Clear filter
Question
Jordan Everett · Mar 30, 2023
Hey all,
I have been creating a class to handle file encryption by using GPG keys. I pushed my code out today and my encrypt and decrypt methods weren't working. About a half an hour later in troubleshooting I found out that it needed to be a syntax change. My method has three parameters to it. Examples below:
This is how I was calling it in the test system with no issues:
do gpg.Encrypt()
This is how I was having to call it in my production system to work with no issues:
do gpg.Encrypt("","","")
If I was to enter in my production environment do gpg.Encrypt() I would just get an undefined due to it not interpreting my variables.
It's like on my test system it infers my arguments if they're null, but on my production system they need to be passed in order to be interpreted.
Is there an environment variable in Intersystems that I might be missing that would cause this behavior? This is just out of pure curiosity and isn't a true need, but I just found it interesting/peculiar. What does your method's argument list look like? If it's something like this:
Method Encrypt(pVarA As %String = "", pVarB As %String = "", pVarC As %String = "") As %Status
The pVar* variables above should automatically default to empty strings when the method is called as provided in your first example.
I'm not aware of any system setting that would affect the behavior of unsupplied values for method arguments when they're not defined with an initial value (unlike those in my snippet above).
That doesn't mean that there isn't one, though ...
What's the Undefined config value on TEST and PROD:
zn "%SYS"
set sc=##Class(Config.Miscellaneous).Get(.p)
write p("Undefined")
Here is a snippet of my arguments. I don't have them set to a default value which wouldn't be a bad practice to get into anyways.
Method Encrypt(pDirectory As %String, pDelete As %Boolean, pLog As %Boolean) As %Status On my production box it is a 0 and on my test system it is a 2. Well I guess there IS a setting (thanks, @Eduard.Lebedyuk!)
The parameter Undefined specifies the behavior when ObjectScript attempts to fetch the value of a variable that has not been defined. The value of Undefined may be 0, 1, or 2:
0 - Always throw an <UNDEFINED> error. (default)
1 - If the undefined variable has subscripts, return a null string, but if the undefined variable is single-valued, throw an <UNDEFINED> error.
2 - Always return a null string.
You can change that setting in System Administration | System Configuration | Additional Settings | Compatibility. There definitely does seem to be one! I went ahead and set the parameters in the Method and changed my test system to match my production system. Thank you guys so much!
Question
Abdul-Rashid Yakubu · Mar 22, 2022
Hi,
Is there a way to find the median in Intersystems Cache SQL? I know it is not available as an aggregate function. Also in SQL Server I could try something like:
SELECT
(
(SELECT MAX(Score) FROM
(SELECT TOP 50 PERCENT Score FROM Posts ORDER BY Score) AS BottomHalf)
+
(SELECT MIN(Score) FROM
(SELECT TOP 50 PERCENT Score FROM Posts ORDER BY Score DESC) AS TopHalf)
) / 2 AS Median
However, there is no PERCENT Keyword in Cache as well. Any suggestions?
Thanks See Median in SQL As of IRIS 2021.1, we allow users to create their own aggregate functions. Perhaps there's a beautiful community contribution in there? :-)
You could build something simple where you just stuff all values in a temporary global (the name of which you pass as a state) and sort them (using $sortbegin/$sortend), maintaining a count and then in the FINALIZE method gather the actual median value.
Two caveats:
don't bother implementing a MERGE function. We don't support parallel execution just yet.
in some query execution plans, the FINALIZE method may be called more than once (e.g. if the aggregate is used in the SELECT list and say a HAVING clause). So you may want to cache your result somewhere (a PPG will do as this is in the last single-process mile of query processing, typically mere milliseconds apart)
We'll be removing these annoyances in a future version SELECT TOP 1
AVG(main.age) AS _Average,min(main.age) AS _Min,
CASE WHEN %vid = count(main.age)/2 THEN main.age else 0 END+MAX(CASE WHEN %vid = count(main.age)/2 THEN main.age else 0 END) AS _Median,
max(main.age) AS _Max
FROM ( SELECT TOP all a.Age FROM Sample.Person a ORDER BY a.Age ) main Thanks Randy!
Announcement
Todd Patterson · Sep 24, 2021
Intersystems Software Developer – Grand Traverse Plastics Corp.
Location: Williamsburg, MI
Note: This position is an ‘on site’ position.
We are looking for an accomplished InterSystems developer to join our team. Grand Traverse Plastics is a fast growing and leading edge plastics injection molder. With 145 employees and 35 million in annual sales we offer an excellent place to work in one of the nicest areas in the Midwest.
The candidate will assist in the development of our custom ERP system running on Cache. The software has continually evolved over 20+ years and is involved in every aspect of our business. We are looking for a candidate that can leverage their skill to help us interface with things from best of breed accounting packages, BI systems and IoT type devices on our plant floors.
Qualifications:
5+ years with Intersystems Cache/Iris
Cache Object Script as well as Object oriented class development
In depth knowledge of data storage and design with Globals and Classes
SQL, Angular, Java, Python experience helpful
2+ years with Ensemble
Interoperability with various connectors and protocols (APIs, REST, SOAP, XML, EDI)
Linux knowledge a plus
Experience with any of the following: Deep See, Tableau, Power BI, Crystal Reports, Adaptive Analytics
Creative and Innovative mindset
Strong verbal, written and inter-personal skills
Salary: 70k to 90k depending on skill level
If interested, please forward your resume to tpatterson@grand-t.com
Learn more about our exciting company here: https://www.gtpplastics.com
Question
Padmini D · Nov 6, 2020
Hi All,
I am new to InterSystems Cache and want to explore the database features for one of the use cases we have.
