what exactly are you looking for there?
looks like it introduced async execution, and IRIS does not async execution anyway
- Log in to post comments
what exactly are you looking for there?
looks like it introduced async execution, and IRIS does not async execution anyway
What the reason of using JDBC connection from Python?
InterSystems has DB-API driver in Python for a few years already, why would not you use it?
Hive should have db-api driver too
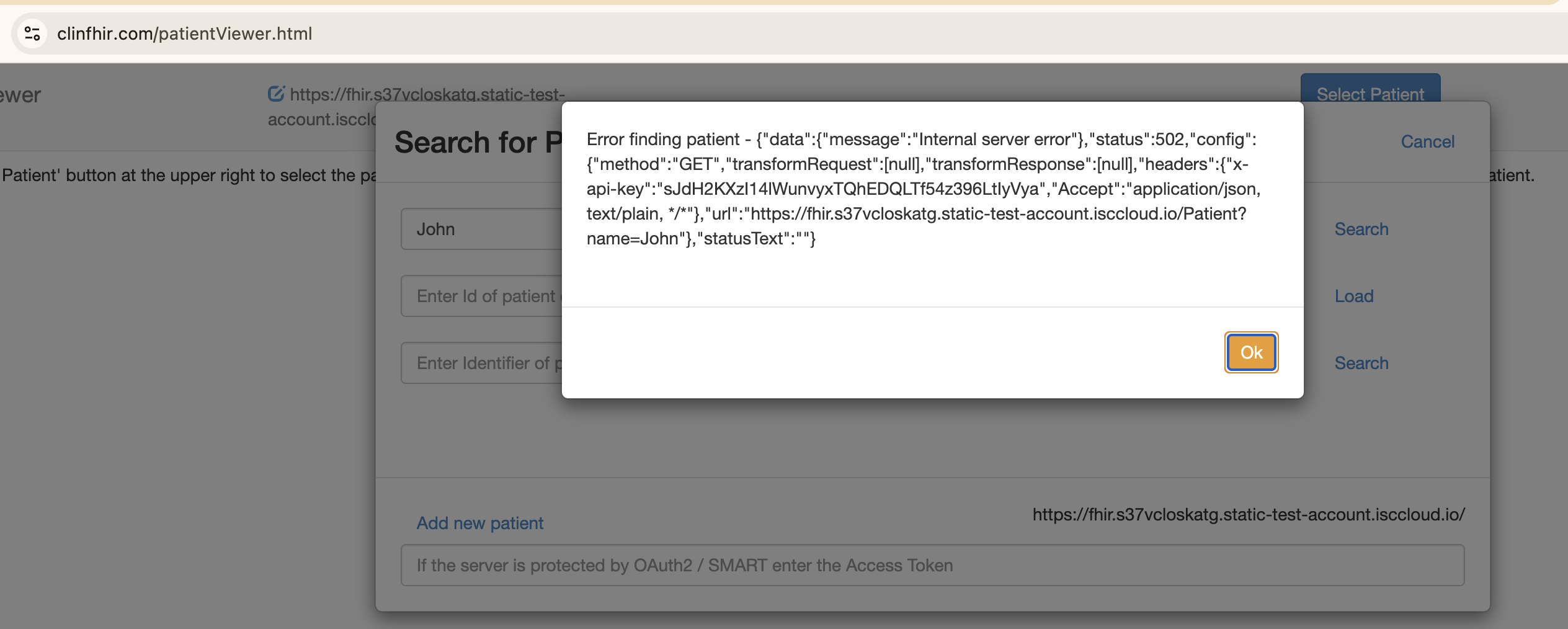
is clinfhir on IRIS even working?
getting status 502
So, looks like you already got what you wanted with json
then the only thing left is to redirect your new log file to a container's log, to do so, you should send it to PID 1
/iris-main has this option, so, just add your log file to a container command
-l <log file>, --log <log file>
InterSystems IRIS log file to be redirected to stdout for monitoring
via 'docker logs'any ideas in mind, how exactly you would like to look it as a json?
in our project with just put containers output to splunk, with a sidecar container, somewhere in that prcess it adds host, serivec other info that helps to filter to particular instance easily
Found types 12 and 13, which looks to be some ascii, same as type 1
USER>s l = $c(3,13,65) zw l w "$lv = ", $lv(l),!,"$li = ",$li(l)
l=$lb("A")
$lv = 1
$li = A
USER>s l = $c(3,12,65) zw l w "$lv = ", $lv(l),!,"$li = ",$li(l)
l=$lb("A")
$lv = 1
$li = A
other types really seems to be handled by network protocol only
Thanks for the notes. I have never seen a big-endian system and did not have a chance to test my it there, so, just assumed the behavior. I’ll update article about it
As for other types, I’m aware about few more types, which I thought mostly used in network protocol, and did not want to cover them yet
Did you check SharedMemory in Python?
