How the Ensemble Scheduler Works
The Ensemble Scheduler is used for automatically turning on and off business hosts at certain dates and times. You could use it if, for example, you wanted to only run a business host from 9am to 5pm every day. Conversely, if you want do to trigger an event to occurr at a specific time, for example, a job running at 1am to batch up and send off all the previous day's transactions in one file, we recommend other methods such as the Task Manager.
This article explains how the Ensemble Scheduler works. The screenshots below are from a test production with 2 scheduled components created to demonstrate how the Ensemble Scheduler can be used to manage the production’s processes over time. Here’s the Production Configuration showing two items: HL7 TCP Service and FTP Passthrough Operation.

Look at the Schedule by clicking on the little magnifying glass to the right of the schedule setting:
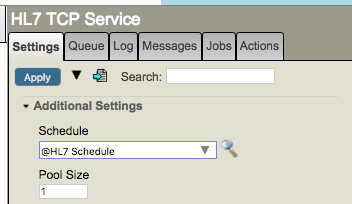
You can see that the HL7 TCP Service is scheduled to start at 9am and stop at 5pm:
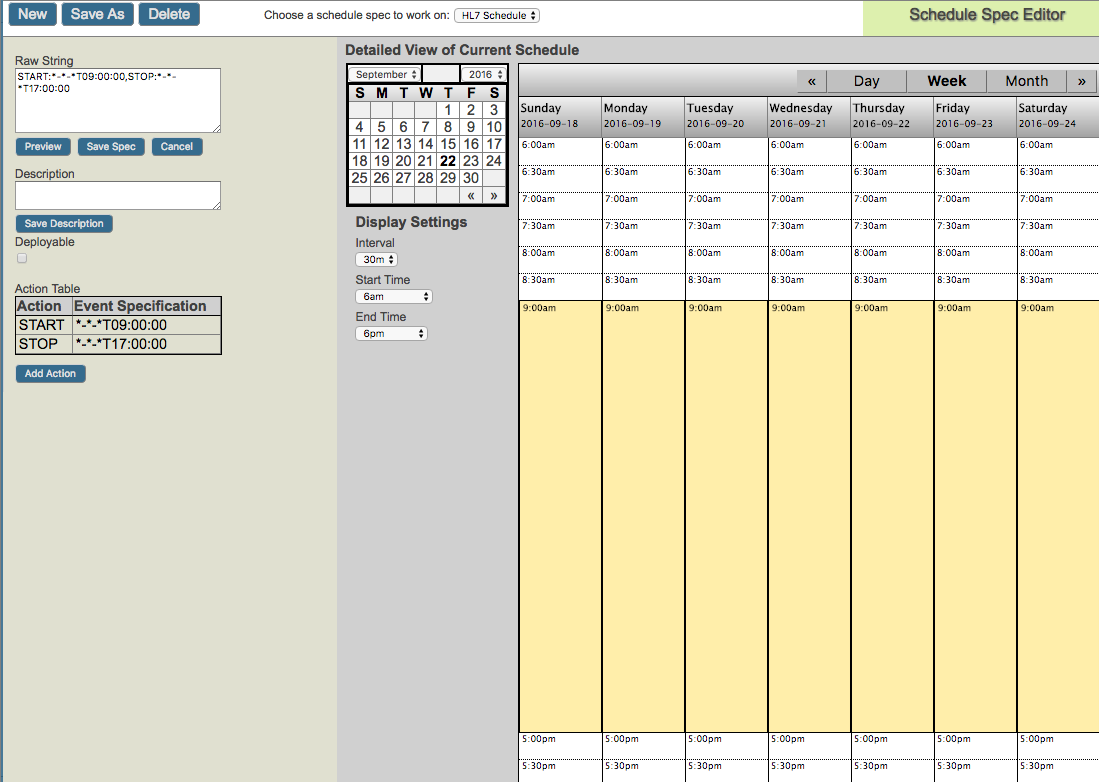
Likewise, if we look at the schedule for the FTP Passthrough Operation, we will see that it is also scheduled to start at 9am, but it stops at 3pm:
The Ensemble scheduler starting and stopping a component is not the same as enabling or disabling the component. The Ensemble scheduler only starts and stops one or more operating system process (depending on Pool Size) for that component - it does not enable and disable the component. A component must be enabled for it to run according to its schedule. A disabled component will never run, regardless of its schedule.