I am trying to find the community version of it from in https://download.InterSystems.com but only found InterSystems IRIS and Intersystems IRIS health community versions.
Please help me to download and install this.
Regards,
Sireesha
You can download these versions. Community Edition just has a few limitations, but still can be used. And look at the installation guides Hello Dimitry/Team,
can you please let me know the difference of Intersystems cache DB and intersystems IRIS, we are evaluating it in our POC to implement as a application solution.
Hi Dmitriy/Team,
what is the difference between Intersystems Cache DB and Intersystems IRIS ? I am looking for Cache DB installation details, but getting IRIS only everywhere.
Thanks,
Kranthi. IRIS is a kind of replacement for Caché, which now no active development. So, while you are evaluating it, you should not look for Caché, and switch to IRIS.
Very generally speaking: There is nothing in Caché that you can't do with IRIS.The only thing you might miss eventually, are some ancient compatibility hooks back to the previous millennium. https://cedocs.intersystems.com/latest/csp/docbook/Doc.View.cls?KEY=GCI_windows
Question
Andy Stobirski · Dec 13, 2021
Hi everyone
I see that a new Apache bug has been discovered, and since various InterSystems products use an Apache webserver, have Intersystems released any news or updates on this? I'm not seeing any updates, press releases from them. Anyone know anything?
Andy The Apache HTTP Server is not written in Java (See this StackExchange post)
The security exploit refers to a very popular java logging implementation, log4j. Log4j is published under the Apache Foundations name, but is not to be confused with the Apache http server (also called httpd occasionally).
That said, you might want to check if you are using any Java libraries in your InterSystems products via the Java gateway - and if they are bundled with log4j for logging. Also check if you are having log4j directly in your Java classpath. What you are looking for is the log4j.jar.
If you want to check a library, you can download the jar of the library and open it with 7zip or similar tools, then take a look and check if it contains log4j.jar. If it does, you should get in touch with the creator of the library.
Disclaimer: I am not part of InterSystems, this is of course not an official statement. I am just a Java developer that had to deal with this today a bit! We got an answer from ISC:
====IRIS and Cache do use log4j but our products do not include versions affected by this vulnerability. This vulnerability affects versions from 2.0-beta9 to 2.14.1. The log4j versions used in Cache and IRIS product are based on version 1.x of log4j which is not affected by this issue.====
But of course one can use Log4j 2.* in your own Java applications. You can also open your log4j.jar as you would a zip file, go to the META-INF folder, open MANIFEST.MF and look for "Implementation-Version" to see which version of log4j it is. I'm surprised you got an answer as I was unable to get one over the weekend until ISC makes any official statement. However, re: the 1.x comment:
2031667 – (CVE-2021-4104) CVE-2021-4104 log4j: Remote code execution in Log4j 1.x when application is configured to use JMSAppender (redhat.com)
The only usage of log4j I could find within an ISC platform was on Clinical Viewer. Curious if you could share where it is otherwise seen as being used? Maybe compiled into one of their own libraries and not directly exposed however. Please see the following page for official InterSystems guidance!https://community.intersystems.com/post/december-13-2021-advisory-vulnerability-apache-log4j2-library-affecting-intersystems-products That's interesting!
@Dmitry.Maslennikov posted a quick grep on the community discord and found a few occurrences in the machine learning and fop parts. So I guess these parts are those that might potentially be affected - but actually not, since they are still log4j v1! I'll just repost @Dmitry.Maslennikov grep from the community discord here, which might give you a hint where to look until ISC updated the official statement
$ grep -ir log4j /usr/irissys/
/usr/irissys/lib/RenderServer/runwithfop.bat:rem set LOGCHOICE=-Dorg.apache.commons.logging.Log=org.apache.commons.logging.impl.Log4JLogger
Binary file /usr/irissys/dev/java/lib/h2o/h2o-core-3.26.0.jar matches
Binary file /usr/irissys/dev/java/lib/uima/uimaj-core-2.10.3.jar matches
Binary file /usr/irissys/dev/java/lib/1.8/intersystems-integratedml-1.0.0.jar matches
Binary file /usr/irissys/dev/java/lib/1.8/intersystems-cloudclient-1.0.0.jar matches
Binary file /usr/irissys/dev/java/lib/1.8/intersystems-cloud-manager-1.2.12.jar matches
Binary file /usr/irissys/dev/java/lib/datarobot/datarobot-ai-java-2.0.8.jar matches
/usr/irissys/fop/fop:# LOGCHOICE=-Dorg.apache.commons.logging.Log=org.apache.commons.logging.impl.Log4JLogger
/usr/irissys/fop/fop.bat:rem set LOGCHOICE=-Dorg.apache.commons.logging.Log=org.apache.commons.logging.impl.Log4JLogger
Binary file /usr/irissys/fop/lib/commons-logging-1.0.4.jar matches
Binary file /usr/irissys/fop/lib/avalon-framework-impl-4.3.1.jar matches
/usr/irissys/fop/lib/README.txt: (Logging adapter for various logging backends like JDK 1.4 logging or Log4J)
Binary file /usr/irissys/fop/lib/pdfbox-app-2.0.21.jar matches
Announcement
Jonathan Gern · Jun 16, 2020
My organization is looking for a full time Intersystems Solutions Engineer to join the team. Based in NY, the Solutions Engineer will design technical architectures to support efforts across the health system focused on clinical data exchange with other provider organizations and payors.
