Using IRIS Interoperability and Data Transformation to Change Data in CSV
Hi developers!
Want to share with you an exercise I tried with InterSystems IRIS Interoperability.
The sample shows how to use IRIS Interoperability with data transformation component to change the data in CSV file.
The story is below.
I wanted to take a 100% transparent example and omit all the "magic" of Interoperability to see clearly what it does.
So the setting is 100% artificial. Consider we have a CSV file of temperature observations. CSV contains two columns: the 1st is day of observation(Integer), the 2nd is value of temperature in Fahrenheit (integer). The transformation takes such a file and changes Fahrenheit value to Celsius in all the lines and writes in a new CSV file.
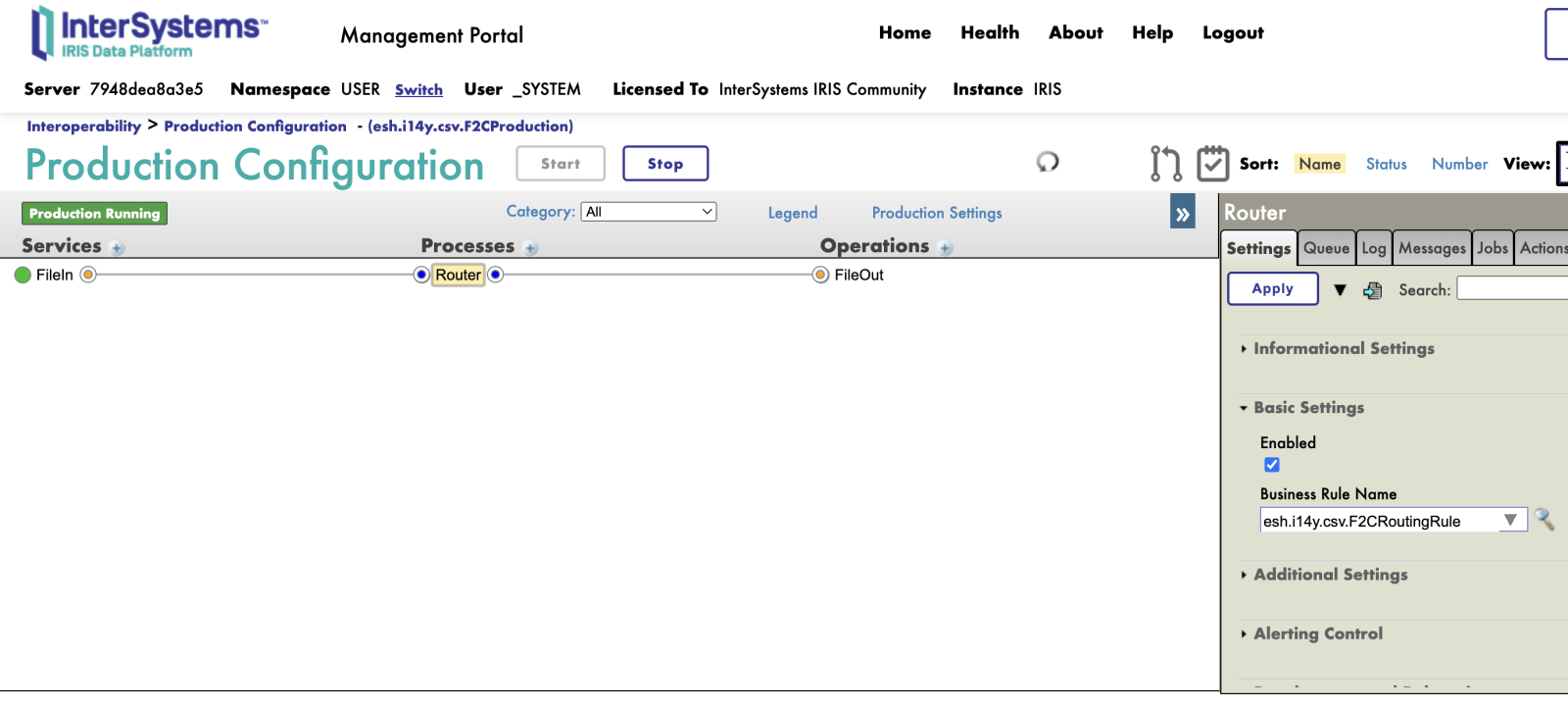
So the production will consist of business service of collecting files, data transformation class for F2C and business operation to create a new csv file.
