presentation. I want to use an actual use case rather than attempting to invent something that would look and be contrived.
Thanks in advance,
Rich
Timur,
Thanks for the feedback. I have used process private globals in the past. Unfortunatey this and CACHETEMP will probably not work as the save needs to survive at least an application failure. If the customer can accept that a full system failure, either Cache or the server itself completely shutdown, the CACHETEMP may work. They would have to make changes to the application however as some of the objects involved are non-persistent.
Rich
One thing I am unclear on is whether the worker jobs have access to the in-memory objects of the process initiating the workers? I have a potential use case for this that I am investigating.
Are there any practical examples of using this?
The work queues do actually sound pretty close to what is being looked for. The question would be if the worker jobs have access to the in-memory objects of the process initiating the workers?
Are there any practical examples of using this?
Found the solution. The following MDX gives the values that I want.
SELECT {MEASURES.[Avg Test Score],
%LIST(NONEMPTYCROSSJOIN([BirthD].[H1].[Decade].Members,{[Measures].[Avg Test Score]}))} ON 0,
NON EMPTY homed.city.MEMBERS ON 1
FROM patients
I think the key was to enclose the measure in the NONEMPTYCROSSJOIN function in curly braces. I had not done this in a previous attempt at getting this to work.