Announcement
Neerav Verma · Jan 27, 2021
Hello fellow community members,
I would like to offer my services as an Intersystems Professional and am available to work on projects.
I have more than a decade experience into Intersystems stack of technologies including IRIS, Ensemble, Healthshare, Healthconnect, Cache Objectscript, Mumps, Zen, Analytics etc. with companies spread over US and UK involved in multiple domains.
KEY SKILLS: Cloud Computing (AWS, MS Azure, GCP)Intersystems Technology Stack (IRIS, Ensemble, Healthshare, Cache, Mumps, CSP, ZEN, Analytics)Databases (Modelling & Backend database design, SQL, PL/SQL SOAP & Restful APIsAnalytics & DashboardsHealthcare Interoperability Standards (HL7, FHIR, EDI X12)Notations (XML, JSON) |Agile Frameworks & Tools (Scrum, Kanban, JIRA, Confluence)Dockers | Linux
Recent CertificationsIntersystems IRIS Core Solutions Developer SpecialistIntersystems Health Connect HL7 Interface SpecialistMicrosoft Azure Solutions Architect ExpertCertified Scrum Master
I am keen and open to work on exciting projects which are not only focused on Intersystems stack but also using cloud and having AI/ML functionalities would be wonderful. My ideal role would be a position where I am able to make a strong impact to the project.Current availability : 20 hours a week.Location : London, UK
Please feel free to drop me a line and say Hellonv@nv-enterprises.biz / https://www.linkedin.com/in/vneerav/
RegardsNeerav Verma
Question
Pushyanthkumar Mukkala · Aug 4, 2023
We encountered difficulties while attempting to establish a JDBC connection to Intersystems using AZURE Databricks, resulting in an inability to retrieve data. The JDBC version utilized was intersystems-jdbc-3.3.1.jar. If anyone has successfully employed Databricks for establishing a connection, we would appreciate information regarding the libraries you used
Error Message:org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 3) (10.140.70.71 executor driver): java.sql.SQLException: [SQLCODE: <-25>:<Input encountered after end of query>] What was the query you were trying to run? This looks like an issue with the way the query was written. We followed the instructions in the Spark JDBC connection guide. We think the problem might have something to do with a library, but we're not sure
Below is the query:
cacheDF = spark.read \ .format('jdbc') \ .option('url', connectString) \ .option("query", "select AdjudicatedSvcNum from CLAIMS.AdjudicatedSvcs") \ .option('user', user) \ .option('password', password) \ .option('driver','com.intersystems.jdbc.IRISDriver') \ .load()cacheDF.show() Hi David
We followed the instructions in the Spark JDBC connection guide. We think the problem might have something to do with a library, but we're not sure
Below is the query:
cacheDF = spark.read \ .format('jdbc') \ .option('url', connectString) \ .option("query", "select AdjudicatedSvcNum from CLAIMS.AdjudicatedSvcs") \ .option('user', user) \ .option('password', password) \ .option('driver','com.intersystems.jdbc.IRISDriver') \ .load()cacheDF.show()
I hit this too...Instead of a query, try a dbtable with a query wrapper to a temp_table...
.option("dbtable", "(SELECT name,category,review_point FROM SQLUser.scotch_reviews) AS temp_table;")
check this post for full in and out with jdbc to databricks.https://community.intersystems.com/post/databricks-station-intersystems-cloud-sql Hello Ron
I am using dbtable only
final_result = (spark.read.format("jdbc")\
.option("url", jdbcUrl) .option("driver", "com.intersystems.jdbc.IRISDriver") .option("dbtable", f"({sql}) as temp;") .option("user", user) .option("password", password) .option("sslConnection","true") .load())This works fine until I add one specific column from the same table, when I add that column I get following error < Input (;) encountered after end of query
using - intersystems-jdbc-3.8.0.jarKindly help
Hi @Pushyanthkumar.Mukkala / @Vishwas.Gupta / @David.Hockenbroch / @sween,How did you fixed the issue? I tried below code, which is providing incorrect data. For String datatype columns, it is providing column name as values for rows and for Integer datatype columns, it is providing 0 as values for rows.Could someone assist with this issue? or How to read data from InterSystems Cache DB to Databricks using JDBC?
df = spark.read \
.format("jdbc") \
.option("url", f"jdbc:Cache://{server_ip}:{port}/{namespace}") \
.option("driver", "com.intersys.jdbc.CacheDriver") \
.option("dbtable", "(SELECT * FROM Sample.Company) AS t;") \
.option("user", username) \
.option("password", password) \
.option("fetchsize", "1000") \
.option("pushDownPredicate", "false") \
.option("pushDownAggregate", "false") \
.option("pushDownLimit", "false") \
.load()
df.show()
Below is the output, I received:
Article
Rob Ellis · Dec 13, 2024
The latest "Bringing Ideas to Reality" InterSystems competition saw me trawling through the ideas portal for UI problems to have a go at.
I implemented the following ideas in the IRIS Whiz browser extension, so if you use the management portal to help with your day-to-day integration management this extension could be for you!
Feature Added: Queue refresh
Iris now has an auto refresh dropdown for the Queues page. Will refresh the queue at the interval selected. Does not load on Ensemble as it already has this feature.
