Article
Sergey Lukyanchikov · Jul 22, 2021
Challenges of real-time AI/ML computations
We will start from the examples that we faced as Data Science practice at InterSystems:
A “high-load” customer portal is integrated with an online recommendation system. The plan is to reconfigure promo campaigns at the level of the entire retail network (we will assume that instead of a “flat” promo campaign master there will be used a “segment-tactic” matrix). What will happen to the recommender mechanisms? What will happen to data feeds and updates into the recommender mechanisms (the volume of input data having increased 25000 times)? What will happen to recommendation rule generation setup (the need to reduce 1000 times the recommendation rule filtering threshold due to a thousandfold increase of the volume and “assortment” of the rules generated)?
An equipment health monitoring system uses “manual” data sample feeds. Now it is connected to a SCADA system that transmits thousands of process parameter readings each second. What will happen to the monitoring system (will it be able to handle equipment health monitoring on a second-by-second basis)? What will happen once the input data receives a new bloc of several hundreds of columns with data sensor readings recently implemented in the SCADA system (will it be necessary, and for how long, to shut down the monitoring system to integrate the new sensor data in the analysis)?
A complex of AI/ML mechanisms (recommendation, monitoring, forecasting) depend on each other’s results. How many man-hours will it take every month to adapt those AI/ML mechanisms’ functioning to changes in the input data? What is the overall “delay” in supporting business decision making by the AI/ML mechanisms (the refresh frequency of supporting information against the feed frequency of new input data)?
Summarizing these and many other examples, we have come up with a formulation of the challenges that materialize because of transition to using machine learning and artificial intelligence in real time:
Are we satisfied with the creation and adaptation speed (vs. speed of situation change) of AI/ML mechanisms in our company?
How well our AI/ML solutions support real-time business decision making?
Can our AI/ML solutions self-adapt (i.e., continue working without involving developers) to a drift in the data and resulting business decision-making approaches?
This article is a comprehensive overview of InterSystems IRIS platform capabilities relative to universal support of AI/ML mechanism deployment, of AI/ML solution assembly (integration) and of AI/ML solution training (testing) based on intense data flows. We will turn to market research, to practical examples of AI/ML solutions and to the conceptual aspects of what we refer to in this article as real-time AI/ML platform.
What surveys show: real-time application types
The results of the survey conducted by Lightbend in 2019 among some 800 IT professionals, speak for themselves: Figure 1 Leading consumers of real-time data
We will quote the most important for us fragments from the report on the results of that survey: “… The parallel growth trends for streaming data pipelines and container-based infrastructure combineto address competitive pressure to deliver impactful results faster, more efficiently and with greater agility. Streaming enables extraction of useful information from data more quickly than traditional batch processes. It also enables timely integration of advanced analytics, such as recommendations based on artificial intelligence and machine learning (AI/ML) models, all to achieve competitive differentiation through higher customer satisfaction. Time pressure also affects the DevOps teams building and deploying applications. Container-based infrastructure, like Kubernetes, eliminates many of the inefficiencies and design problems faced by teams that are often responding to changes by building and deploying applications rapidly and repeatedly, in response to change. … Eight hundred and four IT professionals provided details about applications that use stream processing at their organizations. Respondents were primarily from Western countries (41% in Europe and 37% in North America) and worked at an approximately equal percentage of small, medium and large organizations. … … Artificial intelligence is more than just speculative hype. Fifty-eight percent of those already using stream processing in production AI/ML applications say it will see some of the greatest increases in the next year.
The consensus is that AI/ML use cases will see some of the largest increases in the next year.
Not only will adoption widen to different use cases, it will also deepen for existing use cases, as real-time data processing is utilized at a greater scale.
In addition to AI/ML, enthusiasm among adopters of IoT pipelines is dramatic — 48% of those already incorporating IoT data say this use case will see some of the biggest near-term growth. … “
This quite interesting survey shows that the perception of machine learning and artificial intelligence scenarios as leading consumers of real-time data, is already “at the doorstep”. Another important takeaway is the perception of AI/ML through DevOps prism: we can already now state a transformation of the still predominant “one-off AI/ML with a fully known dataset” culture.
A real-time AI/ML platform concept
One of the most typical areas of use of real-time AI/ML is manufacturing process management in the industries. Using this area as an example and considering all the above ideas, let us formulate the real-time AI/ML platform concept. Use of artificial intelligence and machine learning for the needs of manufacturing process management has several distinctive features:
Data on the condition of a manufacturing process is generated very intensely: at high frequency and over a broad range of parameters (up to tens of thousands parameter values transmitted per second by a SCADA system)
Data on detected defects, not to mention evolving defects, on contrary, is scarce and occasional, is known to have insufficient defect categorization as well as localization in time (usually, is found in the form of manual records on paper)
From a practical standpoint, only an “observation window” is available for model training and application, reflecting process dynamics over a reasonable moving interval that ends with the most recent process parameter readings
These distinctions make us (besides reception and basic processing in real time of an intense “broadband signal” from a manufacturing process) execute (in parallel) AI/ML model application, training and accuracy control in real time, too. The “frame” that our models “see” in the moving observation window is permanently changing – and the accuracy of the AI/ML models that were trained on one of the previous “frames” changes also. If the AI/ML modeling accuracy degrades (e.g., the value of the “alarm-norm” classification error surpassed the given tolerance boundaries) a retraining based on a more recent “frame” should be triggered automatically – while the choice of the moment for the retraining start must consider both the retrain procedure duration and the accuracy degradation speed of the current model versions (because the current versions go on being applied during the retrain procedure execution until the “retrained” versions of the models are obtained). InterSystems IRIS possesses key in-platform capabilities for supporting real-time AI/ML solutions for manufacturing process management. These capabilities can be grouped in three major categories:
Continuous Deployment/Delivery (CD) of new or modified existing AI/ML mechanisms in a production solution functioning in real time based on InterSystems IRIS platform
Continuous Integration (CI) of inbound process data flows, AI/ML model application/training/accuracy control queues, data/code/orchestration around real-time interactions with mathematical modeling environments – in a single production solution in InterSystems IRIS platform
Continuous Training (CT) of AI/ML mechanisms performed in mathematical modeling environments using data, code, and orchestration (“decision making”) passed from InterSystems IRIS platform
The grouping of platform capabilities relative to machine learning and artificial intelligence into the above categories is not casual. We quote a methodological publication by Google that gives a conceptual basis for such a grouping: “… DevOps is a popular practice in developing and operating large-scale software systems. This practice provides benefits such as shortening the development cycles, increasing deployment velocity, and dependable releases. To achieve these benefits, you introduce two concepts in the software system development:
Continuous Integration (CI)
Continuous Delivery (CD)
An ML system is a software system, so similar practices apply to help guarantee that you can reliably build and operate ML systems at scale. However, ML systems differ from other software systems in the following ways:
Team skills: In an ML project, the team usually includes data scientists or ML researchers, who focus on exploratory data analysis, model development, and experimentation. These members might not be experienced software engineers who can build production-class services.
