 Open Exchange
Open ExchangeThe rise of Big Data projects, real-time self-service analytics, online query services, and social networks, among others, have enabled scenarios for massive and high-performance data queries. In response to this challenge, MPP (massively parallel processing database) technology was created, and it quickly established itself. Among the open-source MPP options, Presto (https://prestodb.io/) is the best-known option. It originated in Facebook and was utilized for data analytics, but later became open-sourced. However, since Teradata has joined the Presto community, it offers support now.
Presto connects to transactional data sources (Oracle, DB2, MySQL, PostgreSQL, MongoDB, and other SQL and NoSQL databases) and delivers distributed and in-memory SQL processing, combined with automatic optimizations of execution plans. Its objective, above all, is to execute fast queries regardless of whether you handle gigabytes or terabytes of data, scaling and parallelizing workloads.
Presto did not originally have a native connector for the IRIS Database, but fortunately, this issue was resolved with an InterSystems community project presto-iris (https://openexchange.intersystems.com/package/presto-iris). That is why we can now expose an MPP layer in front of InterSystems IRIS repositories to enable high-performance queries, reports, and dashboards from transactional data in IRIS.
In this article, we will follow a step-by-step guide on configuring Presto, connecting it to IRIS, and establishing an MPP layer for your customers to employ. We will also demonstrate the main features of Presto, its main commands and tools, always with IRIS as the source database.
Presto Features
Presto contains the following features:
- Simple but extensible architecture.
- Pluggable connectors (Presto supports pluggable connectors to provide metadata and data for queries).
- Pipelined executions (it avoids unnecessary I/O latency overhead).
- User-defined functions (analysts can create custom user-defined functions to migrate easily).
- Vectorized columnar processing.
Benefits of Presto
Below, you can see a list of benefits that Apache Presto offers:
Specialized SQL operations;
Easy installation and debugging;
Simple storage abstraction;
Quickly scalable petabytes of data with low latency.
Presto Architecture
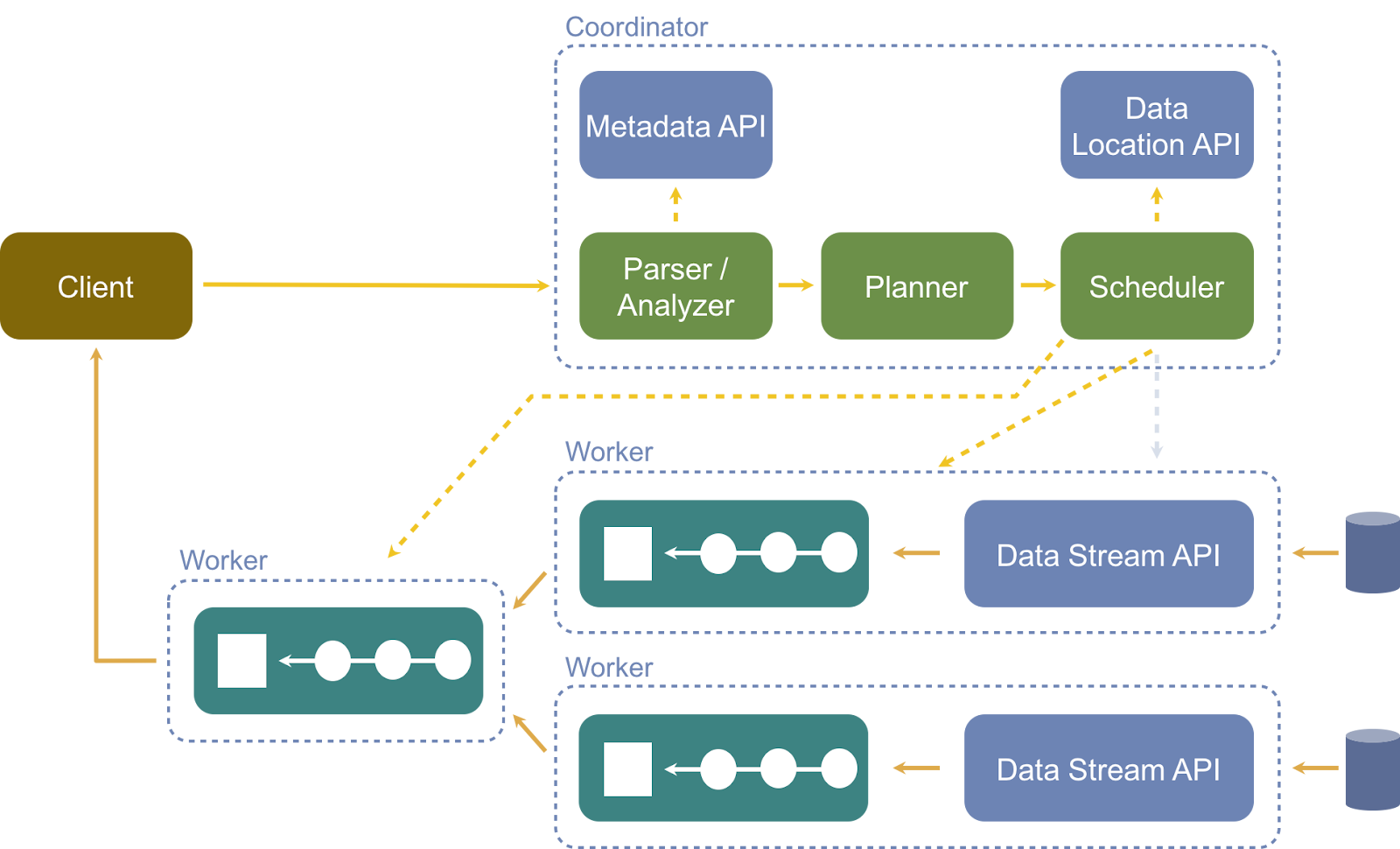
- Clients: They are PrestoDB consumers. Clients use the JDBC/ODBC/REST protocol to talk to coordinators.
- Coordinators: They are responsible for managing associated worker nodes, parsing, handling queries, and generating execution plans. They are also in charge of data delivery for processing between workers, which creates logical plans composed of stages, where every stage is executed in a distributed way using tasks across workers.
