Managing UTF-8 characters on the database with a REST application
Hi everyone,
This is:
Cache for UNIX (Red Hat Enterprise Linux for x86-64) 2016.2 (Build 736U) Fri Sep 30 2016 12:25:56 EDT
The server is on RedHat Linux while the browser is running on Windows (Firefox).
I am helping a partner build a complex modern HTML5 web application that talks with Caché using REST calls. They have been using %CSP.REST very successfully. Security works great as well.
Some time ago, I had defined the parameter CONVERTINPUTSTREAM = 1 on their %CSP.REST classes and that seemed to work. Their pages were sending UTF-8 strings and because of this parameter we were storing them on our database as ASCII (I guess). At least, when looking at the global and doing SELECTs on tables I could see the data there.
Here is the description of CONVERTINPUTSTREAM parameter from %CSP.Page (from where %CSP.REST inherits from):
/// Specifies if input %request.Content or %request.MimeData values are converted from their
/// original character set on input. By default (0) we do not modify these and receive them
/// as a binary stream which may need to be converted manually later. If 1 then if there
/// is a 'charset' value in the request Content-Type or mime section we will convert from this
/// charset when the input data is text based. For either json or xml data with no charset
/// this will convert from utf-8 or honor the BOM if one is present.
Parameter CONVERTINPUTSTREAM = 0;
What I didn't realize at the time was that when the same page that submitted the UTF-8 data requested the data back for displaying, we wouldn't re-convert the data back to UTF-8. We would send whatever was in the database and the browser would display it fine, unless there were special characters such as áéíóúçÁÉÍÓÚ etc... Those would be shown on the page as a weird symbol.
When I realized that, I removed the CONVERTINPUTSTREAM from my %CSP.REST page. Now, the data that is being sent as UTF-8 gets stored on the database as UTF-8. When the data is sent back to the application, it is sent also as UTF-8 and the application seems to work fine. But when looking at the global or at the tables, what I see now is something like:
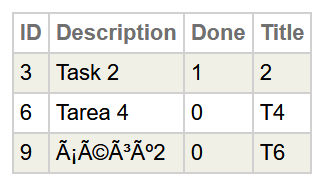
As you can notice, line 9 is unreadable because it uses UTF-8 encoding while the database uses something else (ASCII?). That should read "áéíóú".
So, I am now unable, for instance, to query for descriptions that %STARTSWITH "á". At least not from the Caché Management Portal. I CAN do the search through the Web Application without problems. I can also do the search from the terminal as long as I enter an UTF-8 search string. For instance:
USER>s oRS=##class(%ResultSet).%New()
USER>w oRS.Prepare("select ID from Task where Description %StartsWith ? ")
1
USER>Set tSearchString=$ZConvert("á","O","UTF8")
USER>Write oRS.Execute(tSearchString)
1
USER>Write oRS.Next()
1
USER>Write oRS.GetData(1)
9Conclusion: It should work. But I am not sure if that is the best approach.
I was thinking about go back and set CONVERTINPUTSTREAM back to 1. But then, every time someone wants to send data to the browser, we should convert it with $ZConvert(string,"O","UTF8"). That doesn't look very elegant to me.
So, my question is: Is there another way of making this work more transparently for the developer? The client is using espw locale, that is pretty much the same as enuw except for number separators, currency symbols, date formats and default collation (Spanish 5 instead of Caché Standard). I have also set the following global during the troubleshooting process:
^%SYS("CSP","DefaultFileCharset")="utf-8"Parameter UseSession = 1; Parameter CHARSET = "utf-8"; Parameter CONTENTTYPE = "application/json";
And the CSP page that uses this REST service is starts like this:
<!DOCTYPE html>
<html>
<head>
<CSP:PARAMETER name="SECURITYRESOURCE" value="AUPOL_Task"/>
<CSP:PARAMETER Name="CHARSET" Value="utf-8">
<title>My tasks</title>
<meta charset="utf-8" />
<csp:include page="includes/libraries.csp"/>
</head>
Comments
Hi Amir,
You should convert all incoming data that is not in your native encoding : you don't want data in your database that is coming from ODBC, Web, Files or other to have different encodings !
I use $ZCONVERT( ... , "I", "UTF8") for all incoming data thru rest, and use $ZCONVERT( ... , "O", "UTF8") for all data that is sent via rest. I also use the "u" format flag when i use %WriteJSONFromSQL.
Hi, Lasse!
Thanks for the input.
It's not off topic, but a new good question. Would you please introduce it as a new question regarding security setup in REST and refer to the article?
You can use member mentioning to ping the member you want to participate in discussion.
Thank you in advance!
Sure! I can write about that. It will be good to get some peer review on the choice I have made.
Hi Danny!
That is exactly what I want to avoid...
If you have written simple old style CSP applications, you will remember that CSP infrastructure will do this translation for you. UTF-8 comes in, but you don't notice it because by the time you need to store it on the database, it is already converted into the character encoding used by the database. And when you write that data from the database back to the user to compose a new html page, it is again translated to UTF-8.