Turned out that I also need to introduce a business rule or business process in order to implement data transformation. Data transformation for some reason cannot be an element of production by itself (but why? asked here).
Next question was what could be a message? Message in this case could contain the CSV file itself, or the line of the CSV. Message=file looks more productive and in a real life you'll always consider file than line to avoid Interoperability overhead. Every message is a persistent object and is being stored in database.
Here I decided to follow message=line approach to make messages and transformation the most clear (at least to me :).
BTW, even we call IRIS Interoperability a low code dev tool you need to code manually a message class for every interoperability production unless there is a special UI wizard.
For CSV transformations there is a wizard called CSV-Record-Mapper which you can use to create two things: 1 a message class to serve this particular CSV transformation and a supplementary class for an embedded Enslib.RecordMap.FileService business service class and EnsLib.RecordMap.Operation.FileOperation business operation, that I could use in production immediately to manage reading from CSV and writing to CSV respectfully.
So, if I want to work with e.g. JSON file transformation I need to create a message class manually. I'm not on this expert level yet.
Anyway, record mapper tool has the more or less clear to understand UI that helps you to deal what parts of CSV you want to work with.
You can find record mapper tool in Interoperability->Build->Record Maps.
This is how my record map looks like:

Start new and follow CSV Wizard, it is pretty obvious procedure.
Don't forget to export the results Record Mapper work into your working directory - there will be two classes at least - the class itself and the record message. You can export using source control via git-control package, or exporting classes via VSCode ObjectScript or via a command line.
Ok, then I've created a data transformation class via Data Transformation Builder (Interoperability->Build->Data Transformations):
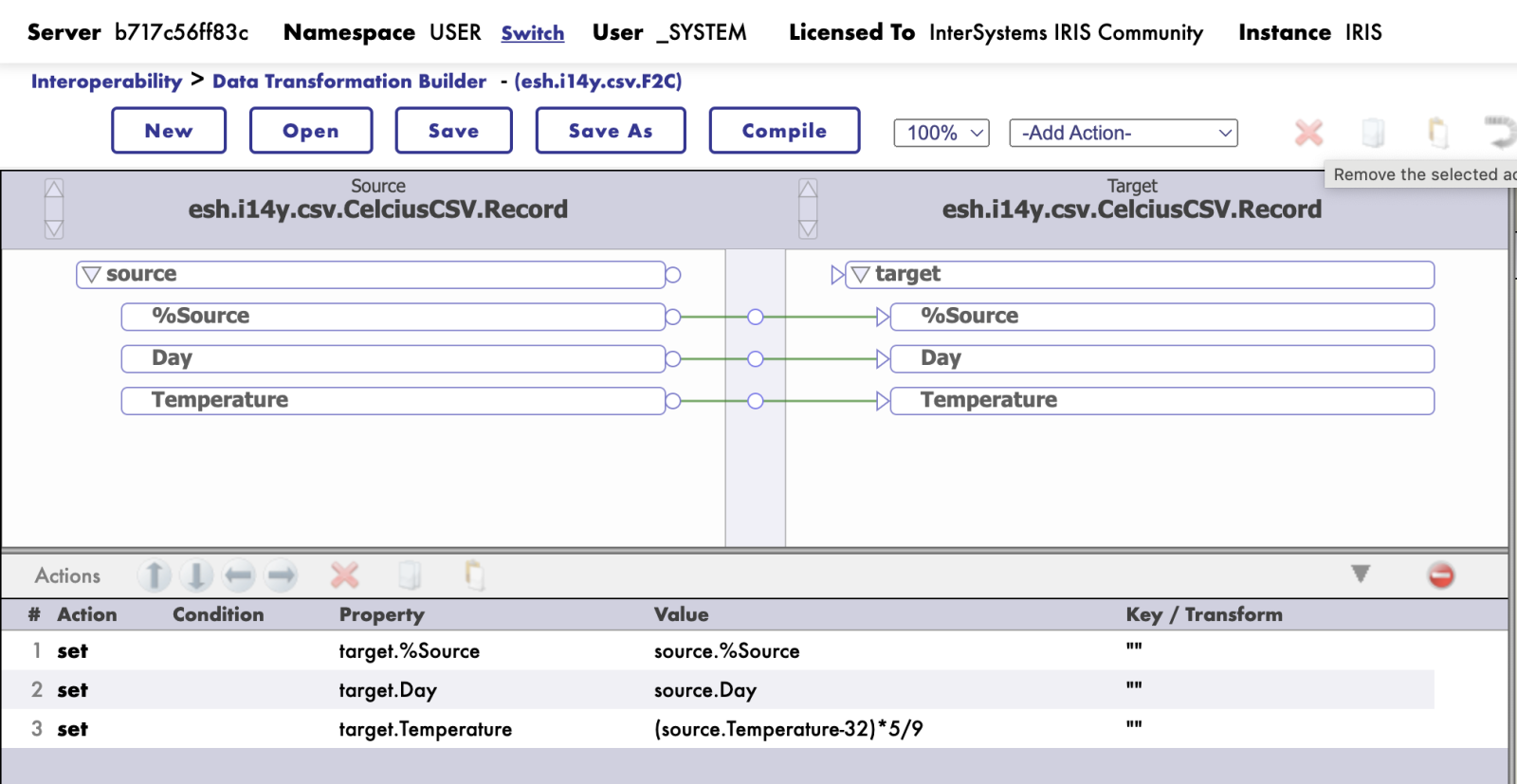
In any data transformation the task is to create a target side of the object in a shape you need in the destination.
