Thank you Marc
- Log in to post comments
Thank you Marc
Hi
Can you include the tags where you reference the style sheets. I see you use a mix of style="", class=".{name}" and id="#{name}"
Nigel
I'm Impressed. That assumes that a word does not change meaning based on the characters to the left or right. So I assume you have taken that into account in your solution as I believe that Chinese is one of those languages that can mean different things depending on the surrounding words and even tone. But then, China is not part of NATO, so the question is academic.
How about French? Does anyone have a French example of conveying masculine/feminine attributes in the resultant interpreted message? i.e. how do you ensure you get your Le's and La's right?
Ok, now it's me being silly. I suspect there is no shorter version of this code, so well done to the winner.
You can make it smaller by removing the #dim, which is not required.
The only time I use #dim is if I am working with a class that I have got to via an object chain:
set class=##class(%Dictionary.CompiledClass).%OpenId("MyClass") for i=1:1:class.Properties.Count() set tProp=class.Properties.GetAt(i) write !,prop.NameIn that case, I will use '#dim tProp as %Dictionary.CompiledProperies' as I don't remember all of the properties in the CompileProperties class. Once the code works, I remove the #dim.
If you are a masochist and like a little pain, here is a lengthy description of another scenario where I use #dim where I have many very similar classes in content, and I use a lot of $clssmethods and $properties in my code.
Let us assume you have three message classes. The message classes will have some properties that are common to all message classes, and the message classes differ only in the fields they contain that are derived from the source system that created the message:
The base properties are the Create/Process/Completed TimeStamps, RequestFHIRJSON, ResponseFHIRJSON, RequestHL7Message, ResponseHL7Message, FileDirectory, SourceFileName, ResponseFileName, HTTPMethod, HTTPResponseCode, RequestStatus, MessageStatus, MessageTextNotification and a few others.
The HL7 or FHIR message that is created by a Data Transform (DTL) that transforms data in the source database into the target HL7 or FHIR message
The Message also contains the HL7 or FHIR response message (Operation Outcome in the case of FHIR, ACK/NACK for HL7)
Yous have methods to CreateMessage(), UpdateMessage(), GetNextMessage(), Complete Message(), ResendMessage(), PurgeMessages()
The variable properties in my three examples are:
1) PatientID for Message 1
2) PatientNumber, VisitNumber, EpisodeNumber, ActivityDate for Message 2
3) Hospital Folder Number in Message 3
The Methods I have listed all contain $classmethod calls, and I don't really need to worry about the fields specific to the type of message. If I am creating a message or updating a message, I pass an array of DataTypes into the method where the 'key' in the array is the property name, and the 'Value' is the value for that property.
I do use the %Dictionary.CompiledClass definition for the Message Class definitions so that I can determine whether the Property referenced in the Array of Datatypes is a %Library Data Type, a Foreign Key or Designative reference to a value in another class or a Collection/Array/List so that I know whether I am just setting the property value in my message object to the value in the Array of Property Values or if the property value is the ID of an object in another class in which case I will use a SetObjectIdAt() on the value and in the case of the List/Array Collections I either use SetAt() or InsertAt(). As I am using the CompiledClass Dictionary reference, I check to see if the property in the Array of Datatypes exists in the properties of the message class. However, in my Business Process, I want to get the Message fields because they will tell me what Class/Table I will access using the data supplied to retrieve the source record fed into the DTL to generate the FHIR/HL7 message.
The Business Process has been passed an Ensemble Request message with the MessageId returned by the GetNextMessage() method, which my Business Service calls. The Business Service has a property "Message Queue Class Name" configured when I add the service to the production.
The Business Process Opens the Message Object and in that case I use a #DIM purely that when I use
set obj=$classmethod({message_Queue_Class_name},"%OpenId",{Message_Id})
set tPatientId=obj.PatientId, and because I have used #dim the editor will provide a list of property names as I type in obj. and that makes it easier to select the field that I want to access. I have used simple examples for the variable fields in my different message class examples. Still, as my Message Queue Classes have about 15 common Properties, it is useful to have that IntelliSense functionality so that I don't have to keep remembering whether my common property name was SourceFHIRMessage or SouirceMessageFHIR.
Once my code works, I comment out the #dim line rather than remove it so that if someone else has to maintain my code, they can uncomment the #dim statement. It may then help them with the Intellisense on the Property Names on the class being Manipulated.
Hi Robert
I desperately need an example of Angular using REST to talk to a FHIR server to convince the company that we should be using Iris for Health and Angular for our upcoming developments. The issue is I don't know angular, I understand Rest and I understand FHIR. How can I get up and running in Angualr in the next 3 days.
Nigel
Hi
Please can you explain a little more about the terms contiuous integration and jenkins
Thanks
Nigel
That looks great. I've been exploring other Developer Communities (no, I am not going to defect, I am looking for inspiration from the Python/R/Angular communities), and none of them is as nice and clean and fresh and as well thought out as the ISC DC is, along with OEX and GM.
I asked a question on one of them, and it was rejected for some violation of their stringent rules of what is a question vs a comment vs a .... they sent me a 500-page user manual on the rules. It felt like being back at school. The tone of the email they sent me detailing why my question wasn't a question had the same tone of voice that the wife of the Head Master at the boarding school had when she caught us swimming in the school swimming pool while she was searching the school grounds and all of the hiding places where the headmaster could sneak into to have a drink which was strictly against the school rules as we were a Methodist School. You should have seen her face, on the day, in front of Parents and Schoolboys, when the addiction he had so skilfully kept hidden for most of the 20 years that he had been at the school, were unexpectedly revealed when he fell off the stage into the band area in front of the stage and having picked himself up, he promptly tripped and fell into the strings of the ancient grand piano. The DC Moderator I offended wasn't as drunk as our headmaster nor quite as rude as the headmaster's wife as she screamed at him while the Parent and boys fell off their chairs in either religious shock or convulsive laughter.
