PrivateGPT exploring the Documentation
Considering new business interest in applying Generative-AI to local commercially sensitive private data and information, without exposure to public clouds. Like a match needs the energy of striking to ignite, the Tech lead new "activation energy" challenge is to reveal how investing in GPU hardware could support novel competitive capabilities. The capability can reveal the use-cases that provide new value and savings.
Sharpening this axe begins with a functional protocol for running LLMs on a local laptop.
My local Mac has an M1 processor. In early experiments had found from exploring Falcon models the flow of toolkit was primarily towards using the Cuda graphics card. There are "compressed" versions of models ( Quantized ). However from my current exploration path these could only be loaded into a Cuda GPU which I didn't have. No Bit-and-bytes support for M1 / M2 processors and AutoGPTQ quantization didn't support MPS processor either. Running the unquantized models in CPU was prohibitively slow.
I had spotted PrivateGPT project and the following steps got things running.
# install developer tools xcode-select --install # create python sandbox mkdir PrivateGTP cd privateGTP/ python3 -m venv . # actiavte local context source bin/activate # privateGTP uses poetry for python module management privateGTP> pip install poetry # sync privateGTP project privateGTP> git clone https://github.com/imartinez/privateGPT # enable MPS for model loading and processing privateGTP> CMAKE_ARGS="-DLLAMA_METAL=on" pip install --force-reinstall --no-cache-dir llama-cpp-python privateGTP> cd privateGPT # Import configure python dependencies privateGTP> poetry run python3 scripts/setup # launch web interface to confirm operational on default model privateGTP> python3 -m private_gpt # navigate safari browser to http://localhost:8001/ # To bulk import documentation needed to stop the web interface as vector database not in multi-user mode privateGTP> [control] + "C" # import some PDFs privateGTP> curl "https://docs.intersystems.com/irislatest/csp/docbook/pdfs.zip" -o /tmp/pdfs.zip privateGTP> unzip /tmp/pdfs.zip -d /tmp # took a few hours to process privateGTP> make ingest /tmp/pdfs/pdfs/ # launch web interface again for query documentation privateGTP> python3 -m private_gpt
Experiments with the default model mistral-7B-Instruct
Some things that worked reasonably were looking for more textual content.