in this case we had the same classes on source and target sides - CelciusCSV.Record, but the data will be transformed on a target side.
So I copied the data from Day field, and transformed the data in Temperature field to Celsius (according to formula taken from Internet (asked from ChatGPT ;)
Important thing here to note, that these classes are not simple classes, but descendants from Ens.Request, thus don't forget to transfer/copy %Source field in order to send further the metadata information.
Here is the resulted data transformation class.
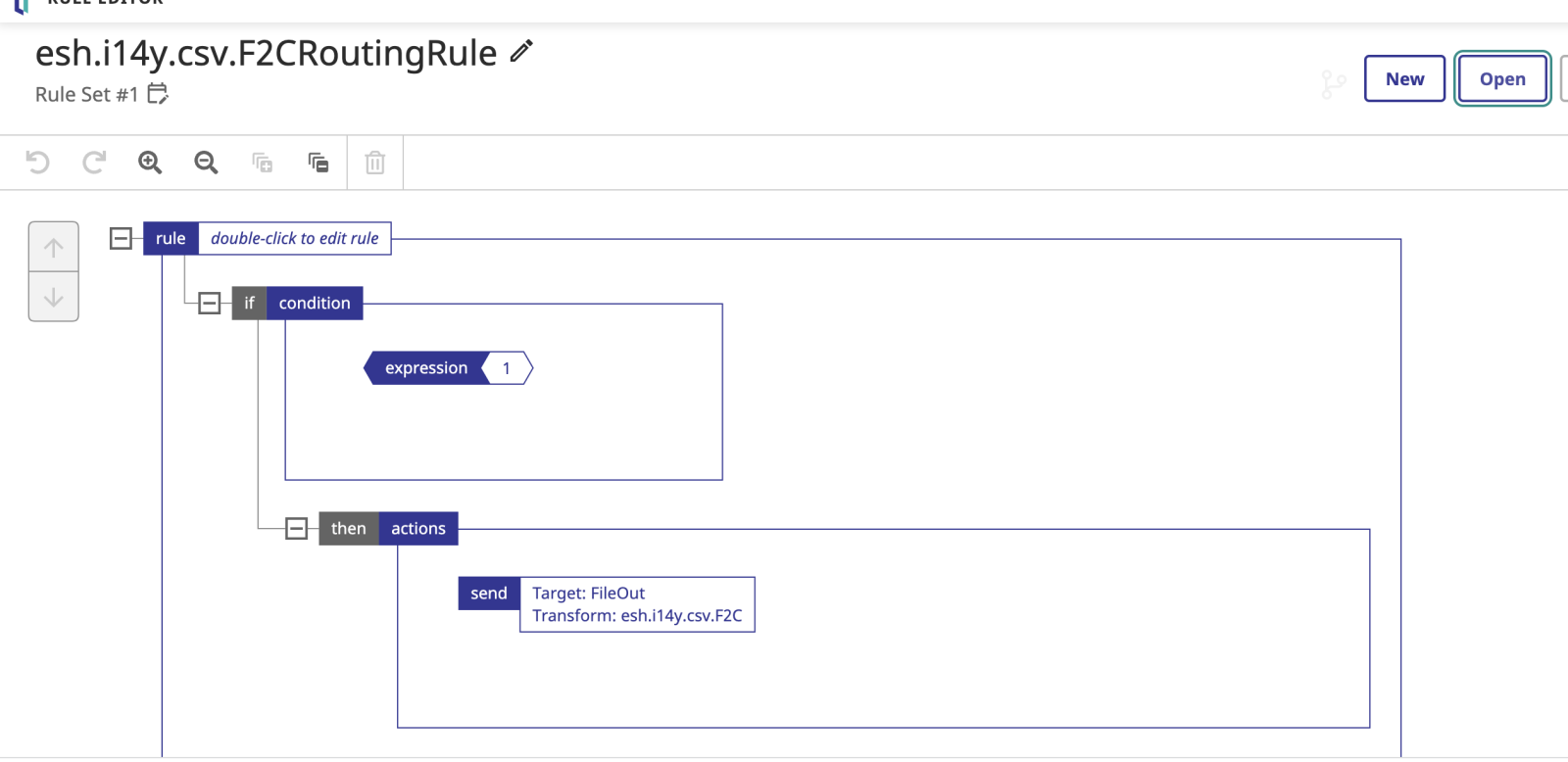
Next is "dumb" data rule. I need it only to make use of Data Transformation.