Useful if you have an upcoming clicking competition and need to rest your clicking finger.
Implemented from idea: https://ideas.intersystems.com/ideas/DPI-I-487
Feature Added: Export Search as CSV
On the Message Viewer page you can click the Iris Whiz Export button to download a CSV copy of the data currently in your search table.
Useful if you want to do quick analysis on your data but don't want to use the fancy new Chart.JS page I spent ages creating (see that in action here!).
Implemented from idea: https://ideas.intersystems.com/ideas/DPI-I-566
Feature Added: Production Page Queue Sort
Added sort options for the queue tab on the production page. Defaults to sorting by error count. Click a table header to switch between asc and desc sort order. Use the search bar to find items quickly.
Useful if you don’t want to scroll to get to the biggest queue.
Implemented from idea: https://ideas.intersystems.com/ideas/DPI-I-628
Feature Added: Category Dropdown Case-Insensitive Order
Alphabetises the category dropdown list on the production page, regardless of case. Without this the order is case dependent.
Useful if you want to find things in the category list but don’t want to have to re-categorise everything into the same case to do it.
Implemented from idea: https://ideas.intersystems.com/ideas/DPI-I-625
Bonus!
There’s also a refresh rate on the message viewer tab on the production page. This will also refresh your queue tab if you select an interval and navigate to the queue tab.
If you like any of these ideas please download the browser extension and let me know your thoughts. You can find a setup video on the OpenExchange listing which I recommend watching as you will need to complete some of it for most of the functionality to work!
Article
Developer Community Admin · Oct 21, 2015
AbstractA global provider of mobile telecommunications software tested the performance of InterSystems Caché and Oracle as the database in a simulated data mart application. They found Caché to be 41% faster than Oracle at building a data mart. When testing the response time to SQL queries of the data mart, Caché's performance ranged from 1.8 times to 513 times faster than Oracle.IntroductionTelecommunications companies, because they generate and must analyze enormous amounts of information, are among the most demanding database users in the world. In order to make practicable business intelligence solutions, telecommunications firms typically select key pieces of raw data to be loaded into a "data mart", where it is indexed and aggregated in various ways before being made available for analysis. Even so, the data marts in question may be hundreds of gigabytes in size. Database performance, both in the creation of the data mart, and in the query response time of the data mart, is critical to the timely analysis of information, and ultimately to the ability of the enterprise to identify and act upon changes in their business environment.This paper presents the results of comparative performance tests between InterSystems Caché and Oracle. They were performed by a global provider of mobile telecommunications software, as they evaluated database technology for incorporation into a new business intelligence applications relating to mobile phone usage.
Article
Developer Community Admin · Oct 21, 2015
Introduction
In today's world, an ever-increasing number of purchases and payments are being made by credit card. Although merchants and service providers who accept credit cards have an obligation to protect customers' sensitive information, the software solutions they use may not support "best practices" for securing credit card information. To help combat this issue, a security standard for credit card information has been developed and is being widely adopted.The Payment Card Industry (PCI) Data Security Standard (DSS) is a set of guidelines for securely handling credit card information. Among its provisions are recommendations for storing customer information in a database. This paper will outline how software vendors can take advantage of the InterSystems Caché database - now and in the future - to comply with data storage guidelines within the PCI DSS.
using-intersystems-iris-securely-storing-credit-card-data.pdf
Question
Tom Philippi · Feb 25, 2017
I did a clean install of InterSystems ensemble on a new computer. However, even though my OS and my browser are set the English, the Ensemble installation is in dutch. Does anyone know how I can change the language of my InterSystems Studio so that it is in English? In the old way you can choose any language to work. Studio uses language from Regional Settings. Even when system's language is English, but you can use your regional settings (clock, number formats etc). And you can change to use default language inside Studio. Nice, I didn't know that option.In the "old days" I simply rename or delete the CStudioXXX.dll (where XXX denote the language) at bin directory. Then the default english configuration was used.Thanks
Question
Evgeny Shvarov · Apr 5, 2016
Hi! There is a question for Ensemble on Stackoverflow:I have the below dtl. In the foreach loop, I am just copying the same code in another part under anif condition. How can I avoid this redundancy? Can I reuse using sub transformation?Here is the dtl class file :https://docs.google.com/document/d/1snJXElyw13hAfb8Lmg5IaySc7md_DE8J40FB79hBaXU/edit?usp=sharingOriginal question. Hi, Nic!Thank you for your answer!Would you please put it on Stackoverflow too? http://stackoverflow.com/questions/36400699/how-to-avoid-writing-duplicate-code-in-dtl-intersystem-ensembleThank you in advance! Maybe I'm missing something, but it seems like you could have an OR condition to eliminate the code duplication if condition='ExcludeInactiveAllergiesAlerts="No" OR flag'="No"
Announcement
Janine Perkins · Sep 13, 2016
Learn to design, build, implement, and test a new custom business operation in an Ensemble production by taking this online learning course.This course will teach you how to determine when and why to create a custom business operation, design and create a custom business operation for a production, and add a new business operation to a production and configure settings.Learn More.
Article
Murray Oldfield · Mar 25, 2016
This week I am going to look at CPU, one of the primary hardware food groups :) A customer asked me to advise on the following scenario; Their production servers are approaching end of life and its time for a hardware refresh. They are also thinking of consolidating servers by virtualising and want to right-size capacity either bare-metal or virtualized. Today we will look at CPU, in later posts I will explain the approach for right-sizing other key food groups - memory and IO.