- Workers: They are compute nodes for executing tasks and processing data, allowing scale data processing and consumption.
- Communication: Each Presto worker advertises the coordinator using a discovery server to prepare for work.
- Connectors: Each possible data source type has a connector employed by Presto to consume data. The project https://openexchange.intersystems.com/package/presto-iris allows Presto to utilize InterSystems IRIS.
- Catalog: It contains information about the location of data including schemas and the data source. When users run an SQL statement in Presto, they run it against one or more catalogs.
Presto use cases
The InterSystems IRIS and Presto together allow you the following use cases:
- Ad-hoc queries: You can run ad-hoc queries with high performance against terabytes of data.
- Reporting and dashboarding: There is an engine to deliver high-performance data queries for reports, self-service BI, and analytics tools, e.g., Apache Superset (check out the sample in this article).
- Open lakehouse: Presto has the connectors and catalogs to unify required data sources and deliver scalable queries and data using SQL between workers.
InterSystems IRIS is a perfect partner for Presto. Since it is a high-performance data repository that supports distributed processing with the help of shards and associated with Presto workers, any volume of data can be queried in just a few milliseconds.
Installing and running the PrestoDB
There are various options (Docker and Java JAR) of how to install Presto. You can find more details related to it on https://prestodb.io/docs/current/installation/deployment.html. In this article we will utilize Docker. To facilitate understanding and enable a quick start, we have made a sample application available on Open Exchange (it was derived from another package https://openexchange.intersystems.com/package/presto-iris). Take the following steps to see for yourself:
- Go to https://openexchange.intersystems.com/package/iris-presto-sample and download the sample used in this tutorial.
- Start the demo environment with docker-compose:
Note: For the demo purpose, it operates Apache Superset with superset-iris and examples that come with it. For that reason, it takes a while for it to load.docker-compose up -d --build - Presto UI will become available via this link: http://localhost:8080/ui/#.
- Wait 15 to 20 minutes (there is a lot of sample data to load). When SuperSet finishes loading examples after 10-15 minutes, it should become available at the link http://localhost:8088/databaseview/list (type admin/admin as username/password on the login page).