I created one with If condition that is always true. And in the body of the condition put action Send with transform action where I put a data-transformation with the target FileOut business operation.

NB: I use "old" data transformation editor here, as it has control-version feature. The new-one (Interoperability->Build->Business Rule) doesn't yet, but it has a new design and you can choose the Data Transformation.
Here is the resulted Business Rule class.
Same Rule class in the new editor (be aware, it doesn't support source control! You need to export changed rule manually!):
Now we have everything ready to build the production. Everything is pretty clear here:

1. I added a new Business service FileIn of embedded type: EnsLib.RecordMap.Service.FileService and put created esh.i14y.csv.CelciusCSV record map class as a parameter and /home/irisowner/irisdev/in as a files folder. And *.csv as files mask.
2. I added a business rule Router of embedded type EnsLib.MsgRouter.RoutingEngine where I placed esh.i14y.csv.F2CRoutingRule class as a parameter.
3. I added a business operation of embedded type EnsLib.RecordMap.Operation.FileOperation with:
esh.i14y.csv.CelciusCSV as a record map parameter,
/home/irisowner/irisdev/out as an out folder parameter
and '%f' as a file mask, which means that I want the output file have the same name as incoming one.
Here is the production class.
Make sure also that Target parameter for FileIn is Router and the Target parameter for Business Rule is FileOut
That's it!
Let's start the production and see how it works!
I suppose you launched it on a laptop so you have /home/irisowner/irisdev folder in a docker container. If not - adjust in and out folder parameters in FileIn and FileOut production components respectfully.
Place data.csv file from /data folder to /in folder in the repo (e.g. in VSCode). It will be deleted and processed by production and the resulted file data.csv with Celsius values could be found in /out folder.
Let's see how it all worked.
data.csv contains 3 records, so the production produces 3 messages in FileIn operation that are sent to Router rule. And Router sent 3 another messages to FileOut with data transformed to Celsius.
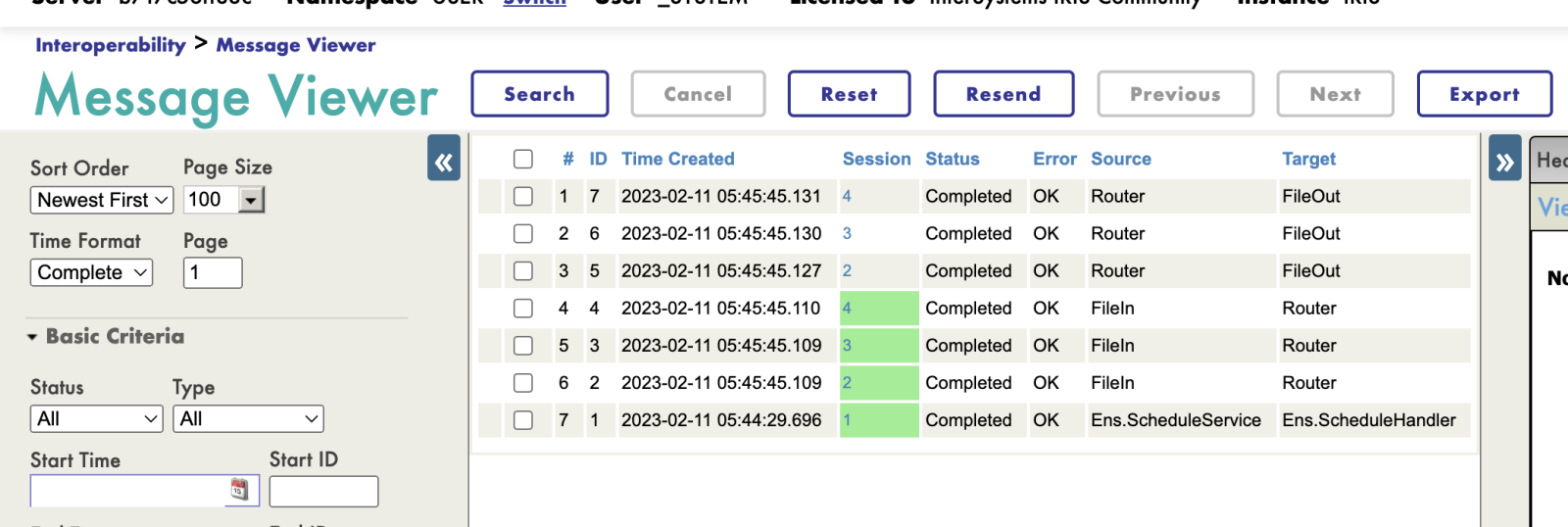
We can click on every message and check the data inside on every stage via Trace Route component:

So this is the end of the long read and my exercise with IRIS Interoperability and data transformation.
NB: No line of ObjectScript was written to create this production! All the elements were created via Low Code UI elements of IRIS Interoperability and because of great help of this community.
Questions not answered:
1. Why we need business process or business rule in order to perform the data transformation only?
2. How to make headers in the resulted CSV file (didn't find it in CSV Mapper settings)?