Development: ML is experimental in nature. You should try different features, algorithms, modeling techniques, and parameter configurations to find what works best for the problem as quickly as possible. The challenge is tracking what worked and what didn't, and maintaining reproducibility while maximizing code reusability.
Testing: Testing an ML system is more involved than testing other software systems. In addition to typical unit and integration tests, you need data validation, trained model quality evaluation, and model validation.
Deployment: In ML systems, deployment isn't as simple as deploying an offline-trained ML model as a prediction service. ML systems can require you to deploy a multi-step pipeline to automatically retrain and deploy model. This pipeline adds complexity and requires you to automate steps that are manually done before deployment by data scientists to train and validate new models.
Production: ML models can have reduced performance not only due to suboptimal coding, but also due to constantly evolving data profiles. In other words, models can decay in more ways than conventional software systems, and you need to consider this degradation. Therefore, you need to track summary statistics of your data and monitor the online performance of your model to send notifications or roll back when values deviate from your expectations.
ML and other software systems are similar in continuous integration of source control, unit testing, integration testing, and continuous delivery of the software module or the package. However, in ML, there are a few notable differences:
CI is no longer only about testing and validating code and components, but also testing and validating data, data schemas, and models.
CD is no longer about a single software package or a service, but a system (an ML training pipeline) that should automatically deploy another service (model prediction service).
CT is a new property, unique to ML systems, that's concerned with automatically retraining and serving the models. …”
We can conclude that machine learning and artificial intelligence that are used with real-time data require a broader set of instruments and competences (from code development to mathematical modeling environment orchestration), a tighter integration among all the functional and subject domains, a better management of human and machine resources.
A real-time scenario: recognition of developing defects in feed pumps
Continuing to use the area of manufacturing process management, we will walk through a practical case (already referenced in the beginning): there is a need to set up a real-time recognition of developing defects in feed pumps based on a flow of manufacturing process parameter values as well as on maintenance personnel’s reports on detected defects. Figure 2 Developing defect recognition case formulation
One of the characteristics of many similar cases, in practice, is that regularity and timeliness of the data feeds (SCADA) need to be considered in line with episodic and irregular detection (and recording) of various defect types. In different words: SCADA data is fed once a second all set for analysis, while defects are recorded using a pencil in a copybook indicating a date (for example: “Jan 12 – leakage into cover from 3rd bearing zone”). Therefore, we could complement the case formulation by adding the following important restriction: we have only one “fingerprint” of a concrete defect type (i.e. the concrete defect type is represented by the SCADA data as of the concrete date – and we have no other examples for this particular defect type). This restriction immediately sets us outside of the classical machine learning paradigm (supervised learning) that presumes that “fingerprints” are available in large quantity. Figure 3 Elaborating the defect recognition case formulation
Can we somehow “multiply” the “fingerprint” that we have available? Yes, we can. The current condition of the pump is characterized by its similarity to the already recorded defects. Even without quantitative methods applied, just by observing the dynamics of the parameter values received from the SCADA system, much could be learnt: Figure 4 Pump condition dynamics vs. the concrete defect type “fingerprint”
However, visual perception (at least, for now) – is not the most suitable generator of machine learning “labels” in our dynamically progressing scenario. We will be estimating the similarity of the current pump condition to the already recorded defects using a statistical test. Figure 5 A statistical test applied to incoming data vs. the defect “fingerprint”
The statistical test estimates a probability for a set of records with manufacturing process parameter values, acquired as a “batch” from the SCADA system, to be similar to the records from the concrete defect “fingerprint”. The probability estimated using the statistical test (statistical similarity index) is then transformed to either 0 or 1, becoming the machine learning “label” in each of the records of the set that we evaluate for similarity. I.e., once the acquired batch of pump condition records are processed using the statistical test, we obtain the capacity to (a) add that batch to the training dataset for AI/ML models and (b) to assess the accuracy of AI/ML model current versions when applied to that batch. Figure 6 Machine learning models applied to incoming data vs. the defect “fingerprint”
In one of our previous webinars we show and explain how InterSystems IRIS platform allows implementing any AI/ML mechanism as continually executed business processes that control the modeling output likelihood and adapt the model parameters. The implementation of our pumps scenario relies on the complete InterSystems IRIS functionality presented in the webinar – using in the analyzer process, part of our solution, reinforcement learning through automated management of the training dataset, rather than classical supervised learning. We are adding to the training dataset the records that demonstrate “detection consensus” after being applied both the statistical test (with the similarity index transformed to either 0 or 1) and the current version of the model – i.e. both the statistical test and the model have produced on such records the output of 1. At model retraining, at its validation (when the newly trained model is applied to its own training dataset, after a prior application of the statistical test to that dataset), the records that “failed to maintain” the output of 1 once the statistical test applied to them (due to a permanent presence in the training dataset of the records belonging to the original defect “fingerprint”) are removed from the training dataset, and a new version of the model is trained on the defect “fingerprint” plus the records from the flow that “succeeded”. Figure 7 Robotization of AI/ML computations in InterSystems IRIS
In the case of a need to have a “second opinion” on the detection accuracy obtained through local computations in InterSystems IRIS, we can create an advisor process to redo the model training/application on a control dataset using cloud providers (for example: Microsoft Azure, Amazon Web Services, Google Cloud Platform, etc.): Figure 8 «Second opinion» from Microsoft Azure orchestrated by InterSystems IRIS
The prototype of our scenario is implemented in InterSystems IRIS as an agent system of analytical processes interacting with the piece of equipment (the pump), the mathematical modeling environments (Python, R and Julia), and supporting self-training of all the involved AI/ML mechanisms – based on real-time data flows. Figure 9 Core functionality of the real-time AI/ML solution in InterSystems IRIS
Some practical results obtained due to our prototype:
The defect’s “fingerprint” detected by the models (January 12th):
The developing defect not included in the “fingerprints” known to the prototype, detected by the models (September 11th, while the defect itself was discovered by a maintenance brigade two days later – on September 13th):
A simulation on real-life data containing several occurrences of the same defect has shown that our solution implemented using InterSystems IRIS platform can detect a developing defect several days before it is discovered by a maintenance brigade.