- Now go to Dashboards:
- If we visit http://localhost:8080/ui, we can notice that Presto has executed queries and is displaying some statistics:
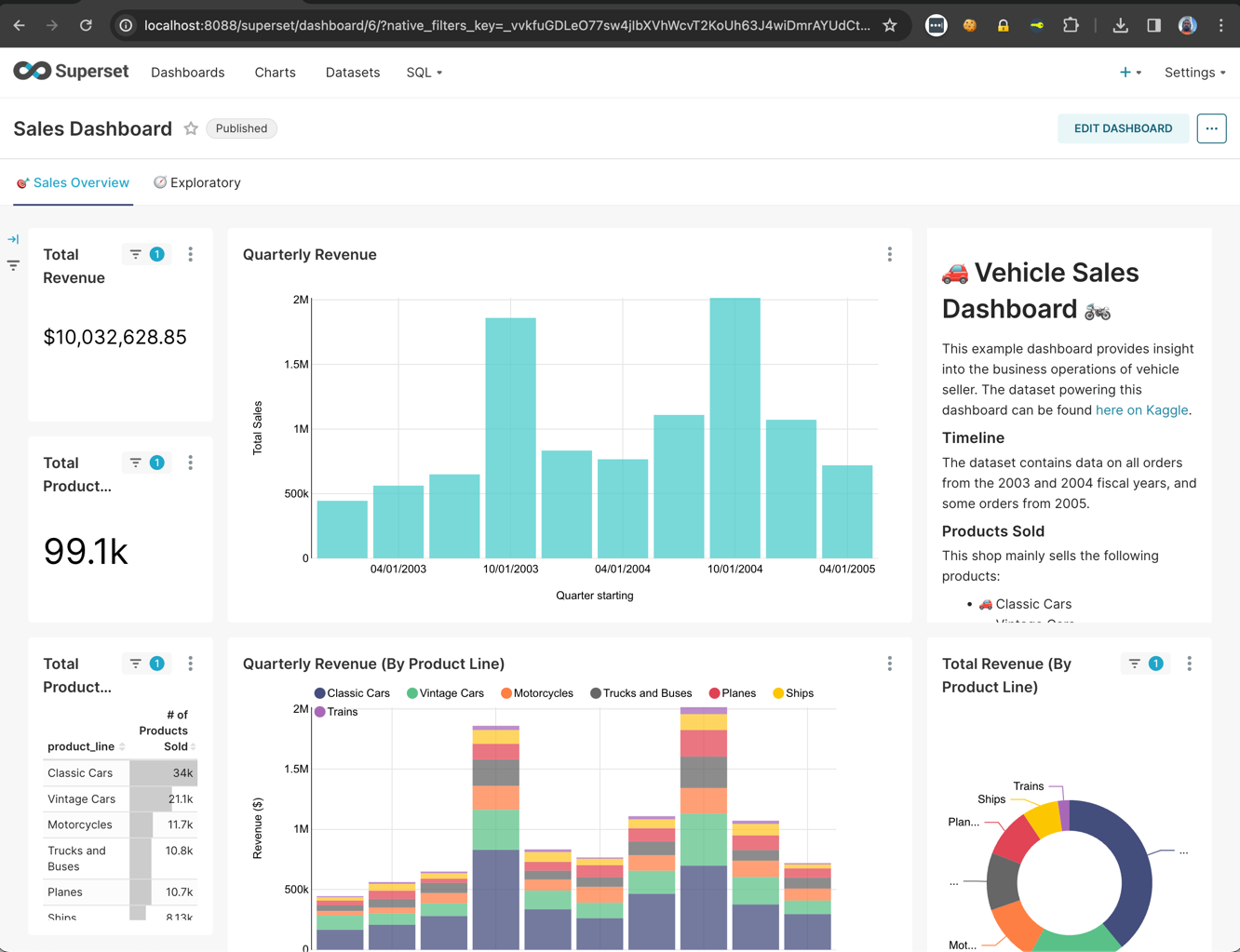
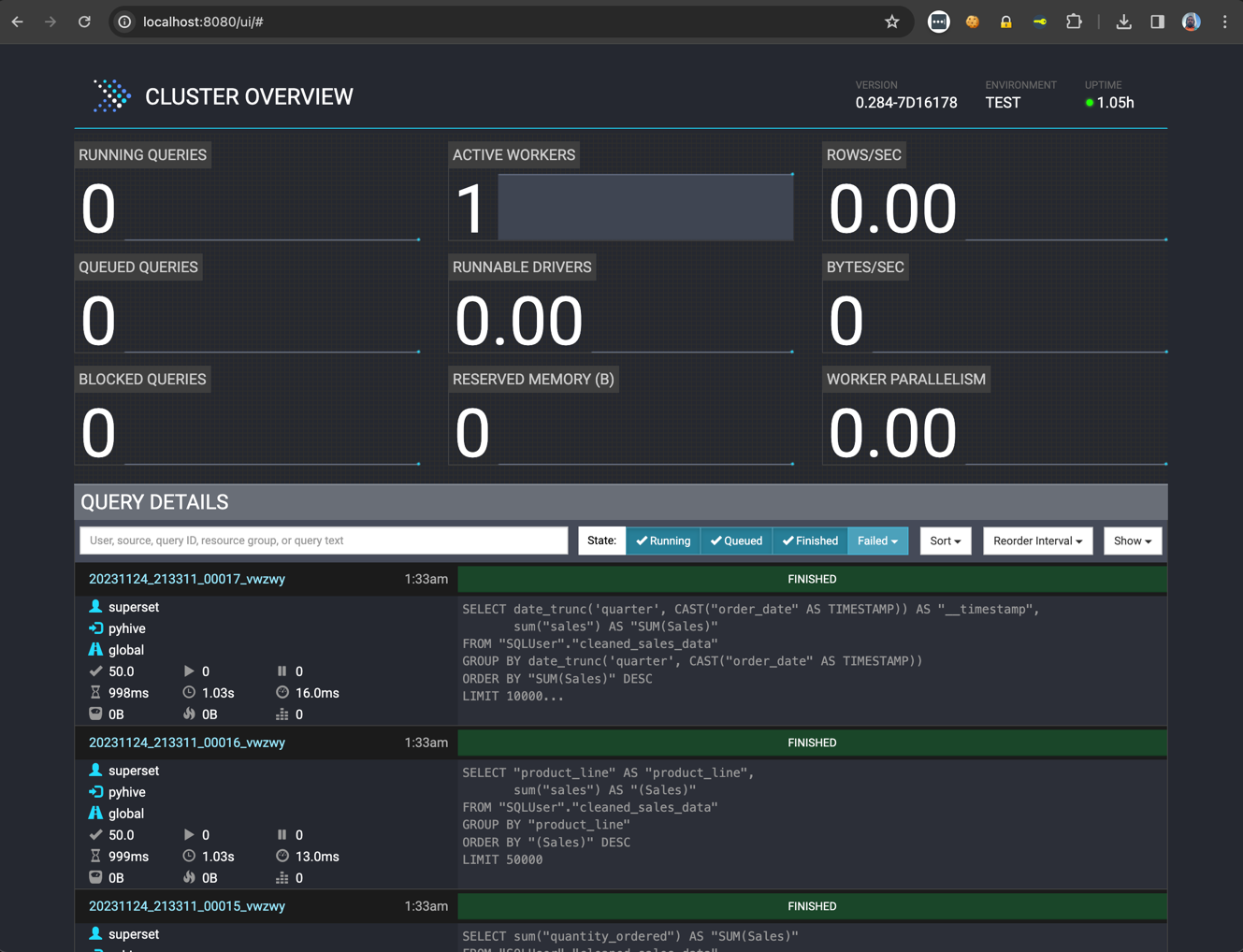
Above you can see the Presto web interface for monitoring and managing queries. It can be accessed from the port number specified in the coordinator Config Properties (for this article it is 8080).