Then I came across KDN*G%ETS (sp??) with the main Editor getting into arguments with the DC members who were voicing their opinions of his "5 Best Python Examples for 2021' which, most members agreed, was terrible. The first app was no better than "Hello World" but less fun, the second didn't work, the third was just pointless, even as an example, and quite possibly illegal because if a new developer were to try it, they would most likely never code in their lives again as it was the coding equivalent 'self-harm with nailbrush and bleach'. The 4th was ok but, as one person commented, "it would be quicker to go 'Hey Google, what's the weather like today?'" and the 5th one wasn't a code example at all. It was an advertisement for Jungle Finger Nails and had nothing to do with python other than you sometimes find pythons in jungles.
He was getting quite upset at being treated so awfully by his readers. He pointed out that it had been given a badge of 'best contribution of the month'. It would have been interesting to know what the competition had been because it was quite hard to imagine just how bad those contributions must have been. Secondly, as another helpful DC member pointed out, it was the Editor who had awarded the badge to his own article.
The Home Page had been designed using those three winning web design methodologies that advocate:
cramming as much stuff onto the page as possible, preferably at right angles to the surrounding elements. They had used an assortment of colours that had been chosen on the basis that they were unique (read 'no one would use that colour because it is really horrible'),
balanced, tasteful palette (read 'Orange and Purple really do go very well together, my girlfriend does this thing with Orange and Purple and it's a really cool man'),
and finally the ' HTML 5 without animation is like, /...., well,/... you know its like.... ' (read, 'if the thing next to this thing isn't flashing then you must make it flash and hop across to those cute green and pink SVGs fighting in the Title bar and noooo,... you know you can't have a blink rate on the exclamation points slower than the edge lighting colour change inspired by the lesser-known and largely forgotten collection of musical ditties - 'Experiments and variations on Bach in D#, F minor, with Geese and Zither' by Dvorak. I am sure that the twitching that has developed in my left eye is somehow linked to accidentally opening newsletter emails from K%79&$*S and not being able to delete them quickly enough.
Hi
I'd be interested in participating. An opportunity to work with a technology that I am very aware if but has not been a requirement in the work I do though HST has built an Operational Data Store.and we have a BI analyst who uses Deep See (Ensemble 2018). And Analytics in IRIS has gone to a whole new level. So yes I would like to participate. On IRIS?
Nigel
Hi Andre
I have read your article and I think that it is worthy of being included in this thread as you speak many truths. I am sure that many people work with technology, from the Customer Project Managers, the Business Analysts, the Team Leaders, the Scrum Master, the Senior Developers, Junior Developers, Testers, Customer UAT testers, and ultimately the Users of the resultant Technology Solution who view their role in the chain with Blinkers and work on the basis that as long as they do their job properly (and that is a word that can mean many different things) and are either unconcerned about the people who fill the other roles in the chain or view them as a necessary evil. But I also believe that there are technologists who are very conscious of the fact that they are an important element in the overall delivery of a solution. It is very rare to find people who can wear the hat of all of the players in this chain. I have met maybe 3 people in my entire career who just stood head and shoulders above everyone else in their ability to communicate and understand the needs and requirements of the customer, translate those requirements into a set of tasks for the Business Analysts to prioritize, document, create the project scope and timeline, write requirement specifications that can be understood by the customer and the development team, be able to sit with the senior developers and discuss the possible approaches to crafting a solution, who can clearly identify which tasks should be handled by the senior developers and those that should be delegated to the more junior developers, create testing plans for the testers and the documentation writers and ultimately guide the Customer UAT team through the stringent test scenarios to ensure that the application does what was requested, does not crash, does not present the user with an explosion of colour and animation and finally go back to the customer and get that all-important sign-off so that the invoicing and payments can be finalised. Some of us have been lucky enough to have been assigned to a project where we were able to interact with the customer, understand their business, understand their pain or their ambitions, then take that knowledge and produce the requirement specifications, technical process flows, choose the software elements, write the code that pulls all of the components into a functioning whole, documents their code such that future developers who have to work with that code can do so without messing it up because they are unaware that a statement in line 23 of 5000 lines will inadvertently cause the logic on line 2356 to take an unexpected step to the left and render the program unusable. Very few developers get to spend time with the quality assurance staff and ultimately the users who have to use the application to do their jobs and be able to go home without a blinding headache and a sense of dread that tomorrow they are going to have to fight with the application to get the printout or that all-important "Your data has been saved. Click OK to proceed" popup.
I have seldom met a programmer who will concede that their code is not as good as the person coding next to them, or for that matter finding a developer who can gracefully and politely read some truly awful code of another developer and take the time to work with that bad developer and help them become a better programmer without inadvertently step on 1 f 20 emotional and ideological traps that arise in every one of these encounters. Or maybe I would use the analogy of the McDonalds Ice-cream specialist who was born to whip up the most perfect McFlurry who has to stand and watch a steady stream of ice-cream servers who don't give a damn and will be leaving in a month to go and pour soda at Wendy's.
For the last 50 years software creators, whether they be individuals or technology companies, have discussed, and theorized, and consulted psychologists and time-management experts, and even astrologers to come up with the definitive guide to creating perfect, absolutely perfect, application. Entire libraries of books and templates and methodologies and Predictive Indicators intended to match the right person to the right role and despite those 50 years and the brilliant, practical, theorists and technologists who have contributed, with dedication and fervor to this topic, And yet, for every model that has emerged from these think tanks, 100 bad applications are spilling out the doors of the technology companies.
And I haven't even started on the external forces, the project managers, the customer relations manager, the accountants, the middle managers, and worst of all the salesmen who, in just doing their jobs, manage to inflict sufficient damage to the 'plan' thus guaranteeing that the final product will be ....less.