InterSystems IRIS — the all-purpose universal platform for real-time AI/ML computations
InterSystems IRIS is a complete, unified platform that simplifies the development, deployment, and maintenance of real-time, data-rich solutions. It provides concurrent transactional and analytic processing capabilities; support for multiple, fully synchronized data models (relational, hierarchical, object, and document); a complete interoperability platform for integrating disparate data silos and applications; and sophisticated structured and unstructured analytics capabilities supporting batch and real-time use cases. The platform also provides an open analytics environment for incorporating best-of-breed analytics into InterSystems IRIS solutions, and it offers flexible deployment capabilities to support any combination of cloud and on-premises deployments. Applications powered by InterSystems IRIS platform are currently in use with various industries helping companies receive tangible economic benefits in strategic and tactical run, fostering informed decision making and removing the “gaps” among event, analysis, and action. Figure 10 InterSystems IRIS architecture in the real-time AI/ML context
Same as the previous diagram, the below diagram combines the new “basis” (CD/CI/CT) with the information flows among the working elements of the platform. Visualization begins with CD macromechanism and continues through CI/CT macromechanisms. Figure 11 Diagram of information flows among AI/ML working elements of InterSystems IRIS platform
The essentials of CD mechanism in InterSystems IRIS: the platform users (the AI/ML solution developers) adapt the already existing and/or create new AI/ML mechanisms using a specialized AI/ML code editor: Jupyter (the full title: Jupyter Notebook; for brevity, the documents created in this editor are also often called by the same title). In Jupyter, a developer can write, debug and test (using visual representations, as well) a concrete AI/ML mechanism before its transmission (“deployment”) to InterSystems IRIS. It is clear that the new mechanism developed in such a manner will enjoy only a basic debugging (in particular, because Jupyter does not handle real-time data flows) – but we are fine with that since the main objective of developing code in Jupyter is verification, in principle, of the functioning of a separate AI/ML mechanism. In a similar fashion, an AI/ML mechanism already deployed in the platform (see the other macromechanisms) may require a “rollback” to its “pre-platform” version (reading data from files, accessing data via xDBC instead of local tables or globals – multi-dimensional data arrays in InterSystems IRIS – etc.) before debugging. An important distinctive aspect of CD implementation in InterSystems IRIS: there is a bidirectional integration between the platform and Jupyter that allows deploying in the platform (with a further in-platform processing) Python, R and Julia content (all the three being programming languages of their respective open-source mathematical modeling leader environments). That said, AI/ML content developers obtain a capability to “continuously deploy” their content in the platform while working in their usual Jupyter editor with usual function libraries available through Python, R, Julia, delivering basic debugging (in case of necessity) outside the platform. Continuing with CI macromechanism in InterSystems IRIS. The diagram presents the macroprocess for a “real-time robotizer” (a bundle of data structures, business processes and fragments of code in mathematical environment languages, as well as in ObjectScript – the native development language of InterSystems IRIS – orchestrated by them). The objective of the macroprocess is: to support data processing queues required for the functioning of AI/ML mechanisms (based on the data flows transmitted into the platform in real time), to make decisions on sequencing and “assortment” of AI/ML mechanisms (a.k.a. “mathematical algorithms”, “models”, etc. – can be called in a number of different ways depending on implementation specifics and terminology preferences), to keep up to date the analytical structures for intelligence around AI/ML outputs (cubes, tables, multidimensional data arrays, etc. – resulting into reports, dashboards, etc.). An important distinctive aspect of CI implementation in InterSystems IRIS: there is a bidirectional integration among the platform and mathematical modeling environments that allows executing in-platform content written in Python, R or Julia in the respective environments and receiving back execution results. That integration works both in a “terminal mode” (i.e., the AI/ML content is formulated as ObjectScript code performing callouts to mathematical environments), and in a “business process mode” (i.e., the AI/ML content is formulated as a business process using the visual composer, or, sometimes, using Jupyter, or, sometimes, using an IDE – IRIS Studio, Eclipse, Visual Studio Code). The availability of business processes for editing in Jupyter is specified using a link between IRIS within CI layer and Jupyter within CD layer. A more detailed overview of integration with mathematical modeling environments is provided further in this text. At this point, in our opinion, there are all reasons to state the availability in the platform of all the tooling required for implementing “continuous integration” of AI/ML mechanisms (originating from “continuous deployment”) into real-time AI/ML solutions. And finally, the crucial macromechanism: CT. Without it, there will be no AI/ML platform (even if “real time” can be implemented via CD/CI). The essence of CT is the ability of the platform to operate the “artifacts” of machine learning and artificial intelligence directly in the sessions of mathematical modeling environments: models, distribution tables, vectors/matrices, neural network layers, etc. This “interoperability”, in the majority of the cases, is manifested through creation of the mentioned artifacts in the environments (for example, in the case of models, “creation” consists of model specification and subsequent estimation of its parameters – the so-called “training” of a model), their application (for models: computation with their help of the “modeled” values of target variables – forecasts, category assignments, event probabilities, etc.), and improvement of the already created plus applied artifacts (for example, through re-definition of the input variables of a model based on its performance – in order to improve forecast accuracy, as one possible option). The key property of CT role is its “abstraction” from CD and CI reality: CT is there to implement all the artifacts using computational and mathematical specifics of an AI/ML