Global archiver - Moving a part of a global.
Hi Community,
This article describes the small ZPM module global-archiver.
The goal is to move a part of a global from a database to another database.
Why this package?
A typical use case is read-only data sequentially added to your database that you can never delete.
For example:
- User log access to patient medical data.
- Medical documents versioning.
Depending on the intensive usage of your application, these data could highly increase your database size.
To reduce the backup time, it could be interesting to move these data to a database dedicated to the archive and make a backup of this database only after an archive process.
How It Works?
global-archiver copy a global using the Merge command and the global database level reference.
The process needs only the global name, the last identifier, and the archive database name.
Archive database could be a remote database, the syntax ^["/db/dir/","server"]GlobalName is also supported.
After the copy, a global mapping is automatically set up with the related subscript.
See the copy method here
Let's do a simple test
ZPM Installation
zpm "install global-archiver"
Generate sample data:
Do ##class(lscalese.globalarchiver.sample.DataLog).GenerateData(10000)
Now we copy the data with a DateTime older than 30 days:
Set lastId = ##class(lscalese.globalarchiver.sample.DataLog).GetLastId(30)
Set Global = $Name(^lscalese.globalarcCA13.DataLogD)
Set sc = ##class(lscalese.globalarchiver.Copier).Copy(Global, lastId, "ARCHIVE")
Our data are copied, and we can delete archived data from the source database.
On a live system, it's strongly recommended to have a backup before cleaning.
Set sc = ##class(lscalese.globalarchiver.Cleaner).DeleteArchivedData(Global,"ARCHIVE")
Now, open the global mapping page on the management portal. You should see a mapping with a subscript for the global lscalese.globalarcCA13.DataLogD.
You can see the data using the global explorer in the management portal, select database instead of a namespace, and show the global lscalese.globalarcCA13.DataLogD in database USER and ARCHIVE.
Great, the data are moved and the benefits of global mapping avoid any changes to your application code.
Advanced usage - Mirroring and ECP
The previous test was very simple. In the real world, most often we work with the mirroring for the high availability and of course, global mapping could be a problem.
When we perform an archive process, global mapping is only set up on the primary instance.
To solve this problem a method helper NotifyBecomePrimary is available and must be called by the ZMIRROR routine.
ZMIRROR documentation link .
A sample that allows starting a containers architecture with failover members is available on this github page.
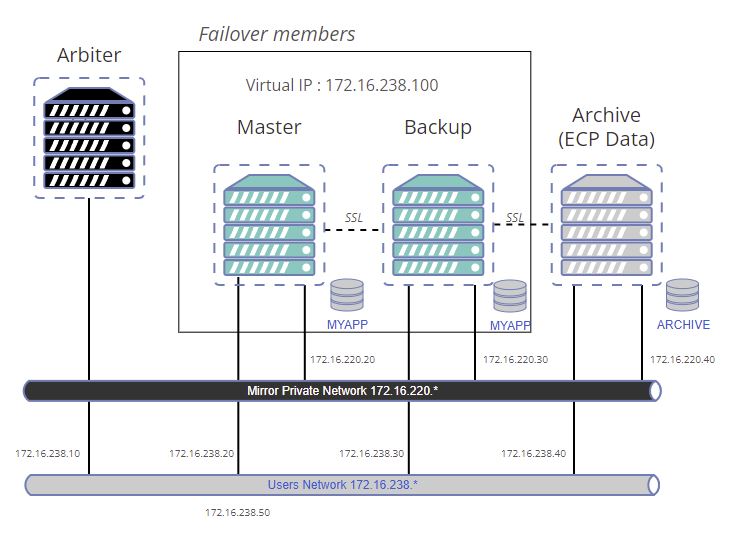
This sample is also a way to test copy to a remote database, you can see on the schema, our archive database will be a remote database (using ECP).
git clone https://github.com/lscalese/global-archiver-sample.git
cd global-archiver-sample
Copy your "iris.key" in this directory
This sample uses a local directory as a volume to share the database file IRIS.DAT between containers. We need to set security settings to ./backup directory.
sudo chgrp irisowner ./backup
If the irisowner group and user do not exist yet on your system, create them.
sudo useradd --uid 51773 --user-group irisowner
sudo groupmod --gid 51773 irisowner
Login to Intersystems Containers Registry
Our docker-compose.yml uses references to containers.intersystems.com.
So you need to login into Intersystems Containers Registry to pull the used images.
If you don't remember your password for the docker login to ICR, open this page https://login.intersystems.com/login/SSO.UI.User.ApplicationTokens.cls and you can retrieve your docker token.
docker login -u="YourWRCLogin" -p="YourPassWord" containers.intersystems.com
Generate certificates
Mirroring and ECP communications are secured by tls\ssl, we need to generate certificates for each node.