So the questions are:
- How do you translate application requirements on a processor from more than five years ago to todays processors?
- Which of the current processors are suitable?
- How does virtualization effect CPU capacity planning?
Added June 2017:
For a deeper dive into the specifics of VMware CPU considerations and planning and some common questions and problems, please also see this post: [Virtualizing large databases - VMware cpu capacity planning](https://community.intersystems.com/post/virtualizing-large-databases-vmware-cpu-capacity-planning)
[A list of other posts in this series is here](https://community.intersystems.com/post/capacity-planning-and-performance-series-index)
# Comparing CPU performance using spec.org benchmarks
To translate CPU usage between processor types for applications built using InterSystems data platforms (Caché, Ensemble, HealthShare) you can use SPECint benchmarks as a reliable back of the envelope calculator for scaling between processors. The [http://www.spec.org](http://www.spec.org) web site has trusted results of a standardised set of benchmarks that are run by hardware vendors.
Specifically SPECint is a way to compare processors between processor models from the same vendors and between different vendors (e.g. Dell, HP, Lenovo, and Intel, AMD, IBM POWER and SPARC). You can use SPECint to understand the expected CPU requirements for your application when hardware is to be upgraded or if your application will be deployed on a range of different customer hardware and you need to set a baseline for a sizing metric, for example peak transactions per CPU core for Intel Xeon E5-2680 (or whatever processor you choose).
There are several benchmarks used on the SPECint web site, however the **SPECint_rate_base2006** results are the best for Caché and have been confirmed over many years looking at customer data and in our own benchmarks.
As an example in this post we will compare the difference between the customers Dell PowerEdge server running Intel Xeon 5570 processors and a current Dell server running Intel Xeon E5-2680 V3 processors. The same methodology can be applied when Intel Xeon V4 server processors are generally available (expected soon as I write this in early 2016).
## Example: Comparing processors
Search the spec.org database for the __SPECint2006_Rates__ for processor name, for example __E5-2680 V3__, further refine your search results if your target server make and model is known (e.g Dell R730), otherwise use a popular vendor, I find Dell or HP models are good baselines of a standard server, there is not usually much variance between processors on different vendor hardware.
> At the end of this post I walk through a step by step example of searching for results using the spec.org web site…
Lets assume you have searched spec.org and have found the existing server and a possible new server as follows:
Existing: Dell PowerEdge R710 with Xeon 5570 2.93 GHz: 8 cores, 2 chips, 4 cores/chip, 2 threads/core:
__SPECint_rate_base2006 = 251__
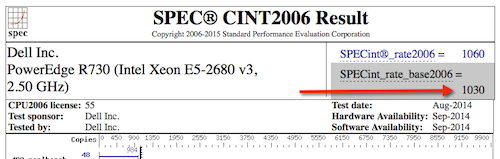
New: PowerEdge R730 with Intel Xeon E5-2680 v3, 2.50 GHz: 24 cores, 2 chips, 12 cores/chip, 2 threads/core:
__SPECint_rate_base2006 = 1030__
Not surprisingly the newer 24-core server has more than 4x increase in SPECint_rate_base2006 benchmark throughput of the older 8-core server even though the newer server has a lower clock speed. Note the examples are two-processor servers that have both processor sockets populated.
### Why is SPECint_rate_base2006 used for Caché?
The spec.org web site has explanations of the various benchmarks, but the summary is the **SPECint_rate2006** benchmark is a complete system-level benchmark uses all CPUs with hyper threading.
Two metrics are reported for a particular SPECint_rate2006 benchmark, _base_ and _peak_. Base is a conservative benchmark, peak is aggressive. For capacity planning use __SPECint_rate_base2006__ results.
## Does four times the SPECint_rate_base2006 mean four times the capacity for users or transactions?
Its possible that if all 24 cores were used the application throughput could scale to four times the capability of the old server. However several factors can cause this milage to vary. SPECint will get you in the ballpark for sizing and throughput that should be possible, but there are a few caveats.
While SPECint gives a good comparison between the two servers in the example above it is not a guarantee that the E5-2680 V3 server will have 75% more capacity for peak concurrent users or peak transaction throughput as the older Xeon 5570 based server. Other factors come into play such as whether the other hardware components in our food groups are upgraded, for example is the new or existing storage capable of servicing the increase in throughput (I will have an in-depth post on storage soon).
Based on my experience benchmarking Caché and looking at customers performance data __Caché is capable of linear scaling to extremely high throughput rates on a single server__ as compute resources (CPU cores) are added, even more so with the year on year improvements in Caché. Put another way I see linear scaling of maximum application throughput, for example application transactions or reflected in Caché glorefs as CPU cores are added. However if there are application bottlenecks they can start to appear at higher transaction rates and impact liner scaling. In later posts I will look at where you can look for symptoms of application bottlenecks. One of the best things you can do to improve application performance capability is to upgrade Caché to the latest version.
> **Note:** For Caché, Windows 2008 servers with more than 64 logical cores are not supported. For example, a 40 core server must have hyper threading disabled. For Windows 2012 up to 640 logical processors are supported. There is no limits on Linux.