solution, within the restrictions existing in concrete environments. The responsibility for “input data supply” and “outputs delivery” will be borne by CD and CI. An important distinctive aspect of CT implementation in InterSystems IRIS: using the above-mentioned integration with mathematical modeling environments, the platform can extract their artifacts from sessions in the mathematical environments orchestrated by it, and (the most important) convert them into in-platform data objects. For example, a distribution table just created in a Python session can be (without pausing the Python session) transferred into the platform as, say, a global (a multidimensional data array in InterSystems IRIS) – and further re-used for computations in a different AI/ML mechanism (implemented using the language of a different environment – like R) – or as a virtual table. Another example: in parallel with “routine” functioning of a model (in a Python session), its input dataset is processed using “auto ML” – an automated search for optimized input variables and model parameters. Together with “routine” training, the production model receives in real time “optimization suggestions” as to basing its specification on an adjusted set of input variables, on adjusted model parameter values (no longer as an outcome of training in Python, but as the outcome of training of an “alternative” version of it using, for example, H2O framework), allowing the overall AI/ML solution to handle in an autonomous way unforeseen drift in the input data and in the modeled objects/processes. We will now take a closer look at the in-platform AI/ML functionality of InterSystems IRIS using an existing prototype as example. In the below diagram, in the left part of the image we see the fragment of a business process that implements execution of Python and R scripts. In the central part – we see the visual logs following execution of those scripts, in Python and in R accordingly. Next after them – examples of the content in both languages, passed for execution in respective environments. In the right part – visualizations based on the script outputs. The visualizations in the upper right corner are developed using IRIS Analytics (the data is transferred from Python to InterSystems IRIS platform and is put on a dashboard using platform functionality), in the lower right corner – obtained directly in R session and transferred from there to graphical files. An important remark: the discussed business process fragment is responsible in this prototype for model training (equipment condition classification) based on the data received in real time from the equipment imitator process, that is triggered by the classification accuracy monitor process that monitors performance of the classification model as it is being applied. Implementing an AI/ML solution as a set of interacting business processes (“agents”) will be discussed further in the text. Figure 12 Interaction with Python, R and Julia in InterSystems IRIS
In-platform processes (a.k.a. “business processes”, “analytical processes”, “pipelines”, etc.– depending on the context) can be edited, first of all, using the visual business process composer in the platform, in such a way that both the process diagram and its corresponding AI/ML mechanism (code) are created at the same time. By saying “an AI/ML mechanism is created”, we mean hybridity from the very start (at a process level): the content written in the languages of mathematical modeling environments neighbors the content written in SQL (including IntegratedML extensions), in InterSystems ObjectScript, as well as other supported languages. Moreover, the in-platform paradigm opens a very wide spectrum of capability for “drawing” processes as sets of embedded fragments (as shown in the below diagram), helping with efficient structuring of sometimes rather complex content, avoiding “dropouts” from visual composition (to “non-visual” methods/classes/procedures, etc.). I.e., in case of necessity (likely in most projects), the entire AI/ML solution can be implemented in a visual self-documenting format. We draw your attention to the central part of the below diagram that illustrates a “higher-up embedding layer” and shows that apart from model training as such (implemented using Python and R), there is analysis of the so-called ROC curve of the trained model allowing to assess visually (and computationally) its training quality – this analysis is implemented using Julia language (executes in its respective Julia environment). Figure 13 Visual AI/ML solution composition environment in InterSystems IRIS
As mentioned before, the initial development and (in other cases) adjustment of the already implemented in-platform AI/ML mechanisms will be performed outside the platform in Jupyter editor. In the below diagram we can find an example of editing an existing in-platform process (the same process as in the diagram above) – this is how its model training fragment looks in Jupyter. The content in Python language is available for editing, debugging, viewing inline graphics in Jupyter. Changes (if required) can be immediately replicated to the in-platform process, including its production version. Similarly, newly developed content can be replicated to the platform (a new in-platform process is created automatically). Figure 14 Using Jupyter Notebook to edit an in-platform AI/ML mechanism in InterSystems IRIS
Editing of an in-platform process can be performed not only in a visual or a notebook format – but in a “complete” IDE (Integrated Development Environment) format as well. The IDEs being IRIS Studio (the native IRIS development studio), Visual Studio Code (an InterSystems IRIS extension for VSCode) and Eclipse (Atelier plugin). In certain cases, simultaneous usage by a development team of all the three IDEs is possible. In the diagram below we see an example of editing all the same process in IRIS Studio, in Visual Studio Code and in Eclipse. Absolutely any portion of the content is available for editing: Python/R/Julia/SQL, ObjectScript and the business process elements. Figure 15 Editing of an InterSystems IRIS business process in various IDE
The means of composition and execution of business processes in InterSystems IRIS using Business Process Language (BPL), are worth a special mentioning. BPL allows using “pre-configured integration components” (activities) in business processes – which, properly speaking, give us the right to state that IRIS supports “continuous integration”. Pre-configured business process components (activities and links among them) are extremely powerful accelerators for AI/ML solution assembly. And not only for assembly: due to activities and their links, an “autonomous management layer” is introduced above disparate AI/ML mechanisms, capable of making real-time decisions depending on the situation. Figure 16 Pre-configured business process components for continuous integration (CI) in InterSystems IRIS platform