But then you encounter a group of people who have formed themselves into a community, a 'Developer Community', who come from a myriad of different backgrounds, skills, methodologies, personalities, and socio-economic, gender-based cultures who miraculously have one thing in common. They love to code. Their hearts soar when they interact with a user who says 'Thank you because of some modification that they have made that has made that user's life just that little bit better. And all of us have at some time or other written a bad piece of code or have struggled to fit into the 'TEAM', or had to deal with a salesman who has sold unrealistic solutions and unachievable timelines to a customer who in reality didn't actually know what they actually wanted to start with. We have seen it all, we have notched up successes and strive hard to forget the failures and yet we go to bed at night and we dream of tropical islands with dancers wrapped in fine silks with pet tigers on leads and woken up the following morning with 5 pages of code written vividly on the insides of their skulls and in a blinding flash of light they know that they have cracked it. The mists of possibilities and uncertainties and intrusions and indecision that has plagued them for the previous 4 weeks have overnight coalesced into the 'Perfect' solution. Their fingers are already tapping at their laptops as they eat their breakfast and for the next 8, 18, 80 hours magic flows from their fingers into that IDE that is the interface between their imagination and the architecture that will swallow up their code and compile it into the module and voila! It's done, and it's beautiful.
And then we go home and get up the next day and do it all again. And as we create solutions we come to our community and we bounce ideas off each other, we seek out the nuggets of knowledge and experience from our friends who went through the process of being the first person to master a technique or understand a piece of functionality that is almost incomprehensible to most of us because or minds might not be wired in such a way that understanding that functionality was as easy as watching the Eurovision song contest without crying.
What we all share in common though are years and years of tuning our coding styles, learning and absorbing emerging technologies, developing the skills to share our knowledge with the people we work with without making them run from the room sobbing because you have been too brutal in your appraisal of their work and it is through a community like ours that so many of us have become the skilled and dedicated developers that we are.
What I do know is that generally speaking, I have met more developers who have been able to help the Business Analysts understand the requirements, ask the right questions of the customer to find out what they actually need, pacify the project managers that their agile, and scrum, and Jira, and storyboards will get to the finish line without incurring penalties for late delivery. Who find the time to document their code knowing that no matter how well it is written it is going to take another developer some time to work out what you have written and how it fits into the bigger picture and finally, one day, they get to meet the user who is using that application who turns round and comments that this application has helped them get their work done quickly and efficiently, that doesn't shower them with pompous popups asking them how they could be so stupid to put a text letter into a numeric field.
We may not be able to ensure that every element in the chain is going to work as expected and that ideas and requirements don't occasionally get twisted in translation nor make every single user equally happy but we can control the space that we occupy and we know what we are doing and we have adopted different coding styles over the years and we find our selves at a point where we believe that we can layout a template, a structure, a developers ethical code and produce a set of standards and conventions on which we all (give or take) agree, if followed, will stand a chance of guaranteeing that the programs we write work, are readable and maintainable and when fitted into the whole will generate an application that works, is good, beautiful even.
We take pride in our community. We welcome the input of the outside world, we like to learn and experiment and listen to the experiences of our comrades and when we are in Boston we will gather in a fairly dark room and drink a little too much and listen and watch as one of ours demonstrates his latest little app or tool or plugin and it makes us happy and we feel very much at home.
Nigel.
Undoubtedly VS Code. There are new ObjectScript Plugins being developed all the time and now that you can start using Python and R in the latest IRIS 2021.1 (in the Early adopter program) you just add the appropriate Extensions for these languages as well. It is very obvious that VS Code is growing in popularity just by the sheer volume of extensions available. The extensions for ObjectScript include the Server Manager, gi::locate, gi::connect, ObjectScript Language Server, CacheQualityQ for both VS Code and Cache Studio that helps you write better code. The built-in Source Control connects to GitHub or private GitHub servers and there are a number of GIT extensions. I'm just waiting for someone to add support for the graphical DTL, BPL, and Business Rules (though of course, you can do those through the Management Portal (which you can also run within VS Code). Personally, I hated Atelier and as I had used Cache Studio for roughly 30 years the idea that I might want to use a different Editor never crossed my mind and Atelier was just scary for a simple developer like me but VS Code changed all that. I still use Cache Studio though (it's a hard habit to break, not that I particularly want to break that habit)
Nigel
When i run the following:
set srv = $system.external.getServers()
write srv.%ToJSON()
["%DotNet Server","%IntegratedML Server","%JDBC Server","%Java Server","%Python Server","%R Server","%XSLT Server"]
R does appear
Nigel
Hi Ben
I certainly would like to join the Python EAP. I was actually sent an invite but it slipped through the gap and I had communicated with Eduard to issue another Invite. I have already installed the InterSystems IRIS 2021.1 PYTHON kit and I just need a license. At Anastasia's recommendation, I sent a request to Bob to get a license. I don't know if it's too late to join the current EAP as gather there will be another one but if I can join in the current one then that would be great
Hi Ben
Yeah, I added the comments about APL because I just happened to notice it in Wiki while looking at R and it reminded me of my Actuarial days. It was a curious language being almost entirely symbolic in nature. The standard "Hello World" program that every language tutorial teaches was something more like
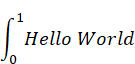
I learned it in 1981 and I see that there have been releases of APL2 and so I guess that somewhere someone is using it (probably in Mathematical Modelling which is what many Actuaries do instead of designing Insurance Policies and staring at Life Expectancy Tables which was what Actuaries did in those day) and I think that a language like Julia (which I have also downloaded and played with a few months ago is much more suited to Pure Math). Can I ask a question, I notice that Python is an Interpreted language like ObjectScript. Was that part of the decision to include it into InterSystems IRIS (and also that it is one of the most popular languages on the Top 10 language list) based on the fact that it could ultimately be compiled down to .obj code?
Can't wait for Python, I checked out R on Wiki. It looks interested for graph plotting and statistical analysis. The Wiki page also mentioned APL which is defined as:
APL (named after the book A Programming Language)[3] is a programming language developed in the 1960s by Kenneth E. Iverson. Its central datatype is the multidimensional array. It uses a large range of special graphic symbols[4] to represent most functions and operators, leading to very concise code. It has been an important influence on the development of concept modeling, spreadsheets, functional programming,[5] and computer math packages.[6] It has also inspired several other programming languages.[7][8]
in Wiki
I learned this language while I was studying to become an actuary and during the university holidays I worked at Legal & General who were the Insurance company who were sponsoring my University Tuition and during or of these work experience holidays, instead of putting me in the room where the actuaries worked, they put me ina room with an IBM computer with a special keyboard and told me that this computer was specifically designed to run APL programs. Here are some examples of the language:
Suppose that X is an array of numbers. Then (+/X)÷⍴X gives its average. Reading right-to-left, ⍴X gives the number of elements in X, and since ÷ is a dyadic operator, the term to its left is required as well. It is in parenthesis since otherwise X would be taken (so that the summation would be of X÷⍴X, of each element of X divided by the number of elements in X), and +/X adds all the elements of X. Building on this, ((+/((X - (+/X)÷⍴X)*2))÷⍴X)*0.5 calculates the standard deviation. Further, since assignment is an operator, it can appear within an expression, so
SD←((+/((X - AV←(T←+/X)÷⍴X)*2))÷⍴X)*0.5
The following expression finds all prime numbers from 1 to R. In both time and space, the calculation complexity is {\displaystyle O(R^{2})\,\!} (in Big O notation).