## How many cores does the application need?
Applications vary and you know your own applications profile, but the common approach I use when capacity planning CPU for a server (or Virtual Machine) is from diligent system monitoring understanding that a certain number of CPU cores of a certain 'standard' processor can sustain a peak transaction rate of _n_ transactions per minute. These may be episodes, or encounters, lab tests, or whatever makes sense in your world. The point is that the throughput of the standard processor is be based on metrics you have collected on your current system or a customers systems.
If you know your peak CPU resource use today on a known processor with _n_ cores, you can translate to the number of cores required on a newer or different processor for the same transaction rate using the SPECint results. With expected linear scaling 2 x _n_ transactions per minute roughly translates to 2 x the number of cores are required.
## Selecting a processor
As you see from the spec.org web site or looking at your preferred vendor offerings there are many processor choices. The customer in this example is happy with Intel, so if I stick with recommending current Intel servers then one approach is to look for 'bang for buck' - or SPECint_rate_base2006 per dollar and per core. For example the following chart plots Dell commodity servers - your price milage will vary, but this illustrates the point there are sweet spots in price and higher core counts suitable for consolidation of servers using virtualization. I created the chart by pricing a production quality server, for example Dell R730, and then looking at different processor options.
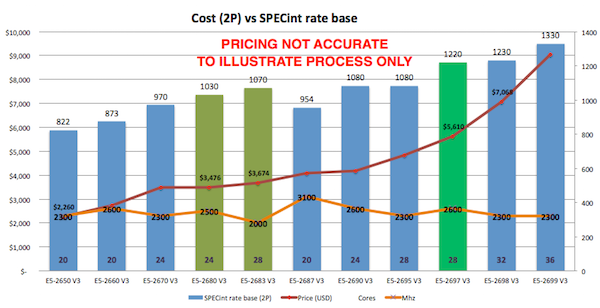
Based on the data in the chart and experience at customers sites the E5-2680 V3 processor shows good performance and a good price point per SPECint or per core.
Other factors come into play as well, for example if you are looking at server processors for virtualized deployment it may be cheaper to increase the core count per processor at increased cost but with the effect of lowering the total number of host servers required to support all your VMs, therefore saving on software (e.g. VMware or Operating Systems) that licence per processor socket. You will also have to balance number of hosts against your High Availability (HA) requirements. I will revisit VMware and HA in later posts.
For example a VMware HA cluster made up of three 24-core host servers provides good availability and significant processing power (core count) allowing flexible configurations of production and non-production VMs. Remember VMware HA is sized at N+1 servers, so three 24-core servers equates to a total 48-cores available for your VMs.
## Cores vs GHz - Whats best for Caché?
Given a choice between faster CPU cores versus more CPU cores you should consider the following:
- If your application has a lot of cache.exe threads/processes required then more cores will allow more of these to run at exactly the same time.
- If your application has fewer processes you want each to run as fast as possible.
Another way to look at this is that if you have a client/server application with many processes, say one (or more) per concurrent user you want more available cores. For browser based applications using CSP where users are bundled into fewer very busy CSP server processes your application would benefit from potentially fewer but faster cores.
In an ideal world both application types would benefit from many fast cores assuming there is no resource contention when multiple cache.exe processes are running in all those cores simultaneously. As I noted above, but worth repeating, every Caché release has improvements in CPU resource use, so upgrading applications to the latest versions of Caché can really benefit from more available cores.
Another key consideration is maximising cores per host when using virtualization. Individual VMs may not have high core counts but taken together you must strike a balance between number of hosts needed for availability and minimising the number of hosts for management and cost consideration by increasing core counts.
## VMware virtualization and CPU
VMware virtualization works well for Caché when used with current server and storage components. By following the same rules as the physical capacity planning there is no significant performance impact using VMware virtualization on properly configured storage, network and servers. Virtulaization support is much better in later model Intel Xeon processors, specifically you should only consider virtualization on Intel Xeon 5500 (Nehalem) and later — so Intel Xeon 5500, 5600, 7500, E7-series and E5-series.
---
# Example: Hardware refresh - calculating minimum CPU requirements
Putting together the tips and procedures above if we consider our example is a server upgrade of a workload running on Dell PowerEdge R710 with 8-cores (two 4-core Xeon 5570 processors).
By plotting the current CPU utilization on the primary production server at the customer we see that the server is peaking at less than 80% during the busiest part of the day. The run queue is not under pressure. IO and application is also good so there are no bottlenecks artificially surpassing suppressing CPU.
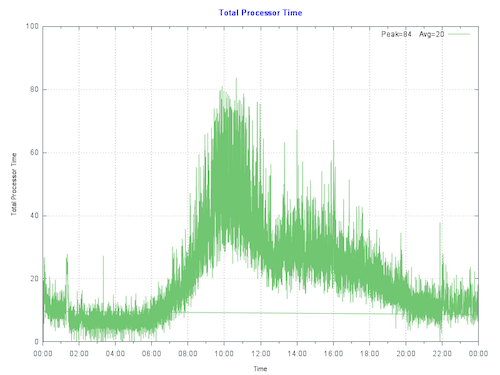
> **Rule of thumb**: Start by sizing systems for maximum 80% CPU utilization at end of hardware life taking into account expected growth (e.g. an increase in users/transactions). This allows for unexpected growth, unusual events or unexpected spikes in activity.
To make calculations clearer I let us assume no growth in throughput is expected over the life of the new hardware:
The per core scaling can be calculated as: (251/8) : (1030/24) or 26% increase in throughput per core.