The concept of agent systems (a.k.a. “multiagent systems”) has strong acceptance in robotization, and InterSystems IRIS platform provides organic support for it through its “production/process” construct. Besides unlimited capabilities for “arming” each process with the functionality required for the overall solution, “agency” as the property of an in-platform processes family, enables creation of efficient solutions for very unstable modeled phenomena (behavior of social/biological systems, partially observed manufacturing processes, etc.). Figure 17 Functioning AI/ML solution in the form of an agent system of business processes in InterSystems IRIS
We proceed with our overview of InterSystems IRIS platform by presenting applied use domains containing solutions for entire classes of real-time scenarios (a fairly detailed discovery of some of the in-platform AI/ML best practices based on InterSystems IRIS is provided in one of our previous webinars). In “hot pursuit” of the above diagram, we provide below a more illustrative diagram of an agent system. In that diagram, the same all prototype is shown with its four agent processes plus the interactions among them: GENERATOR – simulates data generation by equipment sensors, BUFFER – manages data processing queues, ANALYZER – executes machine learning, properly speaking, MONITOR – monitors machine learning quality and signals the necessity for model retrain. Figure 18 Composition of an AI/ML solution in the form of an agent system of business processes in InterSystems IRIS
The diagram below illustrates the functioning of a different robotized prototype (text sentiment analysis) over a period. In the upper part – the model training quality metric evolution (quality increasing), in the lower part – dynamics of the model application quality metric and retrains (red stripes). As we can see, the solution has shown an effective and autonomous self-training while continuing to function at the required level of quality (the quality metric values stay above 80%). Figure 19 Continuous (self-)training (CT) based on InterSystems IRIS platform
We were already mentioning “auto ML” before, and in the below diagram we are now providing more details about this functionality using one other prototype as an example. In the diagram of a business process fragment, we see an activity that launches modeling in H2O framework, as well as the outcomes of that modeling (a clear supremacy of the obtained model in terms of ROC curves, compared to the other “hand-made” models, plus automated detection of the “most influential variables” among the ones available in the original dataset). An important aspect here is the saving of time and expert resources that is gained due to “auto ML”: our in-platform process delivers in half a minute what may take an expert from one week to one month (determining and proofing of an optimal model). Figure 20 “Auto ML” embedded in an AI/ML solution based on InterSystems IRIS platform
The diagram below “brings down the culmination” while being a sound option to end the story about the classes of real-time scenarios: we remind that despite all the in-platform capabilities of InterSystems IRIS, training models under its orchestration is not compulsory. The platform can receive from an external source a so-called PMML specification of a model that was trained in an instrument that is not being orchestrated by the platform – and then keep applying that model in real time from the moment of its PMML specification import. It is important to keep in mind that not every given AI/ML artifact can be resolved into a PMML specification, although the majority of the most widely used AI/ML artifacts allow doing this. Therefore, InterSystems IRIS platform has an “open circuit” and means zero “platform slavery” for its users. Figure 21 Model application based on its PMML specification in InterSystems IRIS platform
Let us mention the additional advantages of InterSystems IRIS platform (for a better illustration, with reference to manufacturing process management) that have major importance for real-time automation of artificial intelligence and machine learning:
Powerful integration framework for interoperability with any data sources and data consumers (SCADA, equipment, MRO, ERP, etc.)
Built-in multi-model database management system for high-performance hybrid transactional and analytical processing (HTAP) of unlimited volume of manufacturing process data
Development environment for continuous deployment of AI/ML mechanisms into real-time solutions based on Python, R, Julia
Adaptive business processes for continuous integration into real-time solutions and (self-)training of AI/ML mechanisms
Built-in business intelligence capabilities for manufacturing process data and AI/ML solution outputs visualization
API Management to deliver AI/ML outputs to SCADA, data marts/warehouses, notification engines, etc.
AI/ML solutions implemented in InterSystems IRIS platform easily adapt to existing IT infrastructure. InterSystems IRIS secures high reliability of AI/ML solutions due to high availability and disaster recovery configuration support, as well as flexible deployment capability in virtual environments, at physical servers, in private and public clouds, in Docker containers. That said, InterSystems IRIS is indeed the all-purpose universal platform for real-time AI/ML computations. The all-purpose nature of our platform is proven in action through the de-facto absence of restrictions on the complexity of implemented computations, the ability of InterSystems IRIS to combine (in real time) execution of scenarios from various industries, the exceptional adaptability of any in-platform functions and mechanisms to concrete needs of the users. Figure 22 InterSystems IRIS — the all-purpose universal platform for real-time AI/ML computations
For a more specific dialog with those of our audience that found this text interesting, we would recommend proceeding to a “live” communication with us. We will readily provide support with formulation of real-time AI/ML scenarios relevant to your company specifics, run collaborative prototyping based on InterSystems IRIS platform, design and execute a roadmap for implementation of artificial intelligence and machine learning in your manufacturing and management processes. The contact e-mail of our AI/ML expert team – MLToolkit@intersystems.com.
Article
Guillaume Rongier · Dec 14, 2021
# Iris-python-template
Template project with various Python code to be used with InterSystems IRIS Community Edition with container.