Details about the sample code
Dockerfile
The Dockerfile is employed to create a PrestoDB Docker image with the presto-iris plugin and the InterSystems IRIS JDBC file included:
# Official PrestoDB image on Docker Hub
FROM prestodb/presto
# From https://github.com/caretdev/presto-iris/releases
# Adding presto-iris plugin into the Docker image
ADD https://github.com/caretdev/presto-iris/releases/download/0.1/presto-iris-0.1-plugin.tar.gz /tmp/presto-iris/presto-iris-0.1-plugin.tar.gz
# From https://github.com/intersystems-community/iris-driver-distribution
# Adding IRIS JDBC driver into the Docker image
ADD https://raw.githubusercontent.com/intersystems-community/iris-driver-distribution/refs/heads/main/JDBC/JDK18/com/intersystems/intersystems-jdbc/3.8.4/intersystems-jdbc-3.8.4.jar /opt/presto-server/plugin/iris/intersystems-jdbc-3.8.4.jar
RUN --mount=type=bind,src=.,dst=/tmp/presto-iris \
tar -zxvf /tmp/presto-iris/presto-iris-0.1-plugin.tar.gz -C /opt/presto-server/plugin/iris/ --strip-components=1
Docker-compose.yml file
This file creates 3 container instances: one for InterSystems IRIS (IRIS service), one for PrestoDB (Presto service), and one for the Superset (Superset service). The Superset is an Analytics visualization tool utilized for seeing data in Dashboards.
# from the project https://github.com/caretdev/presto-iris
services:
# create an InterSystems IRIS container instance
iris:
image: intersystemsdc/iris-community
ports:
- 1972
- 52773
environment:
IRIS_USERNAME: _SYSTEM
IRIS_PASSWORD: SYS
# create a PrestoDB container instance consuming the IRIS database
presto:
build: .
volumes:
# PrestoDB will use iris.properties to get connection information
- ./iris.properties:/opt/presto-server/etc/catalog/iris.properties
ports:
- 8080:8080
# create a Superset (Dashboard analytics tool) container instance
superset:
image: apache/superset:3.0.2
platform: linux/amd64
environment:
SUPERSET_SECRET_KEY: supersecret
# create an InterSystems IRIS connection to load sample data
SUPERSET_SQLALCHEMY_EXAMPLES_URI: iris://_SYSTEM:SYS@iris:1972/USER
volumes:
- ./superset_entrypoint.sh:/superset_entrypoint.sh
- ./superset_config.py:/app/pythonpath/superset_config.py
ports:
- 8088:8088
entrypoint: /superset_entrypoint.shThe iris.properties file
This file has the information required to connect PrestoDB to InterSystems IRIS DB and create an MPP layer for high-performance and scalable queries from Superset dashboards.
# from the project https://github.com/caretdev/presto-iris
connector.name=iris
connection-url=jdbc:IRIS://iris:1972/USER
connection-user=_SYSTEM
connection-password=SYSThe superset_entrypoint.sh file
This script installs the superset-iris library (for Superset support of IRIS), inits the Superset instance, and loads sample data into InterSystems IRIS DB. At runtime the data consumed by Superset will come from PrestoDB, which will be an MPP layer for IRIS DB.
#!/bin/bash
# Install the InterSystems IRIS Superset extension
pip install superset-iris
superset db upgrade
superset fab create-admin \
--username admin \
--firstname Superset \
--lastname Admin \
--email admin@superset.com \
--password ${ADMIN_PASSWORD:-admin}
superset init
# Load examples to IRIS
superset load-examples
# Change examples database URI to Presto
superset set-database-uri -d examples -u presto://presto:8080/iris
/usr/bin/run-server.shAbout Superset
This article used Superset for dashboards.It is a modern data exploration and visualization platform that can replace or augment proprietary business intelligence tools for many teams.Superset integrates well with a variety of data sources.
Superset provides the following:
- A no-code interface for building charts quickly
- A powerful web-based SQL Editor for advanced querying
- A lightweight semantic layer for defining custom dimensions and metrics fast
- Out-of-the-box support for nearly any SQL database or data engine
- A wide array of beautiful visualizations to showcase your data, ranging from simple bar charts to geospatial visualizations
- Lightweight configurable caching layer to help ease database load
- Highly extensible security roles and authentication options
- An API for programmatic customization
- A cloud-native architecture designed from the ground up for scale
Sources and additional learning materials
- Extensive tutorial about PrestoDB: https://www.tutorialspoint.com/apache_presto/apache_presto_quick_guide.htm
- PrestoDB documentation: https://prestodb.io/docs/current/overview.html
- Presto-iris plugin: https://openexchange.intersystems.com/package/presto-iris
- Iris-presto sample: https://openexchange.intersystems.com/package/iris-presto-sample
- About Superset: https://github.com/apache/superset
- Superset with InterSystems IRIS: https://openexchange.intersystems.com/package/superset-iris
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)