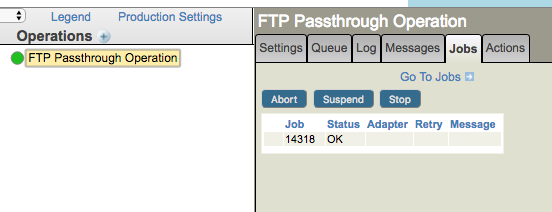
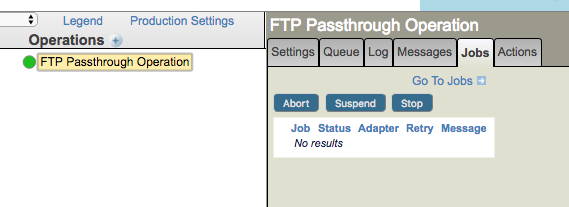
To see if a scheduled component is started, select the component on the production configuration page and select the Jobs tab. If the process is started you will see a table showing its operating system process ID(s) in the Jobs panel on the right. Here, the Pool Size for the FTP Operation is 1, so there is only one process ID listed (14318 in the below example). If Pool Size were larger, you’d see that many processes listed:
Note that the green color of the component shows whether it’s enabled or disabled, but doesn’t indicate whether it started. If the FTP Passthrough Operation was stopped by the Ensemble scheduler (for example, just after 3pm), you’d still see the Operation showing a green circle, but there would be no processes listed under the Jobs tab:
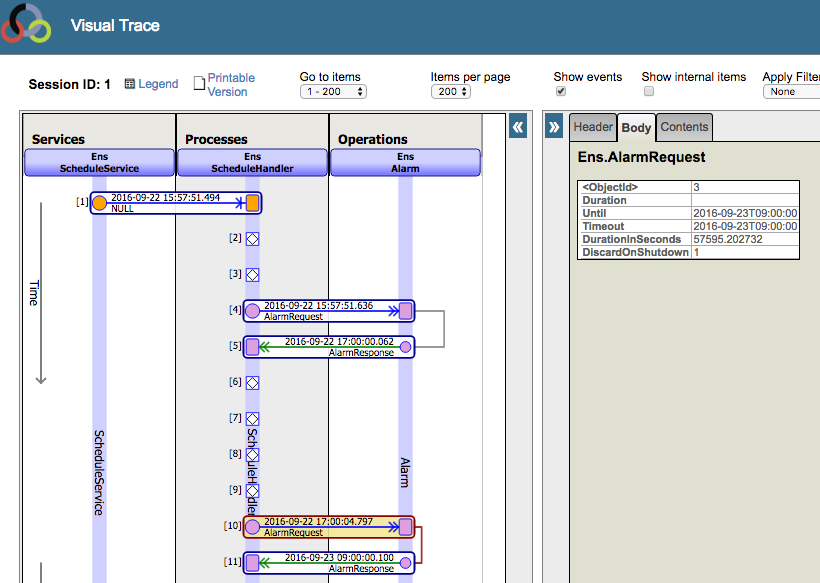
To see how the Ensemble scheduler works “under the hood”, look at the Message Viewer and you’ll see a session that starts with Ens.ScheduleService. It sends a message to Ens.ScheduleHandler and from that point on, messages between Ens.ScheduleHandler and Ens.Alarm and back again. This back-and-forth keeps going for as long as the production is running.
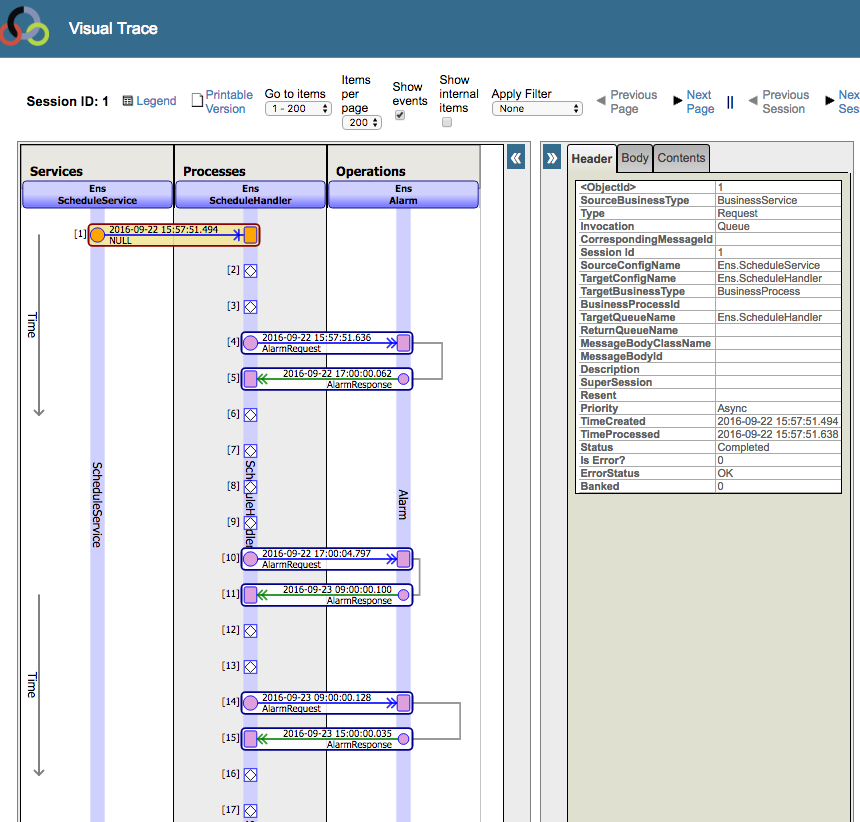
This message exchange is the mechanism behind the Ensemble Scheduler.