3. It is not clear how many parameters are in production elements that don't have the UI but are reflected in XML description?
E.g. here is the a piece of production FileIn:
<Item Name="FileIn" Category="" ClassName="EnsLib.RecordMap.Service.FileService" PoolSize="1" Enabled="true" Foreground="false" Comment="" LogTraceEvents="false" Schedule="">
<Setting Target="Host" Name="RecordMap">esh.i14y.csv.CelciusCSV</Setting>
<Setting Target="Adapter" Name="FilePath">/home/irisowner/irisdev/in</Setting>
<Setting Target="Adapter" Name="FileSpec">*.csv</Setting>
<Setting Target="Host" Name="TargetConfigNames">Router</Setting>
<Setting Target="Host" Name="HeaderCount">1</Setting>
</Item>Some of these parameters exist in UI and have different(!) names. E.g.'FileSpec' "Adapter" relates to 'File Spec' parameter. If I decide create productions manually via code in XML how can I know what parameters are available and which are "Host" and which are "Adapter"?
What could be the next steps?
1. Make a one file=one message interoperability with data transformation.
2. Try to perform the same with other than CSV data formats - e.g. JSON.
Thanks for your attention! The feedback is very welcome!
Comments
I have also reproduced this (before visiting this post) and created a production that reads in a .csv, transforms it, and then spits out one "file" for every record in the .csv. This is not a desirable output for me, i would like it to output all of the records in one .csv. Do you have any suggestions for that? Thank you, Mac Miller, Upper Peninsula Health Information Exchange
If the outbound operation is configured to use %f as the filename and has the Overwrite checkbox unchecked, the output file will have the same name and all records from the input file.
You mostly likely will have the input service and output operation set for different directories. Relying on the source file name may prove to be problematic if the inbound file has the same name every time it's received.
Hi Hugh!
In my case even the messages are csv lines they are being resulted in one csv file.
It is the matter of what file is pointed out in the outbound adapter, as @Jeffrey Drumm
mentioned. Take a look the code or try to run this production - it is in docker, so it is really easy to reproduce it on your laptop and see how it works.
Hi @Evgeny Shvarov and @Jeffrey Drumm !
A tremendous thank for steering me in the right direction! I feel i'm almost there. However, it looks like there is an error in the append phase of the production. See below. Any thoughts?
Best regards,
Mac

@Evgeny Shvarov @Jeffrey Drumm
i think it's got to do with one of my fields i'm trying to transform... i cut it down to two fields (first_name, last_name) and it worked fantastically!!!! Even had a timestamp :):)
The error in your previous post seems to indicate that no filename was available for creating or appending. The path shown in the error does not include a filename.