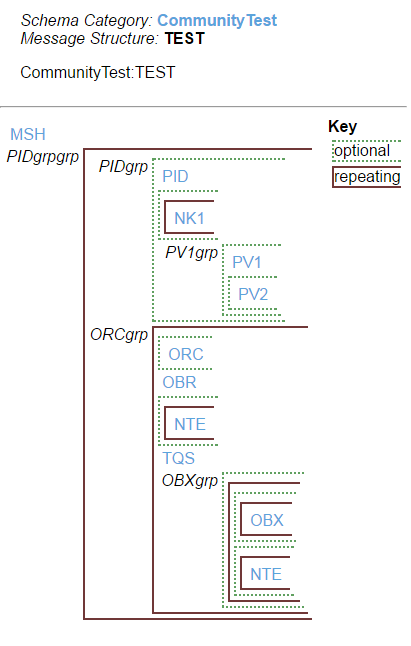
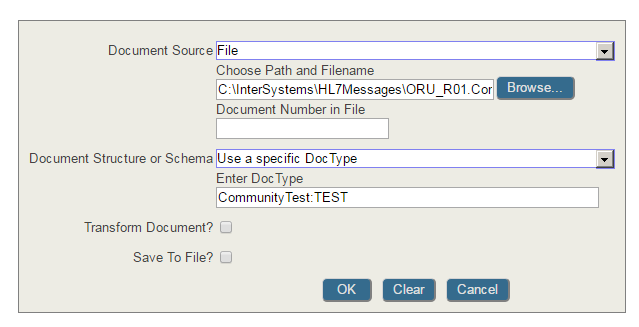
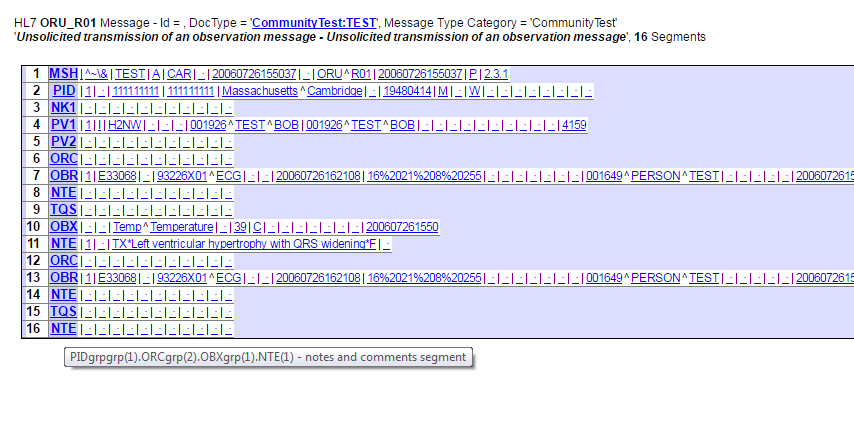
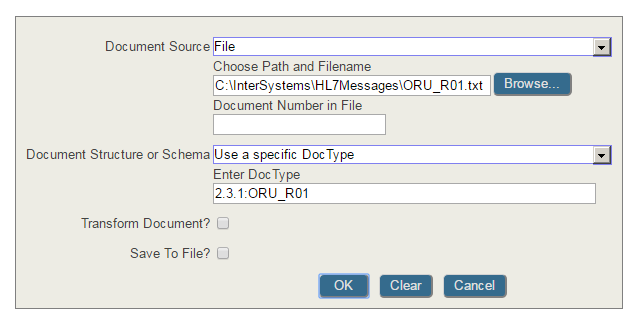
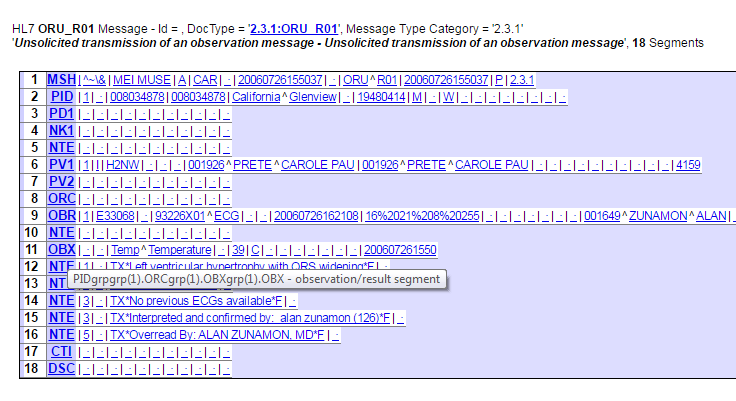
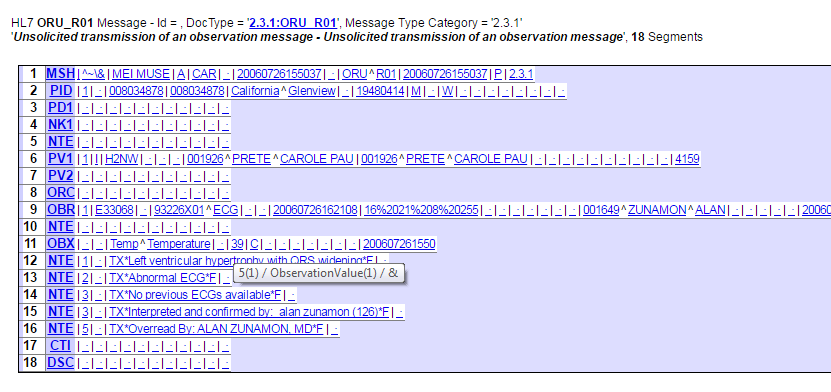
Ens.MessageHeader has a Status column. You may need to select on the name or its corresponding number depending on select mode. For example, status "Suspended" is 5. If selecting in display mode, use Status='Suspended' and in raw mode use Status=5 in your where clause.
The number for each status is defined in macros in EnsConstants.inc - the ones that start with eMessageStatus
- Log in to post comments