Featuring :
* Notebooks
* Embedded Python Kernel
* ObjectScript Kernel
* Vanilla Python Kernel
* Embedded Python
* Code example
* Flask demo
* IRIS Python Native APIs
* Code example
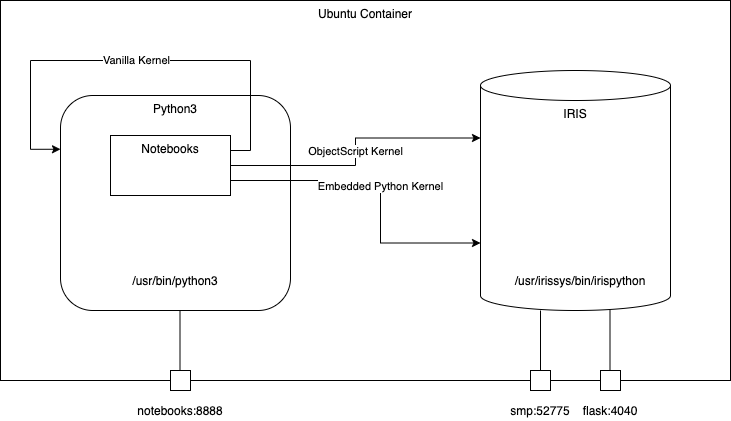
# 2. Table of Contents
- [1. iris-python-template](#1-iris-python-template)
- [2. Table of Contents](#2-table-of-contents)
- [3. Installation](#3-installation)
- [3.1. Docker](#31-docker)
- [4. How to start coding](#4-how-to-start-coding)
- [4.1. Prerequisites](#41-prerequisites)
- [4.1.1. Start coding in ObjectScript](#411-start-coding-in-objectscript)
- [4.1.2. Start coding with Embedded Python](#412-start-coding-with-embedded-python)
- [4.1.3. Start coding with Notebooks](#413-start-coding-with-notebooks)
- [5. What's inside the repository](#5-whats-inside-the-repository)
- [5.1. Dockerfile](#51-dockerfile)
- [5.2. .vscode/settings.json](#52-vscodesettingsjson)
- [5.3. .vscode/launch.json](#53-vscodelaunchjson)
- [5.4. .vscode/extensions.json](#54-vscodeextensionsjson)
- [5.5. src folder](#55-src-folder)
- [5.5.1. src/ObjectScript](#551-srcobjectscript)
- [5.5.1.1. src/ObjectScript/Embedded/Python.cls](#5511-srcobjectscriptembeddedpythoncls)
- [5.5.1.2. src/ObjectScript/Gateway/Python.cls](#5512-srcobjectscriptgatewaypythoncls)
- [5.5.2. src/Python](#552-srcpython)
- [5.5.2.1. src/Python/embedded/demo.cls](#5521-srcpythonembeddeddemocls)
- [5.5.2.2. src/Python/native/demo.cls](#5522-srcpythonnativedemocls)
- [5.5.2.3. src/Python/flask](#5523-srcpythonflask)
- [5.5.2.3.1. How it works](#55231-how-it-works)
- [5.5.2.3.2. Launching the flask server](#55232-launching-the-flask-server)
- [5.5.3. src/Notebooks](#553-srcnotebooks)
- [5.5.3.1. src/Notebooks/HelloWorldEmbedded.ipynb](#5531-srcnotebookshelloworldembeddedipynb)
- [5.5.3.2. src/Notebooks/IrisNative.ipynb](#5532-srcnotebooksirisnativeipynb)
- [5.5.3.3. src/Notebooks/ObjectScript.ipynb](#5533-srcnotebooksobjectscriptipynb)
# 3. Installation
## 3.1. Docker
The repo is dockerised so you can clone/git pull the repo into any local directory
```
git clone https://github.com/grongierisc/iris-python-template.git
```
Open the terminal in this directory and run:
```
docker-compose up -d
```
and open then http://localhost:8888/tree for Notebooks
Or, open the cloned folder in VSCode, start docker-compose and open the URL via VSCode menu:
# 4. How to start coding
## 4.1. Prerequisites
Make sure you have [git](https://git-scm.com/book/en/v2/Getting-Started-Installing-Git) and [Docker desktop](https://www.docker.com/products/docker-desktop) installed.
This repository is ready to code in VSCode with ObjectScript plugin.
Install [VSCode](https://code.visualstudio.com/), [Docker](https://marketplace.visualstudio.com/items?itemName=ms-azuretools.vscode-docker) and [ObjectScript](https://marketplace.visualstudio.com/items?itemName=daimor.vscode-objectscript) plugin and open the folder in VSCode.
### 4.1.1. Start coding in ObjectScript
Open /src/ObjectScript/Embedded/Python.cls class and try to make changes - it will be compiled in running IRIS docker container.
### 4.1.2. Start coding with Embedded Python
The easiest way is to run VsCode in the container.
To attach to a Docker container, either select **Remote-Containers: Attach to Running Container...** from the Command Palette (`kbstyle(F1)`) or use the **Remote Explorer** in the Activity Bar and from the **Containers** view, select the **Attach to Container** inline action on the container you want to connect to.

Then configure your python interpreter to /usr/irissys/bin/irispython
### 4.1.3. Start coding with Notebooks
Open this url : http://localhost:8888/tree
Then you have access to three different notebooks with three different kernels.
* Embedded Python kernel
* ObjectScript kernel
* Vanilla python3 kernel
# 5. What's inside the repository
## 5.1. Dockerfile
A dockerfile which install some python dependancies (pip, venv) and sudo in the container for conviencies.
Then it create the dev directory and copy in it this git repository.
It starts IRIS and imports Titanics csv files, then it activates **%Service_CallIn** for **Python Shell**.
Use the related docker-compose.yml to easily setup additional parametes like port number and where you map keys and host folders.
This dockerfile ends with the installation of requirements for python modules.
The last part is about installing jupyter notebook and it's kernels.
Use .env/ file to adjust the dockerfile being used in docker-compose.