- When the session starts, Ens.ScheduleService sends Ens.ScheduleHandler a message.
- Ens.ScheduleHandler calls ##class(Ens.Director).UpdateProduction().
- UpdateProduction looks at the state of the production and the schedule.
- If the schedule says that a component is supposed to be stopped (not running) at that time, it kills the process(es) that component is running.
- If the schedule says that a component is supposed to be started (running), it starts the appropriate number of processes (as specified by Pool Size).
- After UpdateProduction() completes, all the components should have the correct number of processes running (according to the schedule). Ens.ScheduleHandler has completed starting and stopping processes
After the call to UpdateProduction(), Ens.ScheduleHandler determines the next time it needs to run. The scheduler:
- Collects the list of scheduled START and STOP times and
- Finds the next scheduled transition time (whether it be a START or a STOP).
- Sends a message to Ens.Alarm
- Waits for a response
In the above example, Ens.ScheduleHandler collected these times:
9:00 am : HL7 TCP Service START
9:00 am : FTP Passthrough Operation START
3:00 pm : FTP Passthrough Operation STOP
5:00 pm : HL7 TCP Service STOP
If you look carefully at the Visual Trace above you can see the timestamp that shows when Ens.ScheduleHandler was running: 15:57:51, a.k.a. 3:57pm. At that time, the next scheduled time is 5pm, so it sends a message to Ens.Alarm which essentially says “Wake me back up at 5pm”:
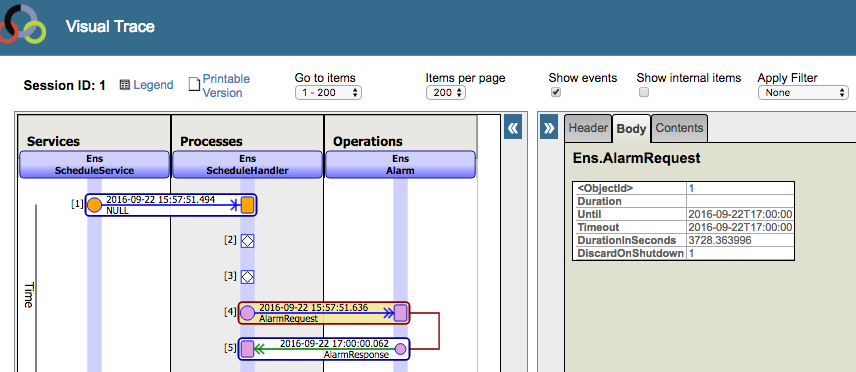
Ens.Alarm waits until 5pm and then sends its response. Above the “Alarm Response” you can see the timestamp: 17:00:00 which is the time Ens.Alarm responded. This response message triggers Ens.ScheduleHandler to call UpdateProduction() and the process starts over. It starts and stops the appropriate processes. In this case, since it’s 5pm, the HL7 TCP Service is scheduled to be stopped.