1. What is a lock Table?
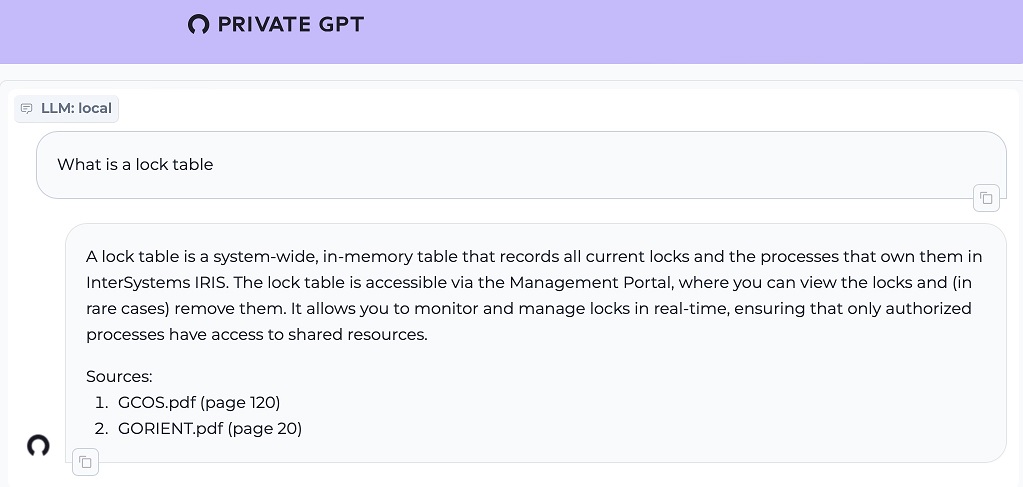
2. Write Object Script "Hello World"
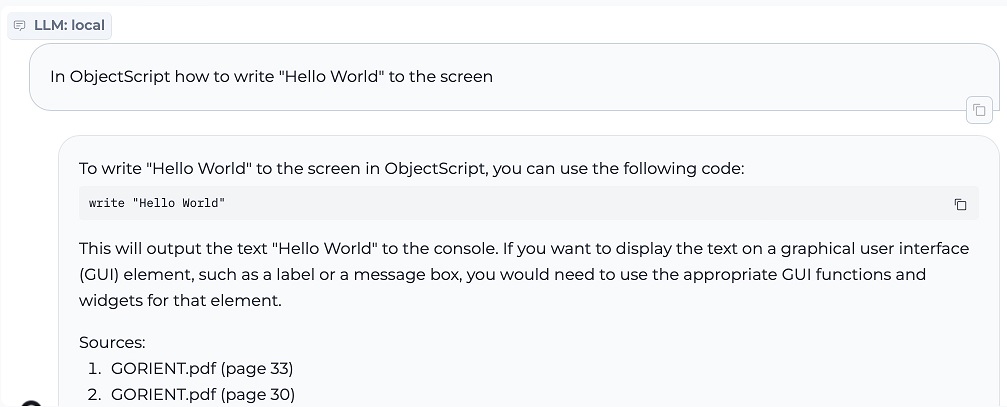
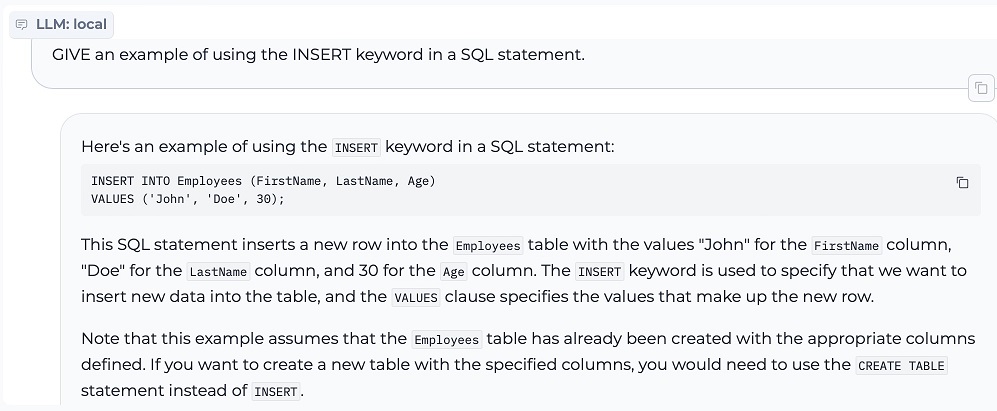
3. INSERT in SQL Statement
The trailing semicolon is a trained habit from training on different implementations of SQL.
Current deployed versions of IRIS would have an issue with the trailing semicolon but this is addressed as discarded rather that being an error in newer version specifically to address this common generative nuance.
4. ObjectScript FOR loop
The challenge here is treating the increment as the max counter. So it creates an endless loop incrementing by "10" instead of a loop that increments by "1" ten times. As a minor point the trailing quit is not necessary to the loop, but is tidy in terms of a well contained line label.

5 . ObjectScript continue
Here the use of documentation is clearly confused the ObjectScript with IRIS BASIC language examples ( THEN keyword ). A query docs approach, possibly needs to use "ObjectScript" as a metadata filter or have upstream generated sets of help PDFs that are limited to a particular language implementation. Anticipating Python and Java examples could impose a similar effect. The use of "i%2" is python syntax for modular operator where as would be expecting "i#2" for object script.

Swapping out models
New models can be added by downloading GGUF format models to the models sub-directory from https://huggingface.co/
Here the naming convention contained "Q"+level to indicate quantization loss versus size. Where lower "Q" is effectively a smaller download model with more quality loss.
settings.yaml
local: llm_hf_repo_id: TheBloke/Mistral-7B-Instruct-v0.1-GGUF llm_hf_model_file: mistral-7b-instruct-v0.1.Q4_K_M.gguf #llm_hf_repo_id: TheBloke/Orca-2-13B-GGUF #llm_hf_model_file: orca-2-13b.Q6_K.gguf #llm_hf_repo_id: TheBloke/XwinCoder-34B-GGUF #llm_hf_model_file: xwincoder-34b.Q6_K.gguf embedding_hf_model_name: BAAI/bge-small-en-v1.5ssss
Using "LLM Chat" mode ( No query documents) with "xwincoder-34b" model, suggests much "code" recommendations can come from the existing trained model.
It demonstrated an interesting learned confusion between Globals and Routines which both are referenced by the carrot ( "^" ) .
The enthusiasm for "%" prefix for method name invocation may be learned invocation patterns from system class documentation instead of learning the feature of method name relates to invoking said method.
