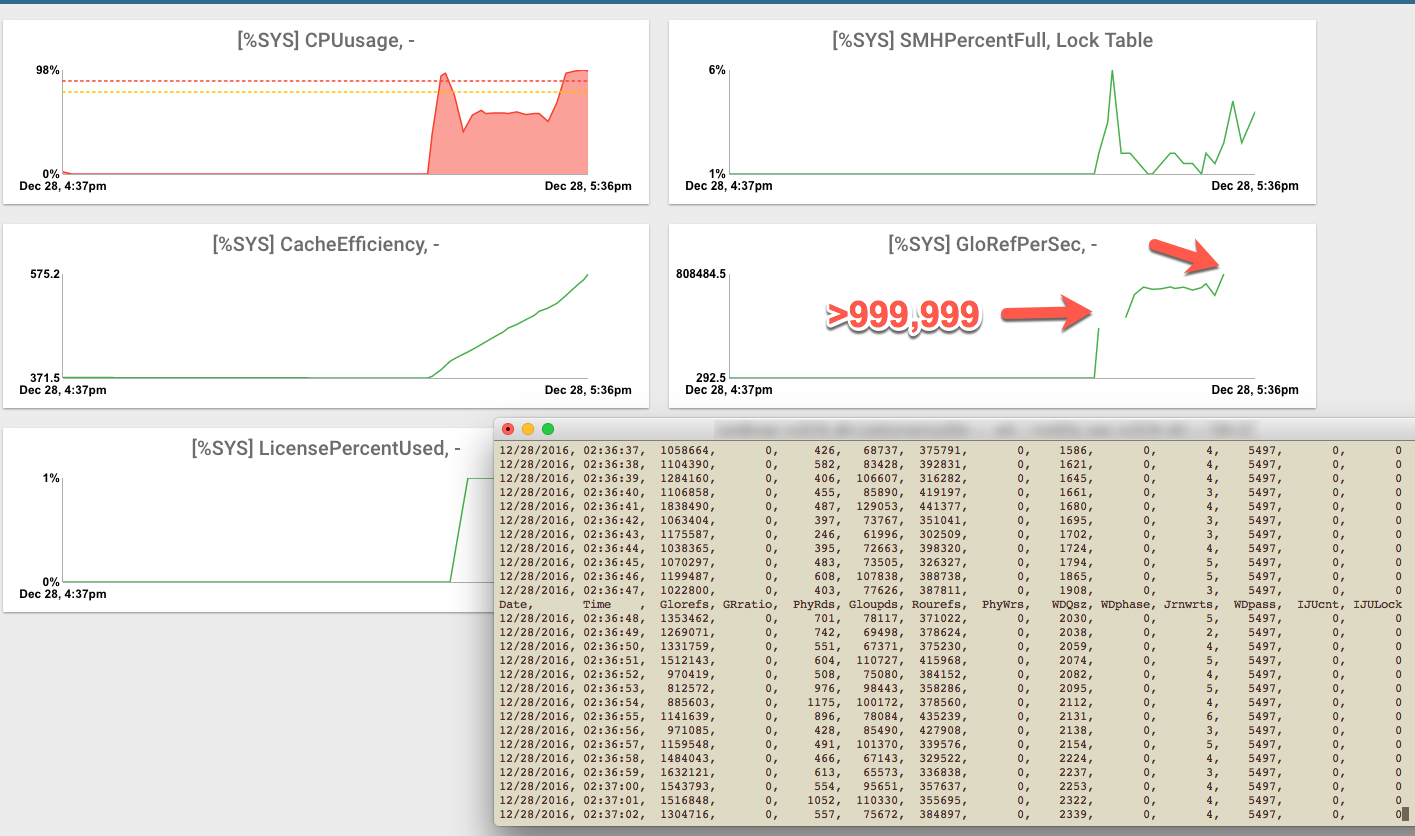
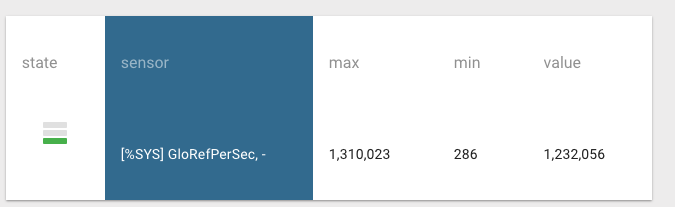
Hi, I think you have got it. Mark and I are saying the same thing. Sometimes a picture helps. The following is based on some presentations I have seen from Intel and VMware. It shows what happens when multiple VMs are sharing a host, which is why we recommend a reserved instance. But this also illustrates hyper-threading in general.
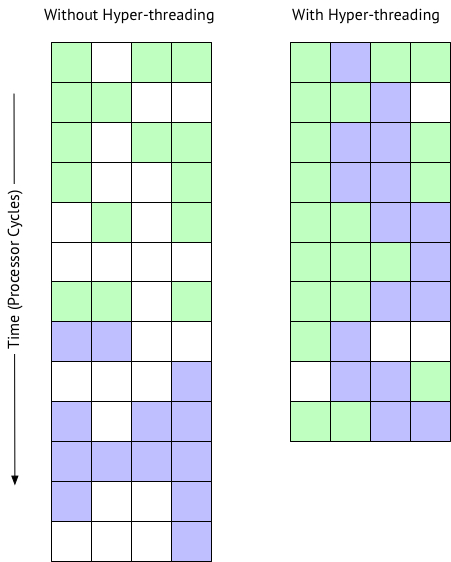
So to recap; A hyper-thread is not a complete core. A core is a core is a core, hyper-threading does not create more physical cores. The following picture shows a workload going through 4 processing units... micro execution units in a processor.
One VM is green a second is purple, white is idle. A lot of time is spent idle waiting for memory cache, IO, etc.
As you can see with hyper-threading on the right you don’t suddenly get two processors, not 2x, and expectation is ~10-30% improvement in processing time overall.
The schedular can schedule processing when there idle time, but remember on a system under heavy load CPU utilisation will be saturated anyway so there are less white idle time.
- Log in to post comments