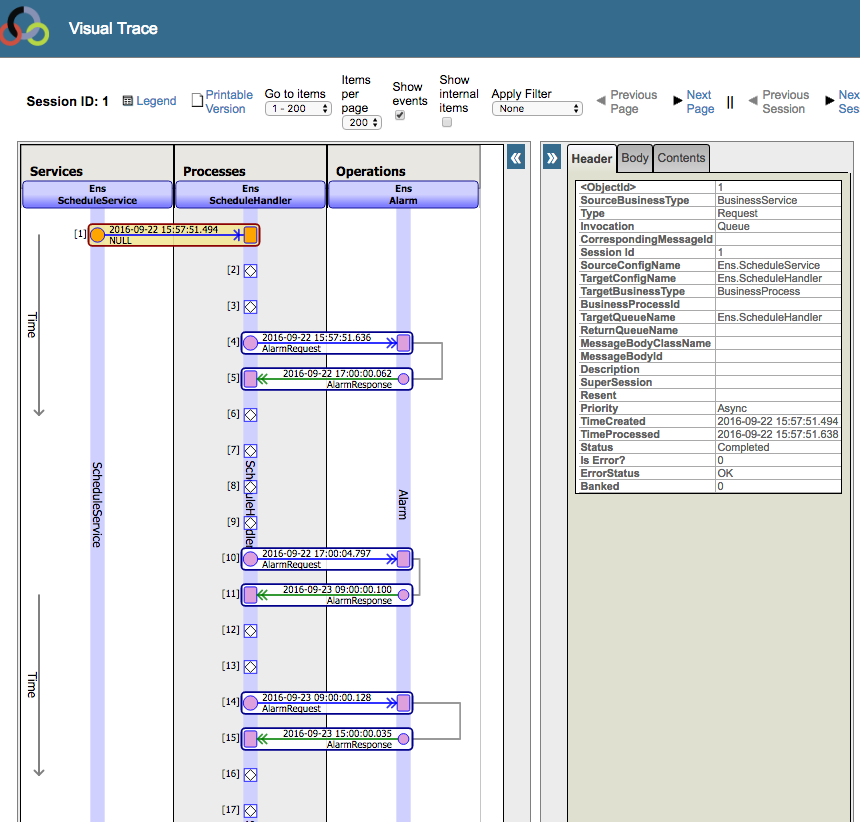
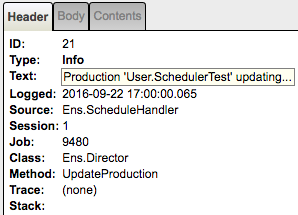
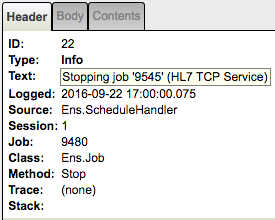
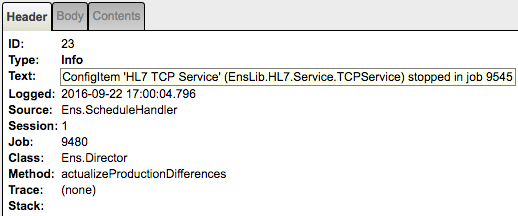
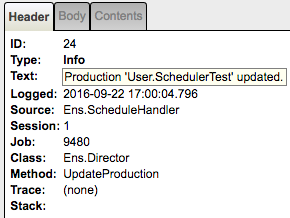
If you click the Trace items marked by the white diamonds labeled [6], [7], [8] and [9] you’d see in the right panel:
[6] Production 'User.SchedulerTest' updating...
[7] Stopping job '9545' (HL7 TCP Service)
[8] ConfigItem 'HL7 TCP Service' (EnsLib.HL7.Service.TCPService) stopped in job 9545
[9] Production 'User.SchedulerTest' updated.
If there were more processes to stop, you’d see a pair of white trace diamonds similar to [7] and [8] for every process the scheduler stops.
Next, Ens.ScheduleHandler looks at the scheduled START and STOP times and determines that 9:00am is the next time it needs to take action, so it sends a message to Ens.Alarm requesting it wake Ens.ScheduleHandler up at 9:00am.
The sequence of steps below, where it starts processes instead of stopping them, is largely the same as above, with the exception of a few missing trace elements as described below.
Ens.Alarm waits until 9:00am and then sends back a response. Ens.ScheduleHandler sees that it’s after 9:00am and that it needs to start both the HL7 TCP Service and the FTP Passthrough Operation. The Visual Trace doesn’t show Trace elements showing that the components are being started because the components themselves do the logging as opposed to Ens.ScheduleHandler, but you can see it in the Event Log:

The messages continue to pass back and forth between the Ens.ScheduleHandler and the Ens.Alarm until the production stops (or until someone removes the schedules).