We currently using IRIS docker and aws ecs in production for more then a year, and it works fine. Our system is quite big and have a big load. So, yes, I can say it's production ready.
well, too many things to consider when move from any much more popular RDB, to IRIS.
You should raise this issue with IPM team, there are some work related to python, where it happens, and it could be related to intersystems-irispython official driver, which tend to fail randomly with segmentation fault, and this error most probably is comming from Python
A bit hackish way
{
while IFS= read -r line; do
echo 'write *27,"[1F",$namespace,">", "'$(echo $line | sed "s/\"/\"\"/g" )'",*27,"[1F"'
printf '%s\n' "$line"
done
} <<'EOF' | iris session iris
write $zv
write !,"hello ", $username,!
zn "%sys"
halt
EOFand output
$ bash test.sh
Node: e91a00f6512e, Instance: IRIS
USER>write $zv
IRIS for UNIX (Ubuntu Server LTS for ARM64 Containers) 2026.1.0L (Build 193U) Tue Jan 6 2026 01:46:47 EST
USER>write !,"hello ", $username,!
hello irisowner
USER>zn "%sys"
%SYS>haltHi! I’m in for a random coffee chat ☕
Location: Australia, Melbourne
Availability: Mon–Fri, 11:00–16:00
Happy to chat
irisnative python uses Native API.
I'm curious if you want to use Python, could you look at SQLAlchemy IRIS, and maybe even at Django.
will that require license to run it by anyone else?
This is how COPY/rm look like in reality
FROM containers.intersystems.com/intersystems/iris:latest-em
COPY iris.key /usr/irissys/mgr/iris.key
RUN rm -f /usr/irissys/mgr/iris.keyusing dive tool, to inspect docker images
.png)
The layer with iris.key is still there, and adds some space into final image
important note
When you add something and delete during build with Dockerfile, you should remember how docker build works, and do it in one RUN line, if you do COPY/ADD file then delete it in RUN, it will not delete file from the image, it will hide it in the final image. Due to layered nature of Docker images, COPY/ADD/RUN are separated layers, and generates a difference between. So, file still can be exctrated.
And nowdays, the best approach to using binding in RUN
....
RUN \
--mount=type=bind,src=.,dst=/opt/app \
cp /opt/app/iris.key /usr/irissys/mgr/iris.key && \
iris start IRIS && \
....
iris stop IRIS quietly && \
rm -f /usr/irissys/mgr/iris.key
or you can mount it straight to the way where it's expected, and it will not stay in the final image
...
RUN --mount=type=bind,src=/iris.key,dst=/usr/irissys/mgr/iris.key \
iris start IRIS && \
/bin/echo -e 'do ##class(%SYSTEM.License).CKEY() halt' | iris session IRIS -U %SYS && \
iris stop IRIS quietly
I've updated the building process. Now should get updates at least in one day after official release.
And returned ML version, even when there is no official build.
Yes, in some cases this works, and even got quite fast fix, thanks.
I hope, we can get more fixes done and not only with SQL
.png)
.png)
I would not say that I did not expect that.
I provided all source code, which easily shows errors, but as an answer got
we can't reproduce this bug
If I could resolve those issues by myself I would do it, but this is InterSystems responsibility
With those errors, I would not use JDBC in production, would not even try any project, due to the bugs I discovered with SQLancer project.
And for Python, luckily I already have driver in pure Python that works much more stable than new official one, so, would use it, and would not use official driver, as I see that it can fail at any time.
I have no reason to use WRC for reporting these bugs, as I did not find it for the company, I found it in open source projects. And after discoveries, would not even try implementing it in company, so, no point.
Thanks, and congrats to others winners
#4

check this tool https://pypi.org/project/irissqlcli/
Now, how wonderful would be, if InterSystems produced official product like this, and Community Edition would get much higher number of connections available there, when nothing needed only for Enterprise is left there.
Have a look at VSCode, Studio already reached end of life, no reason to keep using it.
.png)
Why not to put which standard exactly it exactly?
It says, see the documentation for more information. Where it is? The only found page have not been changes for a few versions.
Where is JSON_VALUE, JSON_QUERY, JSON_EXISTS that defined in the standard?
Most of the time it generates queries that make no sense. But still supposed to be working.
CREATE TABLE t0(c0 BIT );
SELECT * FROM t0 WHERE (c0 IN (c0, c0, c0, c0));
Gives
SQL Error [400] [S1000]: [SQLCODE: <-400>:<Fatal error occurred>]
[Location: <Prepare>]
[%msg: <<UNDEFINED>in+4^%qaqpnl *mt("v","4")>]Happy Birthday DC
Yeah, I know that it's works without those brackets. But the thing is that SQLancer generates SQL queries randomly, and expected to produce queries that looks ridiculous, but syntactically correct and expected to work
On community edition due to small amount of licensed connections, and issue with fast releasing available connections, and probably due to too many failures on the network layer in the communication it's very fast start to fail to connect due to license limit.
I saw you used mine sqlalchemy-iris, looks like implementation is much easier this way, thanks.