I was expecting the same behavior with %CSP.REST.
Why %CSP.REST services go only half way? I mean:
- If I do nothing and leave CONVERTINPUTSTREAM=0, data will come in as utf-8 and I will save it on the database as utf-8. Then, when I need to give back the data to the page, it will present itself ok, since it is utf-8. But the data on the database is not on the right encoding and that will cause different problems. To avoid these problems, I must do what you suggest and use $ZConvert on everything.
- If I set CONVERTINPUTSTREAM=1, data will come in as utf-8 and be translated by %CSP.REST/%CSP.Page infrastructure and I will save it on the database using whatever encoding Caché uses to store Unicode characters on the database. So, I am avoiding doing the $ZConvert my self. It is done automatically. But then, when I need to use that stored data to show a new page, %CSP.REST won’t translate it back to utf-8 and it will be presented as garbage. So I am required to use $ZConvert to do the translation myself what is absurd and inelegant since %CSP.REST has done half of the job for me already.
So, I want to use CONVERTINPUTSTREAM=1 to mimic the typical behavior of CSP pages that you describe and we all love. But it goes only halfway for some reason and I wonder what could I do to fix this right now for my client.
Do you realize that CONVERTINPUTSTREAM is good thing? I am only sorry that we don't have CONVERTOUTPUTSTREAM...
Kind regards,
AS
Hi Evgeny
I see your point in posting it as a seperate question. I'll post the question later today or tomorrow, and I'll give the member mentioning a try.
Ok... I think I have found how to do it.
The problem was that I use a Main dispatcher %CSP.REST class that routes the REST calls to other %CSP.REST classes that I will call the delegates.
I had the CHARSET parameter on the delegates but not on the main router class! I just added it to the main router class and it worked!
So, in summary, to avoid doing $ZConvert everywhere with REST applications, make sure you have both parameters CONVERTINPUTSTREAM=1 and CHARSET="utf-8". It won't hurt having the CHARSET declarations on your CSP and HTML pages as well like:
<!DOCTYPE html>
<html>
<head>
<CSP:PARAMETER Name="CHARSET" Value="utf-8">
<title>My tasks</title>
<meta charset="utf-8" />
</head>Kind regards,
Amir Samary
Hi Amir,
CONVERTINPUTSTREAM looks to be a new parameter in 2016 and I have only just been looking at it myself this morning. The documentation is a little thin so I am just going on observations. Anyone, please correct me if I am getting any of this wrong.
First, my understanding is that Cache is using Unicode internally. If you look at your $ZVERSION you will see a U in the build number which I believe indicates you installed Cache in the default Unicode mode.
Prior to 2016. The %CSP.Content will receive a UTF-8 JSON stream as binary and will consume the raw UTF-8 content without doing any translation on it.
As an example an "á" character will be sent in UTF-8 as hex C3A1. Internally this character should be stored as hex E1. Since there is no conversion the raw binary is stored as C3A1. When this character is written back out to a CSP device it will assume its Unicode and translate it to UTF-8. C3 becomes C383 and A1 becomes C2A1 which looks like á as UTF-8 symbols.
We can do a simple echo test to prove some of this, this is a pre 2016 CSP page...
{
ClassMethod OnPage() As %Status [ ServerOnly = 1 ]
{
set data=%request.Content.Read(32000)
set ^foo=data
write ^foo
Quit $$$OK
}
}
I'm using Postman to send the following JSON string...
And it echos back
And here is a dump of what has been stored in ^foo
0000: 7B 22 74 65 73 74 22 3A 22 48 65 6C 6C 6F 20 C3 {"test":"Hello Ã
0010: A1 C3 A9 C3 AD C3 B3 C3 BA C3 A7 C3 81 C3 89 C3 ¡Ã©ÃóúçÃ.Ã.Ã
0020: 8D C3 93 C3 9A 20 57 6F 72 6C 64 22 7D .Ã.Ã. World"}
As we can see the JSON string was stored exactly as it was sent. The letter á was sent as hex C3A1 and is being stored as C3A1. The dump displays these in Unicode as á and on output to CSP its converted to the UTF-8 equivalents of those symbols.
Let's change the CSP page to convert the inbound UTF-8 string into Unicode...
{
ClassMethod OnPage() As %Status [ ServerOnly = 1 ]
{
set data=%request.Content.Read(32000)
set ^foo=$ZCONVERT(data,"I","UTF8")
write ^foo
Quit $$$OK
}
}
Now when I send
I get back
and in the database I have...
0000: 7B 22 74 65 73 74 22 3A 22 48 65 6C 6C 6F 20 E1 {"test":"Hello á
0010: E9 ED F3 FA E7 C1 C9 CD D3 DA 20 57 6F 72 6C 64 éíóúçÁÉÍÓÚ World
0020: 22 7D "}
We can fix the inbound with $ZCONVERT. Note that we didn't need to fix the outbound, it was just auto converted for us. Danny mentioned needing to convert the outbound so I am guessing there is a scenario where this auto conversion is not happening. Would be interesting to understand that more. I'm guessing we need to be careful to not double convert a string if its being done automatically.