(~R∊R∘.×R)/R←1↓ιR
Executed from right to left, this means:
ι creates a vector containing integers from 1 to R (if R= 6 at the start of the program, ιR is 1 2 3 4 5 6)↓ function), i.e., 1. So 1↓ιR is 2 3 4 5 6R to the new vector (←, assignment primitive), i.e., 2 3 4 5 6/ replicate operator is dyadic (binary) and the interpreter first evaluates its left argument (fully in parentheses):R multiplied by R, i.e., a matrix that is the multiplication table of R by R (°.× operator), i.e.,| 4 | 6 | 8 | 10 | 12 |
| 6 | 9 | 12 | 15 | 18 |
| 8 | 12 | 16 | 20 | 24 |
| 10 | 15 | 20 | 25 | 30 |
| 12 | 18 | 24 | 30 | 36 |
R with 1 in each place where the corresponding number in R is in the outer product matrix (∈, set inclusion or element of or Epsilon operator), i.e., 0 0 1 0 1∼, logical not or Tilde operator), i.e., 1 1 0 1 0R for which the corresponding element is 1 (/ replicate operator), i.e., 2 3 5And I wrote a number of programs which had the IT department asking "How on earth did you do that and what does it mean?" to which I replied "I asked the computer to do this for me and it said 'Yes Nigel' and the programs worked. It was then that I knew I was destind to become a developer . When, a few years later in London I was introduced to Multidimedsional structures I already knew what they were because of my exposure to APL.
Dear InterSystems, how about introducing APL into our library of analytical programming languages?
Nigel
That sounds really cool. I have a friend who had a house in Cape Town and he had installed Solar Panels, water collection systems, and everything in his house from his music system, alarm system, gates, garage doors, lights, curtains, fridge were all controlled through an app on his phone. His solar panels and storage cells effectively covered all of his electricity needs and his electricity meter for City Power cost about R5 a month
Hi Utsavi
How are you doing with this challenge. Have you got a working solution yet? If so please can I have a look. If I have managed to help get you to where you need to be please mark one of my replies as an acceted answer
Thanks
Nigel
Hi
Glad to hear that you have your IRIS on Raspberry Pi. Before I send you some suggestions can you give me a bit of background on what aspects of IRIS you are most interested in ? I take it you have access to the Open Exchange and secondly how much experience do you have with ITIS or Ensemble?
In the meantime here are some suggestions:
https://openexchange.intersystems.com/package/sql-rest-api
https://openexchange.intersystems.com/package/ObjectScript-Package-Mana… (ZPM is the most useful tool for installing Open Exchange Applications
https://openexchange.intersystems.com/package/zpm-registry This will show you a list of OEX apps that are zpm ready
Are you using Cache Studio or V S Code and do you use Git. If you use V S Code then there are a number of Objectscript Extensions available and they are all useful
https://openexchange.intersystems.com/package/intersystems-iris-dev-tem…
https://openexchange.intersystems.com/package/Trying-Embedded-Python There is going to be a lot of Python apps apppearing on OEX now that we have a version with Python fully integrated into IRIS (first implementation of Native Python within IRIS
Python opens the gateway to more adventurous use of ML, NLP, and AI and there are a number of ML nd I example (with or without Python)'
Some useful information on Python at
https://www.geeksforgeeks.org/defaultdict-in-python/
https://openexchange.intersystems.com/package/OCR-Service
DBeaver is an excellent Databse Viewer/Creator with native support for IRIS JDBC and its free
https://openexchange.intersystems.com/package/DBeaver
https://openexchange.intersystems.com/package/integratedml-demo-template
That should get you started.
Please let me know how you get on with these and if there is anything more I can help you with just message me
Nigel
Olga, I love you! and my InterSystems Logitec Camera arrived yesterday and it is beautifully designed and solid and take great pictures and videos so that along with my JBL clip and my InterSystems socks are my 3 most prized possessions at the moment so the opportunity to earn extra points and I'm looking forward to the next great reward that we can aim for when redeeming points. ![]()
![]()
![]()
Thank you Julian and Vic and especially John Murry whose article on the topic is excellent and your follow-up article, Julian, on your experience of using this solution and what you learned was equally well written. I have combined both articles into Word and added them to my knowledge base and I am going to try this myself as my laptop has crashed twice in the last year and a half and I not only lost several days worth of development work but entire directories of databases, documentation and code exports from 30 years of developing Cache applications. I have now connected to OneDrive, Google Drive, DropBox and iCloud and hold copies of My Documents, My Pictures, My Music, My Software, My Sent/Received Email Attachments in all of them and I use automation tools such as IFFT, Zapier and Power Automate to create flows to synchronize these folders to the point that the only data I actually store on my hard drives are installed applications and my Ensemble and IRIS databases and as I have had to start using GIT in the company I work for I have integrated GIT into VS Code and Studio so that at least my current work is uploaded to my personal GitHub repositories and the company Git server.
Thank you
Nigel
Hi Robert
This is an ambitious project with a wide scope of scenarios to take into account. I have spent quite a lot of time recently looking through OEX to find applications that might contain code or functionality that would help me understand how to use features of IRIS or external technologies such as Bootstrap, Angular, Python. This took me into a world of Node.js, NPM, Gradle, Gulp, GIT, TypeScript, Packages which I have either had little or no knowledge of as they have never been required in the applications that I have built over the last 30 years. To be quite honest I have relied on the Readme.MD files in the OEX install kits to install many of the applications that looked promising. I follow the instructions and generally speaking 90% of the 50 applications that I downloaded did install easily and though I didn't necessarily always run the application (as I was more interested in the application code) but those that I did run worked as expected.