80% CPU using **8-cores** on the old server equates to roughly 80% CPU using **6-cores** on the new E5-2680 V3 processors. So the same number of transactions could be supported on six cores.
The customer has a few choices, they can purchase new bare-metal servers which meet the minimum CPU requirement of six E5-2680 V3 or equivalent CPU cores, or move forward with their plans to virtualize their production workload on VMware.
Virtulaizing makes sense to take advantage of server consolidation, flexibility and high availability. Because we have worked out the CPU requirements the customer can move forward with confidence to right-size production VMs on VMware. As a sidebar buying current servers with low core counts is either difficult to source or expensive, which makes virtualization an even more attractive option.
Virtualising is also an advantage if significant growth is expected. CPU requirements can be calculated based on growth in the first few years. With constant monitoring a valid strategy is to add additional resources only as needed ahead of requiring them.
---
# CPU and virtualization considerations
As we have seen production Caché systems are sized based on benchmarks and measurements at live customer sites. It is also valid to size VMware virtual CPU (vCPU) requirements from bare-metal monitoring. Virtualization using shared storage adds very little CPU overhead compared to bare-metal**. For production systems use a strategy of initially sizing the system the same as bare-metal CPU cores.
__**Note:__ For VMware VSAN deployments you must add a host level CPU buffer of 10% for VSAN processing.
The following key rules should be considered for virtual CPU allocation:
__Recommendation:__ Do not allocate more vCPUs than safely needed for performance.
- Although large numbers of vCPUs can be allocated to a virtual machine, best practice is to not allocate more vCPUs than are needed as there can be a (usually small) performance overhead for managing unused vCPUs. The key here is to monitor your systems regularly to ensure VMs are right-sized.
__Recommendation:__ Production systems, especially database servers, initially size for 1 physical CPU = 1 virtual CPU.
- Production servers, especially database servers are expected to be highly utalized. If you need six physical cores, size for six virtual cores. Also see the note on hyper threading below.
## Oversubscription
Oversubscription refers to various methods by which more resources than are available on the physical host can be assigned to the virtual servers that are supported by that host. In general, it is possible to consolidate servers by oversubscribing processing, memory and storage resources in virtual machines.
Oversubscription of the host is still possible when running production Caché databases, however for initial sizing of _production_ systems assume is that the vCPU has full core dedication. For example; if you have a 24-core (2x 12-core) E5-2680 V3 server – size for a total of up to 24 vCPU capacity knowing there may be available headroom for consolidation. This configuration assumes hyper-threading is enabled at the host level. Once you have spent time monitoring the application, operating system and VMware performance during peak processing times you can decide if higher consolidation is possible.
If you are mixing non-production VMs a rule of thumb for system sizing to calculate total CPU cores I often use is to _initially_ size non-Production at 2:1 Physical to Virtual CPUs. However this is definitely an area where milage may vary and monitoring will be needed to help you with capacity planning. If you have doubts or no experience you can separate production VMs from non-production VMs at the host level or by using vSphere configuration until workloads are understood.
VMware vRealize Operations and other third-party tools have the facility to monitor systems over time and suggest consolidation or alert that more resources are required for VMs. In a future post I will talk about more tools available for monitoring.
The bottom line is that in our customers example they can be confident that their 6 vCPU production VM will work well, of course assuming other primary food group components such as IO and storage have capacity ;)
## Hyperthreading and capacity planning
A good starting point for sizing VMs based on known rules for physical servers is to calculate physical server CPU requirements for the target per processor with hyper-threading enabled then simply make the translation:
> one physical CPU (includes hyperthreading) = one vCPU (includes hyperthreading).
A common misconception is that hyper-threading somehow doubles vCPU capacity. This is NOT true for physical servers or for logical vCPUs. As a rule of thumb hyperthreading on a bare-metal server may give a 30% additional performance capacity over the same server without hyperthreading. The same 30% rule applies to virtulized servers.
## Licensing and vCPUs
In vSphere you can configure a VM to have a certain number of sockets or cores. For example, if you have a dual-processor VM, it can be configured so it has two CPU sockets, or that it has a single socket with two CPU cores. From an execution standpoint it does not make much of a difference because the hypervisor will ultimately decide whether the VM executes on one or two physical sockets. However, specifying that the dual-CPU VM really has two cores instead of two sockets could make a difference for non-Caché software licenses.
---
# Summary
In this post I outlined how you can compare processors between vendors, servers or models using SPECint benchmark results. Also how to capacity plan and choose processors based on performance and architecture whether virtualized is used or not.
These are deep subjects, and its easy to head of into the weeds…however the same as the other posts, please comment or ask questions if you do want to head off different directions.
—
# EXAMPLE Searching for SPECint_rate2006 results.
#### The following figure shows selecting the SPECint_rate2006 results.
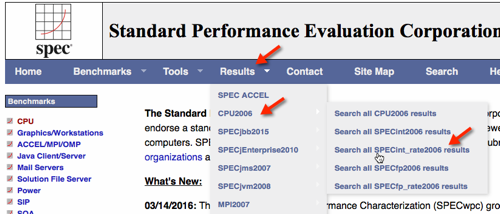
----
#### Use the search screen narrow results.
#### Note that you can also to dump all records to a ~20MB .csv file for local processing, for example with Excel.
#### The results of the search show the Dell R730.
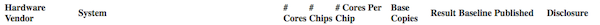

---
#### Selecting HTML to give the full benchmark result.
---
You can see the following results for servers with the processors in our example.
