Help me understand this encoding behavior when exporting XML
Hello.
I'm trying to export a XML stream containing some files that are supposed to have been written using UTF-8, but I'm facing some broken encoding issues.
You can see below that I'm indeed viewing a UTF-8 encoded and which is inside the CSP folder and encoded correctly (although displaying it on Studio would not display it correctly as the file is not using BOM and that's intentional).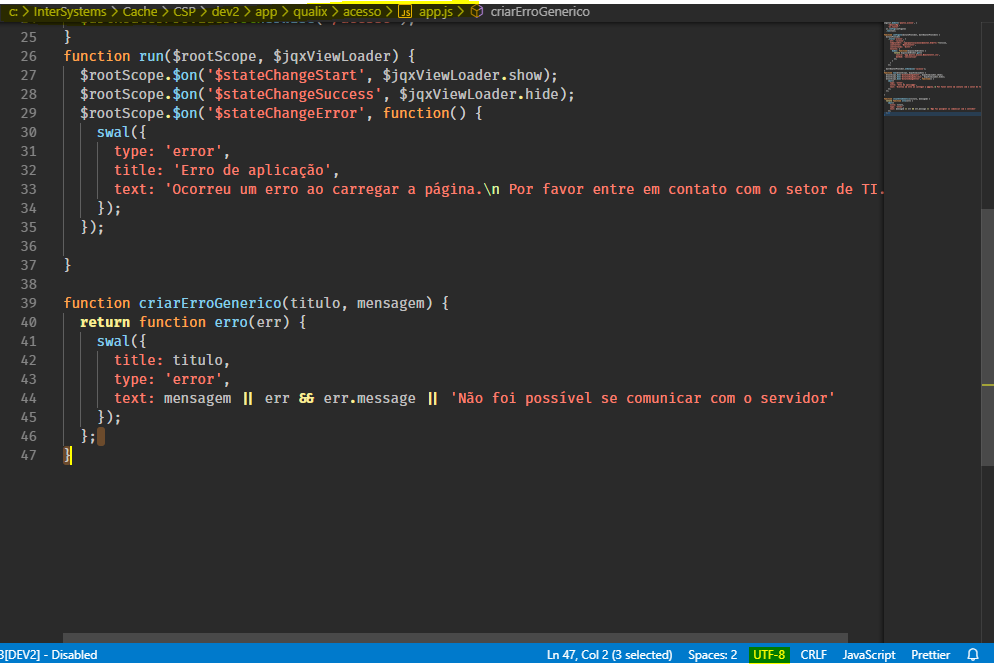
We need to export such files to XML along with many others and for that we'are using the method ExportToStream from the class %SYSTEM.OBJ.
The file must be transmitted using HTTP and that's why we're using ExportToStream.
Now back to the issue...
When exporting to XML a file that is clearly UTF-8 encoded and providing the parameter charset like below:
do $System.OBJ.ExportToStream(.i, .stream, .err,,"utf-8")
We expected the result to be a generated file that respects the original file encoding. But instead, this is what we got:
function run($rootScope, $jqxViewLoader) {
$rootScope.$on('$stateChangeStart', $jqxViewLoader.show);
$rootScope.$on('$stateChangeSuccess', $jqxViewLoader.hide);
$rootScope.$on('$stateChangeError', function() {
swal({
type: 'error',
title: 'Erro de aplicação',
text: 'Ocorreu um erro ao carregar a página.\n Por favor entre em contato com o setor de TI.'
});
});
}
function criarErroGenerico(titulo, mensagem) {
return function erro(err) {
swal({
title: titulo,
type: 'error',
text: mensagem || err && err.message || 'Não foi possÃvel se comunicar com o servidor'
});
};
}]]></CSP>
</Export>
When we noticed that, we started debugging the method to find out that if we actually use "latin1", which is ISO-8859-1 it works fine, no broken charset at all. We did the following test to confirm it:
set i("qualix/rconnect/app/qualix/acesso/app.js")=""
w $System.OBJ.ExportToStream(.i, .stream, .err,,"latin1")
set fs = ##class(%Stream.FileCharacter).%New()
do fs.LinkToFile("C:\temp\aaa.xml")
do fs.CopyFrom(stream)
do fs.%Save()
Now what is actually happening here? We can't take this issue as a solution, because since we don't understood what is happening under-the-hood, it looks error-prone.
I forgot to add:
We're using Cache for Windows (x86-64) 2018.1.2.
And the NLS is configured as ptbw, which is Unicode.
Comments
It looks to me somehow like double encoded.
Does your installation run as 8bit national (iso latin1) set or as wide char. unicode PTUW ?
Mgmt Portal "About" tells you .png)
NLS Locale: PTBW.
So Unicode PTBW.
So Caché normally should be ok.
Have you tried to read the HEX codes stored. (eg. by http://www.pspad.com/ )
I had the experience that especially with Windows some well-written files
looked bad by false (back)translation in some cases.
(Notepad is one of the ugly beasts to stick with 8 bit chars.)
Reading from Caché with "utf8" set should do it as well.
To read the hex I think the zzdump command should suffice?
We're not using Notepad, but Visual Studio Code and Notepad++ because both support changing the current encoding to test the results.
What do you mean by reading from Caché with utf8? If I understood well, we also did the test with "utf-8" being provided instead of "latin1", but when passing utf-8 it broke our encoding, which is weird, because we expected this to happen with "latin1" instead.
in Caché Terminal you may
OPEN file:(:("RS":/IOTABLE="UTF8"):0 if $t write "file open ok",!
use file read line
Zw line
ZZDUMP line
;;; see I/O device guide for more details
The name of the io table is really just UTF8 with no hyphen !
So you force translation to internal format.
Sorry for taking so long to reply, here's the result from one line:
DEV2>Zw line
line=$c(9,9,9)_"title: 'Erro de aplicação',"
DEV2>zzdump line
0000: 09 09 09 74 69 74 6C 65 3A 20 27 45 72 72 6F 20 ...title: 'Erro
0010: 64 65 20 61 70 6C 69 63 61 C3 A7 C3 A3 6F 27 2C de aplicação'
Just so you know, my Caché terminal is configured to output using UTF-8 already.