Some of the OEX Readme.MD documents are very good with detailed installation notes (especially those that take into consideration that not everyone is using UNIX or Docker or Containers or ZPM so I appreciate it when they include installation notes for each of these scenarios). Information on any prerequisite requirements is especially appreciated when they involve 3rd party apps or utilities that may not be familiar to those of us who have lived in a Cache/Ensemble/IRIS cocoon for many year. Step-by-step installation guides and how to activate the application once it is installed are very important especially when the application makes use of 3rd party technologies.
Of the 50 apps I downloaded there were very few examples where the Readme.MD file contained only the barest of information but none were so limited that I was unable to install or use the code. When the Readme.MD file is expansive I have developed a habit of copying the contents into a word document and filing them for future reference as well as adding them into the company knowledge base for other developers to review. One area of documentation that tends to be overlooked iare notes on how to uninstall the application. Applications that have been installed using NPM Install can be uninstalled with NPM Uninstall. Many of the apps that I have downloaded recently were built using ZPM and as we don't yet use IRIS at the company I work for any exploration of IRIS has had to be in my own time and so I started using ZPM and have used it to download quite a few repos. I was very impressed. There have been 2 or 3 installs that threw up errors as they required an earlier version of npm or some other 3rd party component than the version installed by other applications and generated either medium or fatal errors. Some of them can be fixed by using npm audit fix or npm audit fix -force.
One of the applications I installed "Forms" installed entire libraries of bootstrap/MDB/Font-awesome kits of .js/.css/fonts/images/icons and I am not sure how easy it would be to uninstall it cleanly. In an extreme example such as this then I think that there should be comprehensive notes on how to uninstall the application and remove any residual files and directories that remain after the uninstall. So I think that your rating algorithm should factor in the quality of the uninstall instructions based on the complexity of the installation.
I would be very willing to assist you in this exercise if there is anything that I could contribute.
I also think that as DC members we should be more proactive in writing reviews of applications we have downloaded and comment on our experience of installing and using the application, how our knowledge of the technologies used has been benefitted, and maybe some notes on why other DC members should consider downloading the app if it is a really good example of an IRIS component usage especially if they have been able to leverage that knowledge in the development work they do in their day jobs.
One final comment I'd like to make is that the Coding Competitions have been an excellent way of getting developers to explore aspects of IRIS and IRIS for Health that they are probably not being exposed to in their day jobs and has resulted in some truly useful applications especially in the areas of VS Code extensions, ML, AI, Python, Angular, Node.js, Git which are used by so many developers who do not use InterSystems products and as InterSystems are investing a lot of energy in integrating these technologies into IRIS which goes a long way to encourage developers who don't currently use InterSystems products to start seeing IRIS as an interesting technology to investigate especially if they can adopt IRIS into their current development toolset supported by a vibrant Developer Community, well documented, and an ever-increasing repository of sample applications that use technologies such as Node.js, Python, Angular, JSON, OAuth which are all high on the list of most popular languages and security solutions.
Nigel
Hi Utsavi
I have sent you an email with the classes.
I have managed to get all of the scemas to be generated correctly and exported to JSON correctly. the only issue is that the if I just use the class name as the 'key' in the array you will only get one instance of each schema however if I append the counter to the classname then it will create multiple instances of each schema in the class
JSON
{
"%seriesCount": "1",
"parentId": "Parent226",
"parentName": "Example: 228",
"schemas": {
"Contact12": {
"%seriesCount": "1",
"contactGivenName": "Vincent",
"contactSurname": "Chesire",
"contactPhoneNumbers": {
"Phone-1": "+2704 435 4225"
}
},
"Contact3": {
"%seriesCount": "1",
"contactGivenName": "Marvin",
"contactSurname": "O'Brien",
"contactPhoneNumbers": {
"Phone-1": "+2796 757 9897",
"Phone-2": "+2796 079 6474",
"Phone-3": "+2721 225 2055"
}
},
"Patient7": {
"%seriesCount": "1",
"patientId": "PAT-000-494",
"patientDateOfBirth": "2020-05-31T02:44:39Z"
},
"Practitioner11": {
"%seriesCount": "1",
"practitionerId": {
"%seriesCount": "1",
"practitionerId": "PR005",
"practitionerTitle": "Dr.",
"practitionerGivenName": "Al",
"practitionerSurname": "Beatty",