Dell PowerEdge R710 with 2.93 GHz: 8 cores, 2 chips, 4 cores/chip, 2 threads/core
Xeon 5570: __SPECint_rate_base2006 = 251__
PowerEdge R730 (Intel Xeon E5-2680 v3, 2.50 GHz) 24 cores, 2 chips, 12 cores/chip, 2 threads/core
Xeon E5-2680 v3: __SPECint_rate_base2006 = 1030__ I really appreciate all the work you have done on this post.But for me, it is beyond me.Perhaps a more meaningful summary for those who wish to stay out of the weeds? Ok, here is the simpler route:1. if you have performance problems then run pButtons, call WRC, they will get "performance team" involved and explain you what you see :);2. if you have budget for new HW then see item #1 above and ask WRC for advice. Thank you Murray. These are great article series The problem with all such analyses is always the same. They fail to account for the single most important factor for real world applications, and that is memory bandwidth.Code written for benchmarks has the flaw that it is precisely "written for benchmarks". It is no replacement for real life code which accesses memory in ways that such custom code cannot even begin to emulate.Consider virtualization for a moment. Let's take the x86 world. Let's take Intel's VT-x, or AMD's AMD-V. If you look at the wikipedia entry for such techniques, the core goal of those technologies is _not_ to make machine code run faster (this is the "easy part"), but to reduce the time it takes for programs in virtualized environments to access memory.Running code is "easy". Accessing memory is hard... And accessing memory is the key.----For completeness, I'll just add this: I am mostly a Java developer, and I know that the most glaring flaw of Java is its poor locality of reference -- accessing any `X` in a `List<X>` is very likely to trigger a page fault/load/TLB update cycle for this particular `X` to be available. As a result, when performance comes into play, I do not look as much into the frequency of the CPU as I look into the L{1,2,3} cache sizes and the memory bus width and speed. In the long run, the latter three are the deciding factors as far as I'm concerned. Hi Francis,You are absolutely right that memory access performance is vital, however this is not only bandwidth but also latency. With most new systems employing NUMA based architectures, both memory speed and bandwidth have a major impact. This requirement continues to grow as well as because more and more processor cores are crammed into a single socket allowing for more and more concurrently running processes and threads. In additional NUMA node inter-memory accesses plays a major role. I agree that clock speed alone is not a clear indicator of being "the fastest", since clock speeds haven't changed all that much over the years once getting into the 2-3Ghz+ range, but rather items such as overall processor and memory architectures (eg. Intel QPI), on-board instruction sets, memory latency, memory channels and bandwidth, and also on-chip pipeline L2/L3 cache sizes and speeds all play a role.What this article is demonstrating is not particularly CPU sizing specifics for any given application, but rather mentioning one of (not the only) useful tools comparing a given processor to another. We all agree there is no substitute for real-world application benchmarking, and what we have found through benchmarking real-world application based on Caché that SPECint (and SPECint_rate) numbers usually provides a safe relative correlation or comparison from processor model to processor model. Now things become more complicated when applications might not be optimally written and impose unwanted bottlenecks such as excessive database block contentions, lock contention, etc... from the application. Those items tend to negatively impact scalability on the higher end and would prohibit linear or predictable scaling.This article is to serve as the starting point for just one of the components in the "hardware food group". So the real proof or evidence is gained from doing proper benchmarking of your application because that encapsulated all components working together. Kind regards... Thanks for the comments Francis, I think Mark sums up what I was aiming for. The first round of posts is to introduce the major system components that affect performance, and you are right memory has a big role to play along with CPU and IO. There has to be a balance - to keep stretching the analogy good nutrition and peak performance is the result of a balanced diet. Certainly badly sized or configured memory will cause performance problems for any application, and with Java applications this is obviously a big concern. My next post is about capacity planning memory, so hopefully this will be useful - although I will be focusing more on the intersection with Caché. As Mark pointed out NUMA can also have influence performance, but there are strategies to plan for and mitigate the impact of NUMA which I will talk about in my Global Summit presentations, and which I will also cover in this series of posts.Another aim in this series is to help customers who are monitoring their systems to understand what metrics are important and from that use the pointers in these posts to start to unpack whats going on with their application and why - and whether action needs to be taken. The best benchmark is monitoring and analysing your own live systems. Murray, Can you explain how you do these calculations: The per core scaling can be calculated as: (251/8) : (1030/24) or 26% increase in throughput per core.80% CPU using 8-cores on the old server equates to roughly 80% CPU using 6-cores on the new E5-2680 V3 processors. So the same number of transactions could be supported on six cores.I mean what did you do to match the 80% on the old server to 6 -cores in the new one. I got a little bit lost with the numbers or steps you do. Thanks Hi, back of the envelope logic is like this:For the old server you have 8 cores. Assuming the workload does not change:Each core on the new server is capable of about 25% more processing throughput. Or another way; each core of the old server is capable of of about 75% processing throughput of the new server. So roughly (8 *.75) old cores equates to about 6 cores on the new server.You will have to confirm how your application behaves, but if you are using the calculation to work out how much you can consolidate applications on a new virtualized server you can get a good idea what to expect. If it is virtualized you can also right-size after monitoring to fine tune if you have to. For a deeper dive into VMware CPU considerations and planning, please see the post:https://community.intersystems.com/post/virtualizing-large-databases-vmware-cpu-capacity-planning @Murray.Oldfield - thank you for the time you spent putting together these performance articles!