## 5.2. .vscode/settings.json
Settings file to let you immedietly code in VSCode with [VSCode ObjectScript plugin](https://marketplace.visualstudio.com/items?itemName=daimor.vscode-objectscript)
## 5.3. .vscode/launch.json
Config file if you want to debug with VSCode ObjectScript
[Read about all the files in this article](https://community.intersystems.com/post/dockerfile-and-friends-or-how-run-and-collaborate-objectscript-projects-intersystems-iris)
## 5.4. .vscode/extensions.json
Recommendation file to add extensions if you want to run with VSCode in the container.
[More information here](https://code.visualstudio.com/docs/remote/containers)

This is very useful to work with embedded python.
## 5.5. src folder
This folder is devied in two parts, one for ObjectScript example and one for Python code.
### 5.5.1. src/ObjectScript
Different piece of code that shows how to use python in IRIS.
#### 5.5.1.1. src/ObjectScript/Embedded/Python.cls
All comments are in french to let you impove your French skills too.
```objectscript
/// Embedded python example
Class ObjectScript.Embbeded.Python Extends %SwizzleObject
{
/// HelloWorld with a parameter
ClassMethod HelloWorld(name As %String = "toto") As %Boolean [ Language = python ]
{
print("Hello",name)
return True
}
/// Description
Method compare(modèle, chaine) As %Status [ Language = python ]
{
import re
# compare la chaîne [chaîne] au modèle [modèle]
# affichage résultats
print(f"\nRésultats({chaine},{modèle})")
match = re.match(modèle, chaine)
if match:
print(match.groups())
else:
print(f"La chaîne [{chaine}] ne correspond pas au modèle [{modèle}]")
}
/// Description
Method compareObjectScript(modèle, chaine) As %Status
{
w !,"Résultats("_chaine_","_modèle_")",!
set matcher=##class(%Regex.Matcher).%New(modèle)
set matcher.Text=chaine
if matcher.Locate() {
write matcher.GroupGet(1)
}
else {
w "La chaîne ["_chaine_"] ne correspond pas au modèle ["_modèle_"]"
}
}
/// Description
Method DemoPyhtonToPython() As %Status [ Language = python ]
{
# expression régulières en python
# récupérer les différents champs d'une chaîne
# le modèle : une suite de chiffres entourée de caractères quelconques
# on ne veut récupérer que la suite de chiffres
modèle = r"^.*?(\d+).*?$"
# on confronte la chaîne au modèle
self.compare(modèle, "xyz1234abcd")
self.compare(modèle, "12 34")
self.compare(modèle, "abcd")
}
Method DemoPyhtonToObjectScript() As %Status [ Language = python ]
{
# expression régulières en python
# récupérer les différents champs d'une chaîne
# le modèle : une suite de chiffres entourée de caractères quelconques
# on ne veut récupérer que la suite de chiffres
modèle = r"^.*?(\d+).*?$"
# on confronte la chaîne au modèle
self.compareObjectScript(modèle, "xyz1234abcd")
self.compareObjectScript(modèle, "12 34")
self.compareObjectScript(modèle, "abcd")
}
/// Description
Method DemoObjectScriptToPython() As %Status
{
// le modèle - une date au format jj/mm/aa
set modèle = "^\s*(\d\d)\/(\d\d)\/(\d\d)\s*$"
do ..compare(modèle, "10/05/97")
do ..compare(modèle, " 04/04/01 ")
do ..compare(modèle, "5/1/01")
}
}
```
* HelloWorld
* Simple function to say Hello in python
* It uses the OjectScript wrapper with the tag [ Language = python ]
* compare
* An python function that compare a string with a regx, if their is a match then print it, if not print that no match has been found
* compareObjectScript
* Same function as the python one but in ObjectScript
* DemoPyhtonToPython
* Show how to use a python function with python code wrapped in ObjectScript
```objectscript
set demo = ##class(ObjectScript.Embbeded.Python).%New()
zw demo.DemoPyhtonToPython()
```
* DemoPyhtonToObjectScript
* An python function who show how to call an ObjecScript function
* DemoObjectScriptToPython
* An ObjectScript function who show how to call an python function
#### 5.5.1.2. src/ObjectScript/Gateway/Python.cls
An ObjectScript class who show how to call an external phyton code with the gateway functionnality.
In this example python code is **not executed** in the same process of IRIS.
```objectscript
/// Description
Class Gateway.Python
{
/// Demo of a python gateway to execute python code outside of an iris process.
ClassMethod Demo() As %Status
{
Set sc = $$$OK
set pyGate = $system.external.getPythonGateway()
d pyGate.addToPath("/irisdev/app/src/Python/gateway/Address.py")
set objectBase = ##class(%Net.Remote.Object).%New(pyGate,"Address")
set street = objectBase.street
zw street
Return sc
}
}
```
### 5.5.2. src/Python
Different piece of python code that shows how to use embedded python in IRIS.
#### 5.5.2.1. src/Python/embedded/demo.cls
All comments are in french to let you impove your French skills too.
```python
import iris
person = iris.cls('Titanic.Table.Passenger')._OpenId(1)
print(person.__dict__)
```
First import iris module that enable embedded python capabilities.
Open an persistent class with cls function from iris module.
Note that all `%` function are replaced with `_`.
To run this example you have to use iris python shell :
```shell
/usr/irissys/bin/irispython /opt/irisapp/src/Python/embedded/demo.py
```
#### 5.5.2.2. src/Python/native/demo.cls
Show how to use native api in python code.
```python
import irisnative
# create database connection and IRIS instance
connection = irisnative.createConnection("localhost", 1972, "USER", "superuser", "SYS", sharedmemory = False)
myIris = irisnative.createIris(connection)
# classMethod
passenger = myIris.classMethodObject("Titanic.Table.Passenger","%OpenId",1)
print(passenger.get("name"))
# global
myIris.set("hello","myGlobal")
print(myIris.get("myGlobal"))
```
To import irisnative, you have to install the native api wheels in your python env.