"practitionerSpeciality": "Orthopedics"
},
"practitionerIsActive": false
},
"Practitioner4": {
"%seriesCount": "1",
"practitionerId": {
"%seriesCount": "1",
"practitionerId": "PR0043",
"practitionerTitle": "Dr.",
"practitionerGivenName": "Maureen",
"practitionerSurname": "Gomez",
"practitionerSpeciality": "Orthopedics"
},
"practitionerIsActive": true
},
"Practitioner6": {
"%seriesCount": "1",
"practitionerId": {
"%seriesCount": "1",
"practitionerId": "PR0099",
"practitionerTitle": "Prof.",
"practitionerGivenName": "Pam",
"practitionerSurname": "Russell",
"practitionerSpeciality": "Orthopedics"
},
"practitionerIsActive": false
},
"Practitioner8": {
"%seriesCount": "1",
"practitionerId": {
"%seriesCount": "1",
"practitionerId": "PR0086",
"practitionerTitle": "Mr.",
"practitionerGivenName": "Debra",
"practitionerSurname": "Zevon",
"practitionerSpeciality": "Peadiatrics"
},
"practitionerIsActive": true
},
"Reference1": {
"%seriesCount": "1",
"referenceId": "Reference-419",
"referenceText": "UMG]QX/&V1GLLCN ? \"RV[$IUYCQM-]]+7HSP:[N%MG\\V!L)P><>A'4>?7?,.0N*,UB( \\4)J!$_,X35D;S=61V?=SJ<,!&5P",
"referenceOID": "8.11.0.54.18"
},
"Reference10": {
"%seriesCount": "1",
"referenceId": "Reference-423",
"referenceText": "\"A/#VZZ?<=5E.'BZT<6^DQ!I65JU'+GB/3T[2+II9N7W8EUKHRWS;1RZM&2(A)",
"referenceOID": "7.17.7.19.18"
},
"Reference13": {
"%seriesCount": "1",
"referenceId": "Reference-424",
"referenceText": ",L^2SP.UY\"+'Y;OAG&:JF^36U6@-D\"VBQ3,*V<+UP4(-O>CX?5^#*A]ZTNK@G, )TW\"^)<,=92?O!:",
"referenceOID": "4.19.5.89.7"
},
"Reference14": {
"%seriesCount": "1",
"referenceId": "Reference-425",
"referenceText": "<E;)F5#R0(VO)+_KQ?)D",
"referenceOID": "6.13.8.21.14"
},
"Reference15": {
"%seriesCount": "1",
"referenceId": "Reference-426",
"referenceText": "B32<\\BHZ0B<F5L-S\"Z1A6BJNO\\ZXH5LTY/Z[46O$8YR,. 5&[79M1E/GGC;U^(W+BZ5MA\\",
"referenceOID": "2.7.1.9.5"
},
"Reference2": {
"%seriesCount": "1",
"referenceId": "Reference-420",
"referenceText": "E /!QPU)=L&KX9Z*D",
"referenceOID": "5.9.1.51.0"
},
"Reference5": {
"%seriesCount": "1",
"referenceId": "Reference-421",
"referenceText": "7Y=2X(26]@1@V$.XQZ9:,!6PIU?RA\\HGL2';\\J;25X.E:E$638\\]NM([1E\\YQX?+?_I3.8'(&#IK84<_U",
"referenceOID": "7.1.9.43.17"
},
"Reference9": {
"%seriesCount": "1",
"referenceId": "Reference-422",
"referenceText": "XBM+OBE HMAG(>04\\:#=<3Y!I=\\8Y71->A&IH8?O28E3T1C+,%.+Z\"$GCY\"Y;GK$(C$[@-]@&L7X.Y+$SV& UW6AFF>J&S",
"referenceOID": "5.7.7.9.16"
}
}
}I haven't explored the XDATA mapping associated with %JSON nor investigated the other %JSON classes.
One solution if you were importing the json would be to pre-process the json string and remove the counter appended to the class name but that is a bit cludgy
Nigel
Hi
I have done some more experienting and in the Contact class I have a ContactPhoneNumbers which I defined as %ListOfDataTypes and I noticed that they were being generated but not exported to JSON so I changed the type to %ArrayOfDataTpes and that didn't work either. I played around with the %JSON attributes to no avail. I read the documentation on the %JSON.Adapter class and there are strict rules about Arrays and Lists must contain literals or objects and so I wrapped the Phone Numbers in quotes even though I was generating them as +27nn nnn nnn but that made no difference. I suspect that the Attribute ElementType should be set. In the ParentClass I specify that the array of object Oid's has an ElementType of %Persistent (the default is %RegisteredObject) and I think that I should do the same with the Phone Number array/list.
Nigel
And one more thing, I created the classes as %Persistent because I wanted to see the generated data and because I am referencing the Oid() in the array of Shcema's those classes has to be persistent as well.
Nigel
Hi
I should have included the class definition for Parent
Include DFIInclude Class DFI.Common.JSON.ParentClass Extends (%Persistent, %JSON.Adaptor, %XML.Adaptor, %ZEN.DataModel.Adaptor)
{ Property ParentId As %String(%JSONFIELDNAME = "parentId", %JSONIGNORENULL = 1, %JSONINCLUDE = "INOUT") [ InitialExpression = {"Parent"_$i(^Parent)} ];
Property ParentName As %String(%JSONFIELDNAME = "parentName", %JSONIGNORENULL = 1, %JSONINCLUDE = "INOUT") [ InitialExpression = {..ParentName()} ];
Property Schemas As %ArrayOfObjectsWithClassName(%JSONFIELDNAME = "schemas", %JSONIGNORENULL = 1, %JSONINCLUDE = "INOUT", CLASSNAME = 2, ELEMENTQUALIFIED = 1, REFELEMENTQUALIFIED = 1);
ClassMethod ParentName() As %String
{
quit "Example: "_$i(^Example)
}
ClassMethod BuildData(pCount As %Integer = 1) As %Status
{
set tSC=$$$OK
set array(1)="DFI.Common.JSON.Contact"
set array(2)="DFI.Common.JSON.Patient"
set array(3)="DFI.Common.JSON.Practitioner"
set array(4)="DFI.Common.JSON.Reference"
try {
for i=1:1:pCount {
set obj=##class(DFI.Common.JSON.ParentClass).%New()
set obj.Schemas.ElementType="%Persistent"
set count=$r(12)
for j=1:1:count {
set k=$r(4)+1
set schema=$classmethod(array(k),"%New"),tSC=schema.%Save() quit:'tSC do obj.Schemas.SetObjectAt(schema.%Oid(),$p(array(k),".",4)_"_"_j)
}
quit:'tSC
set tSC=obj.%Save() quit:'tSC
}
}
catch ex {set tSC=ex.AsStatus()}
write !,"Status: "_$s(tSC:"OK",1:$$$GetErrorText(tSC))
quit tSC
}
Nigel
Hi
I believe that I have a solution for this.