Simply use the provided script:
# sudo is required due to usage of chown, chgrp, and chmod commands in this script.
sudo ./gen-certificates.sh
Build and run containers
#use sudo to avoid permission issue
sudo docker-compose build --no-cache
docker-compose up
Just wait a moment, there is a post-start script executed on each node (it takes a while).
Test
Open an IRIS terminal on the primary node:
docker exec -it mirror-demo-master irissession iris
Generate data:
Do ##class(lscalese.globalarchiver.sample.DataLog).GenerateData(10000)
If you have an error "class does exist", don't worry maybe the post-start script has not installed global-archiver yet, just wait a bit and retry.
Copy data older than 30 days to the ARCHIVE database:
Set lastId = ##class(lscalese.globalarchiver.sample.DataLog).GetLastId(30)
Set Global = $Name(^lscalese.globalarcCA13.DataLogD)
Set sc = ##class(lscalese.globalarchiver.Copier).Copy(Global, lastId, "ARCHIVE")
Delete archived data from the source database:
Set sc = ##class(lscalese.globalarchiver.Cleaner).DeleteArchivedData(Global,"ARCHIVE")
Check the global mapping
Great, now open the management portal on the current primary node and check global mapping for the namespace USER and
compare with global mapping on the backup node.
You should notice that the global mapping related to archived data is missing on the backup node.
Perform a stop of the current primary to force the mirror-demo-backup node to become the primary.
docker stop mirror-demo-master
When the mirror-demo-backup changes to status primary, the ZMIRROR routine is performed and the global mapping for the archived data is automatically set up.
Check data access
Simply execute the following SQL query :
SELECT
ID, AccessToPatientId, DateTime, Username
FROM lscalese_globalarchiver_sample.DataLog
Verify the Number of records, It must be 10 000 :
SELECT
count(*)
FROM lscalese_globalarchiver_sample.DataLog
Link - Access to portals
Master: http://localhost:81/csp/sys/utilhome.csp
Failover backup member: http://localhost:82/csp/sys/utilhome.csp
ARCHIVE ECP Data server: http://localhost:83/csp/sys/utilhome.csp
Comments
To reduce the backup time, it could be interesting to move these data to a database dedicated to the archive and make a backup of this database only after an archive process
...
Copy data older than 30 days to the ARCHIVE database
Hi Lorenzo,
We had the similar problem with our largest customer's site which summary database size overgrew 2 TB those days (now the have more than 5 TB). Our solution was more complex than yours as the data move process lasted several days, so we can't stop users for such a long time. We placed a reference to the new storage of (already moved) document data instead the document itself. After the data move was finished, namespace mapping was changed. References were left in the original DB because they took much less space than the original documents.
This rather sophisticated approach allowed us to move the document data without stopping the users' activity. And what was the total win? Should the document data be backup'd? Yes. Should it be journalled / mirrored? Definitely yes. The only advantage achieved with this data separation was no more or less than the ability to deploy testing and/or learning environments without the document database. That's all.
Hi @Alexey Maslov,
Interesting, we have the same problem and apply the same solution :-) !
There is more than 10 years ago, I have written an archiving tool to move document stream to a share and just keep the file reference. The process is long, but there is no downtime. It's exactly the same situation.
The archive tool is included in our application administration panel and the customer can decide himself to archive.
Today, I have read-only globals nodes (not documents) that became very bigger. So, I try an approach with an "archive" database to reduce the volume of our main database(s).
If you are interested in global moving without downtime there is (live-global-mover)[https://openexchange.intersystems.com/package/isc-live-global-mover], but it's not designed for mirroring and ECP.
If you are interested in global moving without downtime there is (live-global-mover)
Thank you, already not as new deployments of our HIS use separate document storage from the very beginning.
Your solution is beautiful as it allows placing the ECP enabled "moved data" server to some less expensive disk storage. In our case that I've briefly described ECP & Mirror were already in use, so we couldn't place document DB on a separated data server as having several independent data servers would be a bad decision for many reasons.
Have you taken a look at DataMove? DataMove supports live environments, ensuring any operations to the global (subscripts) being moved are propagated along to the new location without requiring downtime.
I understand it might not yet be available on the releases you currently have deployed, but would be interested in learning more about features that might be missing or generally experiences from doing this on production systems.
Hi @Benjamin De Boe,
Yes, I recently took a look, but indeed I need it on an old version (2018 )
However, our customers should migrate but I think that i can't use DataMove on production systems before the end of 2023.
In my opinion, DataMove is complete but just needs to be wrapped for special use cases (ex: manage global mapping on mirror switch). It's not a problem, we can do this easily with a simple global and ZSTART routine (such as the sample).
Maybe, I should modify this tool in this way if there is an interest.