On to 2016.
First a test with CONVERTINPUTSTREAM set to 0
{
Parameter CONVERTINPUTSTREAM = 0;
ClassMethod OnPage() As %Status [ ServerOnly = 1 ]
{
set data=%request.Content.Read(32000)
set ^foo=data
write ^foo
Quit $$$OK
}
}
I post
and get back
which reflects what we have seen before and what you are experiencing.
Now setting CONVERTINPUTSTREAM to 1
{
Parameter CONVERTINPUTSTREAM = 1;
ClassMethod OnPage() As %Status [ ServerOnly = 1 ]
{
set data=%request.Content.Read(32000)
set ^foo=data
write ^foo
Quit $$$OK
}
}
I send
and get back
and the database contains the correctly encoded data...
0000: 7B 22 74 65 73 74 22 3A 22 48 65 6C 6C 6F 20 E1 {"test":"Hello á
0010: E9 ED F3 FA E7 C1 C9 CD D3 DA 20 57 6F 72 6C 64 éíóúçÁÉÍÓÚ World
0020: 22 7D "}
So it looks like setting CONVERTINPUTSTREAM to 1 negates needing to $ZCONVERT the inbound stream.
Except this doesn't seem to be happing for you.
I decided to try some more tests from Postman. I removed the sending content type such that it would be sent as raw text. This time I send
and I get back
and the database contains
0000: 7B 22 74 65 73 74 22 3A 22 48 65 6C 6C 6F 20 C3 {"test":"Hello Ã
0010: A1 C3 A9 C3 AD C3 B3 C3 BA C3 A7 C3 81 C3 89 C3 ¡Ã©ÃóúçÃ.Ã.Ã
0020: 8D C3 93 C3 9A 20 57 6F 72 6C 64 22 7D .Ã.Ã. World"}
So my observations are that setting CONVERTINPUTSTREAM to 1 requires the request to include some kind of clue as to the contents encoding. This would make sense as we could be sending raw binary to one method and UTF-8 to another.
So, in order to fix your problem you might want to look at your JavaScript code that sends the data.
This is what I normally do in pure JavaScript...
request.setRequestHeader('Content-Type', 'application/json; charset=utf-8');
or JQuery...
contentType: 'application/json; charset=utf-8',
});
Would be nice to see some more documentation on CONVERTINPUTSTREAM so that we can be sure of this behaviour. I tried looking at its implementation but its hidden from view.
Hope that helps a bit.
Sean.
Hi Sean!
Thank you for your analysis. But try doing it with a %CSP.REST service instead of a %CSP.Page. %CSP.REST overrides the Page() method with a completely new one. The behavior is different because it is on the Page() method that the IO translation table is set up.
It looks like my problem was related to the fact that I didn't have the CHARSET parameter declared on my main %CSP.REST dispatcher. I only had it on the %CSP.REST delegates. When I put it on the main dispatcher, it worked perfectly.
But you may be onto something... I would rather specify the charset the way you do (on the javascript call) because I may want to use the same %CSP.REST dispatcher to receive a binary file or something other than UTF-8. That is an excellent point. Thank you very much for this tip. I will do what you said and try to remove the CHARSET parameter from both my main %CSP.REST dispatcher and delegates and see what happens. I will let you know!
Kind regards,
Amir Samary
Hi Amir,
It's the same for both %CSP.Page and %CSP.REST.
Whilst the %CSP.REST does override the page method, this does not seem to affect the CONVERTINPUTSTREAM parameter.
Looking at the code I suspect that the %request.Content stream is created deeper into the CSP gateway.
I tested to be sure...
{
Parameter CONVERTINPUTSTREAM = 1;
XData UrlMap
{
<Routes>
<Route Url="/echo" Method="POST" Call="Echo" Cors="false" />
</Routes>
}
ClassMethod Echo()
{
set data=%request.Content.Read(32000)
set ^foo2=data
write ^foo2
Quit $$$OK
}
}
With CONVERTINPUTSTREAM set to 1 I sent
and it returned
and the storage looks fine as well
0000: 7B 22 74 65 73 74 22 3A 22 48 65 6C 6C 6F 20 E1 {"test":"Hello á
0010: E9 ED F3 FA E7 C1 C9 CD D3 DA 20 57 6F 72 6C 64 éíóúçÁÉÍÓÚ World
0020: 22 5D 7D "]}
As before, if I fail to set the content type in my JavaScript request object then the conversion does not happen.
Sean.
Hi Amir
This is a bit off topic, but is there any chance you can provide a few pointers on how your client setup security for their %CSP.REST API? I am currently looking into this topic, and I am hoping to learn from some real-world examples.
Best regards,
Lasse
Hi Sean!
Can you please, tell me what is the exact $ZV of the instance you used to do your tests?
Kind regards,
AS