I worked on the basis that there is a 'Parent' object that has a property Schemas of type %ArrayOfObjectsWithClassName. This allows you to create an array of Objects where 'key' is the schema name and the 'id' is the instance.%Oid()
I then defined 4 classes:
Reference, Contact, Patient, Practitioner
I then created a method to Build N instances of the ParentClass. That code reads as follows:
ClassMethod BuildData(pCount As %Integer = 1) As %Status
{
set tSC=$$$OK
set array(1)="DFI.Common.JSON.Contact"
set array(2)="DFI.Common.JSON.Patient"
set array(3)="DFI.Common.JSON.Practitioner"
set array(4)="DFI.Common.JSON.Reference"
try {
for i=1:1:pCount {
set obj=##class(DFI.Common.JSON.ParentClass).%New()
set obj.Schemas.ElementType="%Persistent"
set count=$r(10)
for j=1:1:count {
set k=$r(4)+1
set schema=$classmethod(array(k),"%New"),tSC=schema.%Save() quit:'tSC
do obj.Schemas.SetObjectAt(schema.%Oid(),$p(array(k),".",4))
}
set tSC=obj.%Save() quit:'tSC
}
}
catch ex {set tSC=ex.AsStatus()}
write !,"Status: "_$s(tSC:"OK",1:$$$GetErrorText(tSC))
quit tSC
}
Initially I wanted to see if I could (a) insert different object types into the Array and (b) Export the Parent Object to JSON and so to make life easier I specified [ initialexpression = {some expression}] to generate a value for the field. Sort of like %Populate would do but I didn't want to pre-create instances in the 4 schema tables and then manually go and link them together.
When I ran my Method to create 10 Parents it created them and as you can see in the logic I generate a random number of schemas.
That all worked and I then exported to JSON to String resulting in this:
{"%seriesCount":"1","parentId":"Parent36","parentName":"Example: 38","schemas":{"Contact_1":{"%seriesCount":"1","contactGivenName":"Zeke","contactSurname":"Zucherro"},"Contact_11":{"%seriesCount":"1","contactGivenName":"Mark","contactSurname":"Nagel"},"Contact_3":{"%seriesCount":"1","contactGivenName":"Brendan","contactSurname":"King"},"Contact_8":{"%seriesCount":"1","contactGivenName":"George","contactSurname":"O'Brien"},"Patient_10":{"%seriesCount":"1","patientId":"PAT-000-251","patientDateOfBirth":"2021-05-05T03:38:33Z"},"Patient_2":{"%seriesCount":"1","patientId":"PAT-000-401","patientDateOfBirth":"2017-09-30T21:56:00Z"},"Patient_4":{"%seriesCount":"1","patientId":"PAT-000-305","patientDateOfBirth":"2019-04-19T14:04:11Z"},"Patient_5":{"%seriesCount":"1","patientId":"PAT-000-366","patientDateOfBirth":"2017-07-03T18:57:58Z"},"Patient_7":{"%seriesCount":"1","patientId":"PAT-000-50","patientDateOfBirth":"2016-11-26T03:39:36Z"},"Patient_9":{"%seriesCount":"1","patientId":"PAT-000-874","patientDateOfBirth":"2019-03-28T15:22:37Z"},"Practitioner_6":{"%seriesCount":"1","practitionerId":{"%seriesCount":"1","practitionerId":"PR0089","practitionerTitle":"Dr.","practitionerGivenName":"Angela","practitionerSurname":"Noodleman","practitionerSpeciality":"GP"},"practitionerIsActive":false}}}
Because I am using effectively an array of Objects the array is subscripted by 'key' and so if there are multiple instances of say "Patient" then each instance of "Patient" would over write the existing "Patient" in the array and so in creating the array I concatenated the counter 'j' to the Schema Name.
in object terms if you open an Instance of ParentClass and you use the GetAt('key') method on the Schemas array you will be returned with a full object Oid() and from that you can extract the ClassName and the %Id()
The only way I can see around not having to uniquely identify the 'Schema' %dynamicObject in the JSON string is in the Parent class you need to have an array for each schema type. i.e. Array of Patient, Array of Contact.
In terms of nesting you will see that Patient has a Practitioner and Practioner is linked to a Table of Practitioners and in the JSON above you can see that it picks up the Patient, Practitioner and the Practitioner Details from the Table Practitioners
I havent tried importing the JSON as I would have to remove all of the code that I put in the Schema classes to generate values if the field is NULL but that can be overcome by setting the attribute %JSONIGNORENULL to 0 and then make sure that you specify NULL for the property that has no value.
I would carry on experimenting but we are in the middle of a Power Cut (Thank you South African State Utility Company)
If you want to see the classes I wrote and play with them let me know and I'll email them as I can't upload them
Nigel
Hi
According to the documentation you can GRANT priveledges to a Class/Table and you can use a wildcard "*" for a collection of Classes/Tables
The documentation reference in the Ensemble documentation is:
http://localhost:57772/csp/docbook/DocBook.UI.Page.cls?KEY=RSQL_grant
and in the explanation there is an example:
GRANT object-privilege ON object-list TO grantee [WITH GRANT OPTION]
and further on the documentation says:
| object-list |
A comma-separated list of one or more tables, views, stored procedures, or cubes for which the object-privilege(s) are being granted. You can use the SCHEMA keyword to specify granting the object-privilege to all objects in the specified schema. You can use “*” to specify granting the object-privilege to all tables, or to all non-hidden Stored Procedures, in the current namespace. Note that a cubes object-list requires the CUBE (or CUBES) keyword, and can only be granted SELECT privilege. |
The full syntax is:
| grantee |
A comma-separated list of one or more users or roles. Valid values are a list of users, a list of roles, "*", or _PUBLIC. The asterisk (*) specifies all currently defined users who do not have the %All role. The _PUBLIC keyword specifies all currently defined and yet-to-be-defined users. |
| admin-privilege |
An administrative-level privilege or a comma-separated list of administrative-level privileges being granted. The list may consist of one or more of the following in any order: %CREATE_METHOD, %DROP_METHOD, %CREATE_FUNCTION, %DROP_FUNCTION, %CREATE_PROCEDURE, %DROP_PROCEDURE, %CREATE_QUERY, %DROP_QUERY, %CREATE_TABLE, %ALTER_TABLE, %DROP_TABLE, %CREATE_VIEW, %ALTER_VIEW, %DROP_VIEW, %CREATE_TRIGGER, %DROP_TRIGGER %DB_OBJECT_DEFINITION, which grants all 16 of the above privileges. %NOCHECK, %NOINDEX, %NOLOCK, %NOTRIGGER privileges for INSERT, UPDATE, and DELETE operations. |
| role | A role or comma-separated list of roles whose privileges are being granted. |
| object-privilege | A basic-level privilege or comma-separated list of basic-level privileges being granted. The list may consist of one or more of the following: %ALTER, DELETE, SELECT, INSERT, UPDATE, EXECUTE, and REFERENCES. You can confer all table and view privileges using either "ALL [PRIVILEGES]" or “*” as the argument value. Note that you can only grant SELECT privilege to CUBES. |
| object-list | A comma-separated list of one or more tables, views, stored procedures, or cubes for which the object-privilege(s) are being granted. You can use the SCHEMA keyword to specify granting the object-privilege to all objects in the specified schema. You can use “*” to specify granting the object-privilege to all tables, or to all non-hidden Stored Procedures, in the current namespace. Note that a cubes object-list requires the CUBE (or CUBES) keyword, and can only be granted SELECT privilege. |
| column-privilege | A basic-level privilege being granted to one or more listed columns. Available options are SELECT, INSERT, UPDATE, and REFERENCES. |
| column-list | A list of one or more column names, separated by commas and enclosed in parentheses. |
| table | The name of the table or view that contains the column-list columns. |
In IRIS look at the documentation at this link:
You can check priveledges with:
classmethod CheckPrivilege(Username As %String, ObjectType As %Integer, Object As %String, Action As %String, Namespace As %String = "") as %Boolean [ Language = objectscript ]
Check if user has SQL privilege for a particular action. This does not check grant privileges. Parameters:
Returns:
Notes:
and you can set Priveledges with
classmethod GrantPrivilege(ObjPriv As %String, ObjList As %String, Type As %String, User As %String) as %Status [ Language = objectscript ]
GrantPrivilege lets you grant an ObjPriv to a User via this call instead of using the SQL GRANT statement. This does not include grant privileges.