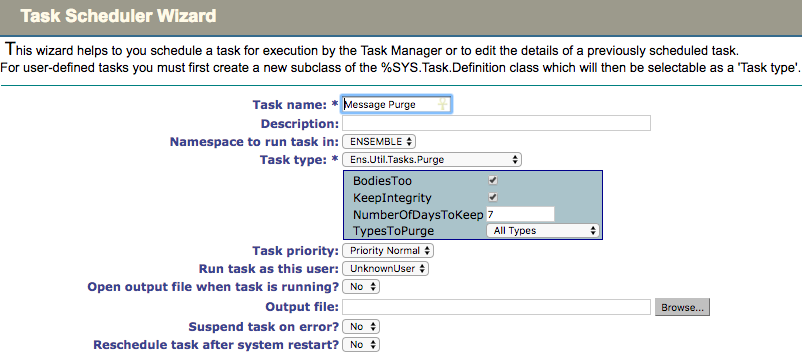
Since the scheduler uses Ensemble messages, you must configure the purge task so that it does not purge the scheduler message. The safest way to avoid accidentally purging scheduler messages is to always select the Keep Integrity option in the Ens.Util.Tasks.Purge task (see screenshot below). Keep Integrity specifies that the task should only purge messages that are “complete". Since the scheduler session is never complete, it should not be purged, but setting “Keep Integrity” to false will override this safeguard. For more information on the “Keep Integrity” setting, see https://community.intersystems.com/post/why-keepintegrity-important-when-purging-healthshareensemble-data
If you have any questions or problems with the scheduler, please call the WRC at 617-621-0700 or email us at support@intersystems.com
Comments
Michael - thanks for the article. It would be really helpful if you could add a paragraph at the top explaining what the Ensemble scheduler is and what it's main use-cases are so that people can tell quickly whether or not this is something which they would want to learn more about. Perhaps as an Intro?
I added a bit of intro, thanks. Let me know if you think I should add more.
Can we assign multiple schedule configurations to a single Operation or Service?
Example
Schedule 1 is for general maintenance 3rd Tuesday Monthly from 7pm to 11PM -- I want to use this schedule configuration for a group of similar connects to target a whole system with multiple connections, not specific to an individual connection.
Schedule 2 is for general operations that might be different depending on the individual connector (M-F) from 9-10PM - this schedule configuration would be specific to the particular connect not the system as a whole.
Connection (Operation) A - will use both Schedule 1 and Schedule 2, so we can reuse Schedule 2 on similar connections configurations for the same system.
Connection (Service) B - will only use Schedule 2, to allow the service to always listen and restart only when a monthly maintenance event occurs.
Okay, when reviewing the information here, and at the link https://community.intersystems.com/post/why-keepintegrity-important-when-purging-healthshareensemble-data there appears to be a conflict.
If the message session is persistent while the production runs, in theory if you do not modify any of the schedules, nor do you recycle the production before a purge of 30 days is kicked off (when you might have "Keep Integrity" off?) the same thing occurs. Your schedule stops running.
I would recommend that the core purge code be updated so that one of the first things it does is modify the created date/time of any current "in flight" scheduler message be the current date/time before the purge does its thing. This would prevent a standard purge from killing the scheduler. Just a thought.
Edit: This apparently was recognized as an issue and is corrected in 2017.1 releases of HealthShare and Ensemble.
This is helpful to see how the scheduler is working. I foudn this because I was having issues with my scheduler.
However, it does not address this cryptic statemet in the documentation for version 2019:
"There are some limitations to scheduling abilities. For example, if a business host is started by the scheduler but cannot be stopped by the scheduler, this is because the business host is in the middle of a synchronous call. The business host must wait for a response to the call before it can be stopped."
Essentially, the scheduler is useful only for known downtimes. If any job can't be stopped within a timeout period (10 seconds) of the Ens.AlarmResponse -- say it's reading a large file -- then the AlarmResponse is missed, and the ScheduleService doesn't try again. The job stays alive, and the next file/message is processed, even after the STOP time. It's like an alarm clock with no snooze button, that is shut off by your roommate after 10 seconds. Who then leaves.
The documentation also says "Use of the schedule setting is not intended or designed as an event signaling device (ok, so it's not a trigger). It is intended to accommodate planned outages and scheduled intervals of activity or inactivity." But if you're not alreay inactive, then it won't successfully schedule the inactivity. If you're not in the room when the alarm sounds, it won't successfully schedule the activity.
I'd like to see it keep trying until it hears back from all hosts that use a schedule, or have some parameters that can be set to check every n seconds for a response, try m times, until a certain time; perhaps per business host.