```shell
pip3 install /usr/irissys/dev/python/intersystems_irispython-3.2.0-py3-none-any.whl
```
Then you can run this python code
```shell
/usr/bin/python3 /opt/irisapp/src/Python/native/demo.py
```
Note that in this case a connection is made to iris database, this mean, **this code is executed in a different thread than the IRIS one**.
#### 5.5.2.3. src/Python/flask
A full demo of the combiantion between embedded python and the micro framework flask.
You can test this end point :
```
GET http://localhost:4040/api/passengers?currPage=1&pageSize=1
```
##### 5.5.2.3.1. How it works
In order to use embedded Python, we use `irispython` as a python interepreter, and do:
```python
import iris
```
Right at the beginning of the file.
We will then be able to run methods such as:
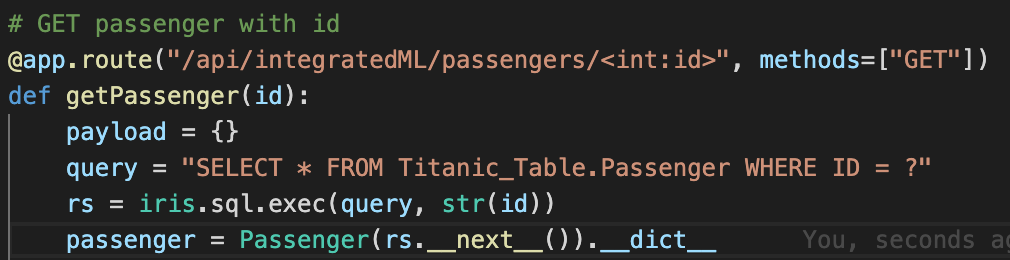
As you can see, in order to GET a passenger with an ID, we just execute a query and use its result set.
We can also directly use the IRIS objects:
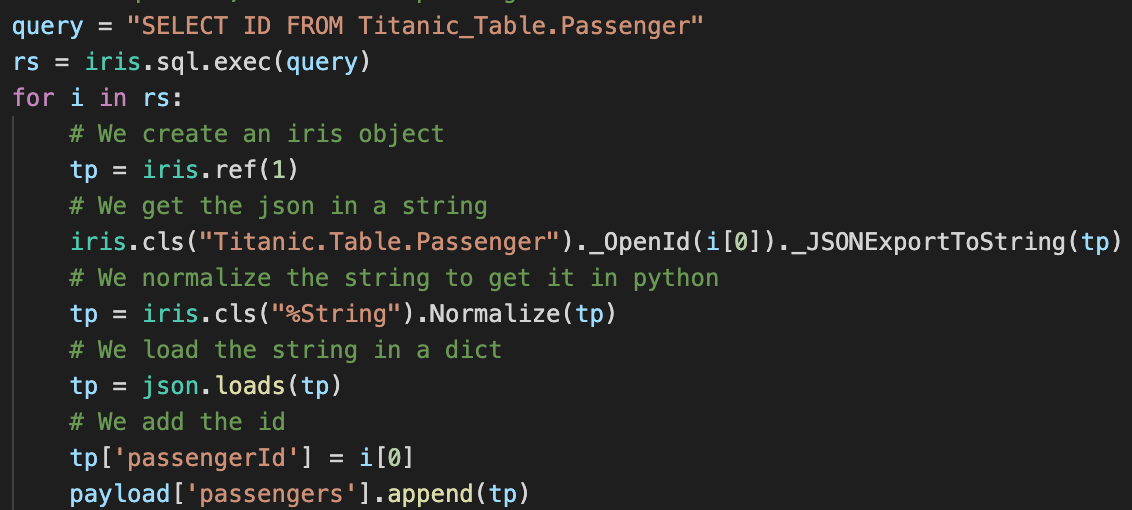
Here, we use an SQL query to get all the IDs in the table, and we then retreive each passenger from the table with the `%OpenId()` method from the `Titanic.Table.Passenger` class (note that since `%` is an illegal character in Python, we use `_` instead).
Thanks to Flask, we implement all of our routes and methods that way.
##### 5.5.2.3.2. Launching the flask server
To launch the server, we use `gunicorn` with `irispython`.
In the docker-compose file, we add the following line:
````yaml
iris:
command: -a "sh /opt/irisapp/server_start.sh"
````
That will launch, after the container is started (thanks to the `-a` flag), the following script:
````bash
#!/bin/bash
cd ${SRC_PATH}/src/Python/flask
${PYTHON_PATH} -m gunicorn --bind "0.0.0.0:8080" wsgi:app &
exit 1
````
With the environment variables defined in the Dockerfile as follows:
````dockerfile
ENV PYTHON_PATH=/usr/irissys/bin/irispython
ENV SRC_PATH=/opt/irisapp/
````
### 5.5.3. src/Notebooks
Three notebooks with three different kernels :
* One Python3 kernel to run native APIs
* One Embedded Python kernel
* One ObjectScript kernel
Notebooks can be access here http://localhost:8888/tree
#### 5.5.3.1. src/Notebooks/HelloWorldEmbedded.ipynb
This notebook uses IRIS embedded python kernel.
It shows example to open and save persistent classes and how to run sql queries.
#### 5.5.3.2. src/Notebooks/IrisNative.ipynb
This notebook uses vanilla python kernel.
It shows example run iris native apis.
#### 5.5.3.3. src/Notebooks/ObjectScript.ipynb
This notebook uses ObjectScript kernel.
It shows example to run ObjectSCript code and how to use embedded pythoon in ObjectScript.
Hi @Guillaume.Rongier7183 !
I tried to use pip3 in the app and failed. I see it is being installed during the image build, but cannot run it later. What I'm doing wrong? Hi Evgeny,
I confirm that `irispip` is not working, if you want to install python package you shall use `pip3` or `/usr/irissys/bin/irispython -m pip` Great article, @Guillaume.Rongier7183 Thank you very much! In UNIX, irispython -m pip install <package> will give the <package> files group ownership that's appropriate for your IRIS instance.