There are configuration references with system management that undertake actions in the %SYS namespace and this is generally quite separate from activities of third-party code.
It was interesting to see the invocation as well as implementation example to uncover such disparity ( Invoked as a Routine instead of class method ).
.png)
General Generative capabilities ( Model Orca 13b Q6 )
1. Generating questions and answers from supplied text
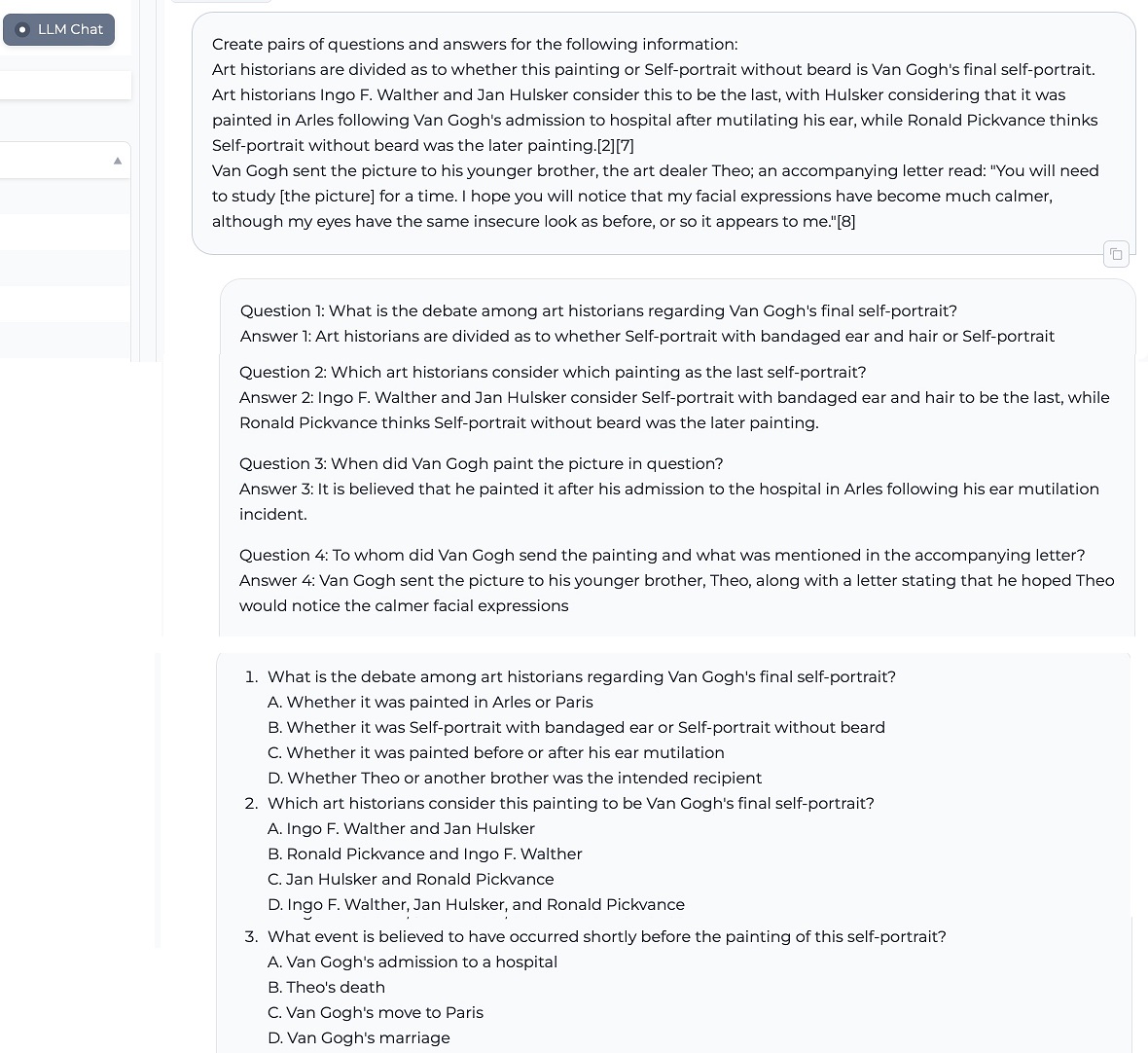
2. Explaining differences of concepts from supplied text

3. Summarizing information into a shorter form
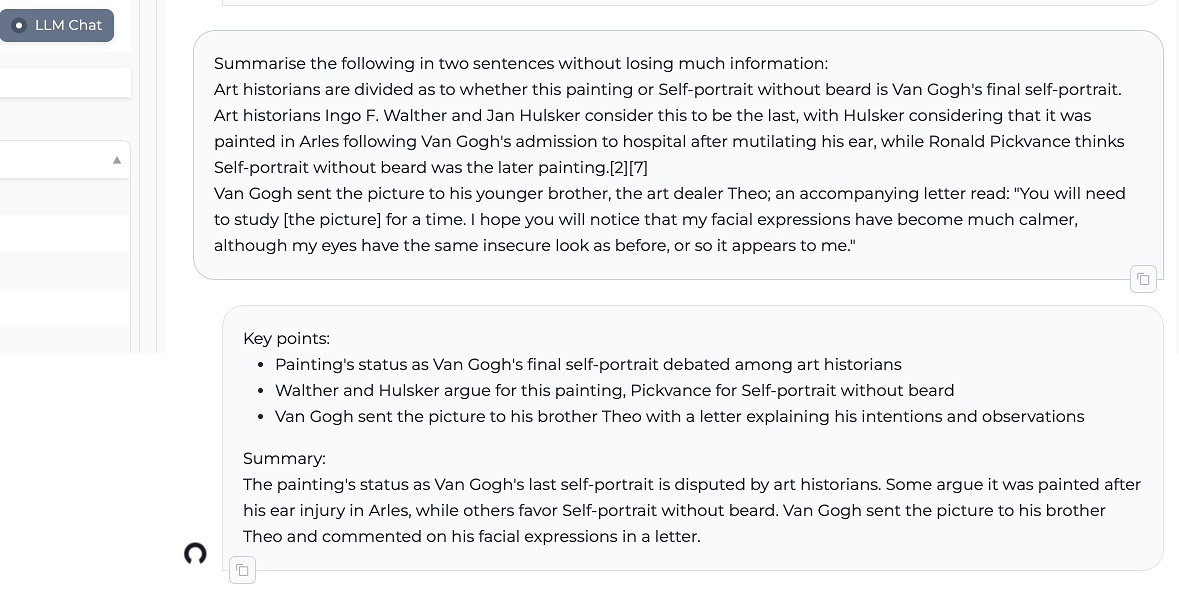
Integrate with IRIS
PrivateGPT can be put to work from IRIS by exercising available JSON end point with surprisingly little code.
The following code snippets demonstrate direct usage from ObjectScript.
This can easily be wrapped by IRIS Integration Operations and Messages to provide a reusable facility with configuration, message trace, etc.,.
IRIS Conversation example
Example output:
.png)
IRIS Retrieve Embedding Example
Example output:
.png)
Further IRIS integration
The web API also supports:
- dynamically loading new source documents
- listing existing source document
- deleting existing source documents
- a health API to indicate availability
Further details available at: https://docs.privategpt.dev/api-reference/api-reference/ingestion
Summary thoughts and ideas
Local inference ( running quantized LLMs on laptop for productivity ) can be a useful way to initially scale the application of existing and internally retrained models. It allows flexibility for business users to privately explore and share new usercases and prompt engineering recipes.
To use PrivateGPT better for documentation, would need to delve deeper to reconfigure generative temperature lower, to reduce the creativity and improve accuracy of answers.
Technical Documentation and user manuals are no longer intended simply for human readers.
Can existing documentation pipelines be easily repurposed with metadata to shape documentation output that is better consumed and repurposed for generative AI?
A single documentation resource for multiple code languages makes it difficult to generalize usefully without conflating code examples. Hence hypothesis is that both documentation "code language" and "source retraining" of models would be better suited in short-term to be mono-code-language resources and assistants.
How well can retraining an existing model "unlearn" existing code conflations to be replaced with the useful and expected code syntax?
Hope this inspires new explorations.
References
Martínez Toro, I., Gallego Vico, D., & Orgaz, P. (2023). PrivateGPT [Computer software]. https://github.com/imartinez/privateGPT
Resources
Comments
@Alex Woodhead - nice work with this :) Thank you for the time you spent writing this up!
Great job.. I was looking for a private GPT to summarize medical records for a client. With this article we can investigate how to implement this functionality without fear of publishing private data in a public cloud.
💡 This article is considered InterSystems Data Platform Best Practice.