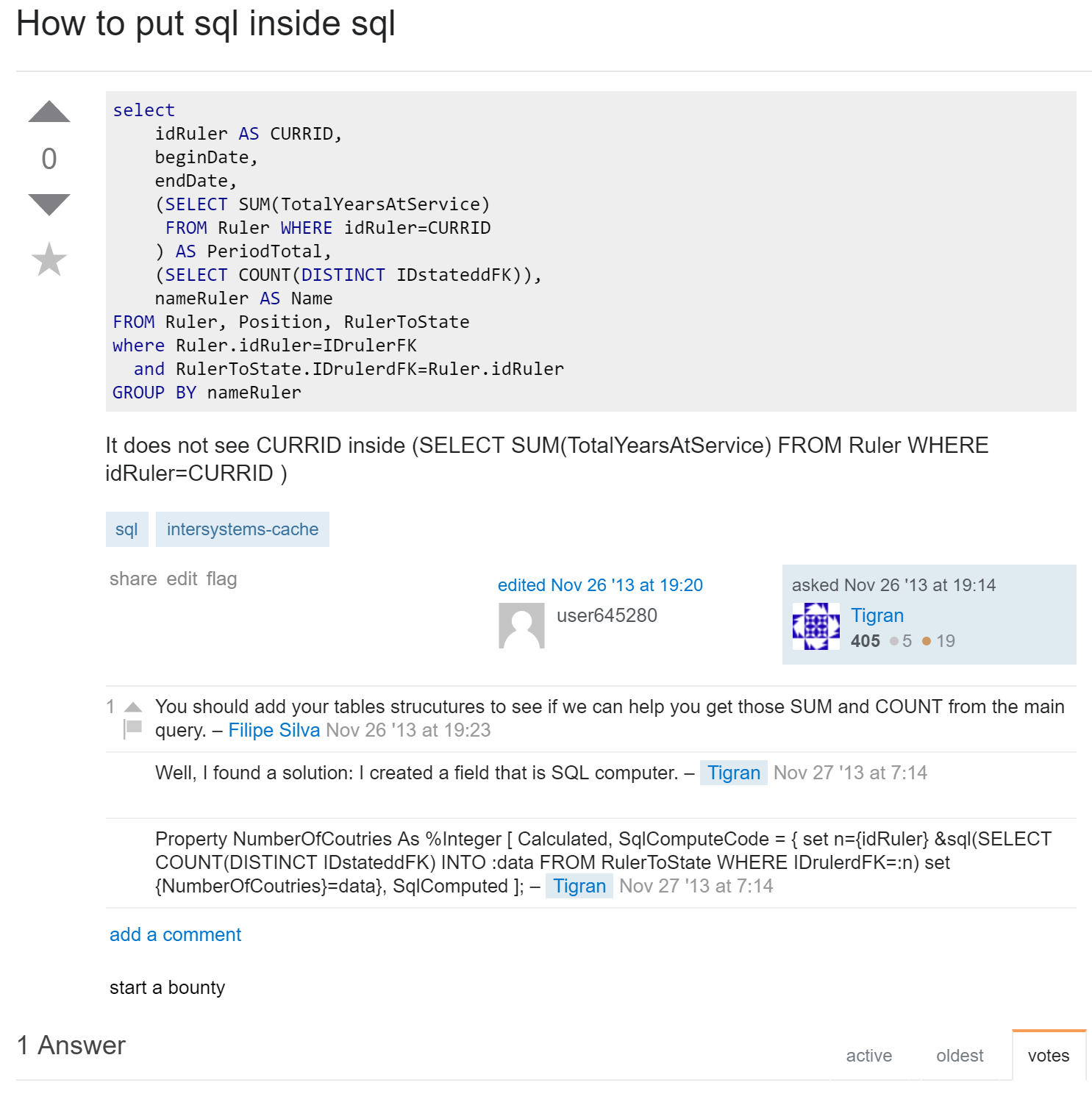
I'd expect it supported via this set of share tools

but apparently it just sends the link to the given address. Ok, you need page scraper then - and the easiest tool for this I know is uKeeper by Umputun (very famous in Russian IT podcaster, one of voices of "Radio-T" podcast).
P.S.
It's quite normal for all "share-buttons" to just send a link with title and not sending full content, they are all intending to be used in social networks where text length limitation is the major factor.
If you need article content to get delivered to your email "inbox" - use RSS subscriptions and RSS-enabled mailer. Like Microsoft Outlook :)
- Log in to post comments