$SYSTEM.SQL.Security.GrantPrivilege(ObjPriv,ObjList,Type,User)
classmethod GrantPrivilegeWithGrant(ObjPriv As %String, ObjList As %String, Type As %String, User As %String) as %Status [ Language = objectscript ]
GrantPrivilegeWithGrant lets you grant an ObjPriv, WITH GRANT OPTION, to a User
$SYSTEM.SQL.Security.GrantPrivilegeWithGrant(ObjPriv,ObjList,Type,User)
Nigel
Hi
About a year ago while I was experimenting with IRIS for Health 2019.1 to see what advantages it would give us with the Enterprize Master Patient Index (EMCI) application that HST has been developing. HST had started developing this before IRIS for Health had been released and so they had created FHIR Classes based on the FIR STU3 specification. They created the FHIR classes as %Persistant classes and we use DTL's to convert a FHIR Patient JSON into the HST FHIR Patient class. The one issue we ran into was the Patient's picture which is a Binary Stream. The developer who was writing the UI using Outsystems was using ODBC to retrieve data from the FHIR classes and she was able to specify 'Picture' in her SQL queries and then pass the binary data through some render utility to get it to display correctly on the UI form however there is a restriction in ODBC that the max size for any column is 4000 bytes. In SQL Server the maximum size of a row of data is 8000 bytes and blobs are stored in separate structures from the main table. (Similar to our 'S' global in Cache Default Storage) so though Blobs can be up to 2GB in size you are still restricted if you intend to use ODBC to retrieve or update data in a table. The ODBC restriction is specific to the version of ODBC. Earlier versions of ODBC had a limit of 2000 bytes. This is irrespective of whether you are working with SQ Server, Oracle or IRIS ODBC drivers. In the documentation I was reading on SQL Server there are performance issues as well and they basically recommend keeping your binary or character stream data in files and they support a couple of techniques that allow their users to execute queries that include BLOB data but the SQL statements are hectic.
Hi
The reason I created this DTL was as follows: I had created an Interface that sent HL7 Messages to an HTTP Operation and provided the message reaches the target server it will respond with an HL7 ACK message (There HL7 HTTP server is working in the equivalent of 'ACK Immediate" mode as opposed to "application" mode. The OnRequest() method in my Business Process calls the HTTP Operation and then calls the FILE Operation. The HTTP Operation will return an HL7 ACK message and I process that in the OnResponse() method of the Business Process. The File Operation writes the HL7 Message, that I sent to the HTTP Operation, to file and by default thats all the File Operation will do but the reason I have the file operation at all is to simulate what should happen when i send the message to HTTP and so I generate an HL7 ACK message to return to the Business Process. That is why I have the DTL to transform the source HL7 Message into a corresponding HL7 ACK Message, and I think that I randomly generate a NACK code, again to be able to test what to do if I were to get an NACK code from the HL7 HTTP Operation. So back in my Business Process OnResponse method I have code to test the response HL7 ACK message and if there is an error I handle it.
With regards the question can it be used for any message structure. Strictly speaking, Yes because the source is an EnsLib.HL7.Message and the response is an EnsLib.HL7.Message and I basically copy the MSH from the source to the target, I swap the Sending and Receiving fields around and I think I generate a new timestamp. The message Control ID remains the same. Any fields that I need to change I pass in using the AUX object. I basically have an AUX class for ever DTL I create when ever I need some runtime value that is not part of the source message in the DTL so the Event Type of the MSH:MessageType is ACK and the Message Structure is just ACK. Then the Code and the Error Text if there is one are assigned in the MSA Segment. I have noticed a mistake in my DTL. When I create the HL7 message that I am sending to the external application the Message Structure is computed based on the Message Type and Trigger Event and I have a lookup table that maps the various Trigger Events to their base Message Structure. For instance an ADT_A08 where the Message Type i ADT and the Trigger Event is A08 then the Base Message Structure for an ADT_A08 is ADT_A01 and I have a method that I call in my business Process that determines the actual message structure from the Message Type and Trigger Event but that is not being called in the DTL so you will see that I am just assigning ACK to the Message structure where the assign should actually read "ACK"_target.{MSH:MessageType.TriggerEvent}
That would give you ACK_A08
Nigel
I think I should have my reply flagged as the accepted answer because I provided a reply that answered the question albeit in a slightly offbeat form but it explained the difference and why you would use $query rather than the other replies that just pointed to documentation. 😉😎👍
The "Trying embedded Python was great", Can't wait to try it out
Nigel
 (in
(in