Parsing a HL7 message which contains LF characters in one field (OBX-5)
I have to write a DTL with the Data Transformation Builder to convert messages from HL7 ORU R01 v2.1 to HL7 ORU R01 v2.5. The incoming messages contain a text in OBX-5. This text contains LF characters (only LF - Segment separator is CR). Therefore it is not possible to parse the incoming message. While testing the transformation the OBX Segment ends at the first occurence of LF. Is there a way to replace the LF character before parsing?
example:
source:
OBX||FT|ltest1|| first line
second line
…
last line
||||||F|
target:
now: OBX||FT|ltest1|| first line
expected: OBX||FT|ltest1|| first line<br>secondline<br>….<br>lastline<br>||||||F|
Comments
I'm pretty sure you don't want a newline character anywhere in the target OBX segments, so this should do the trick:
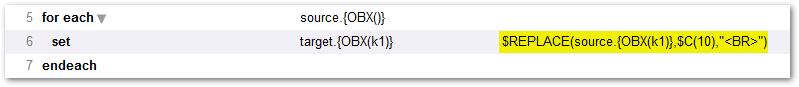
Unfortunately, this does not appear to do the right thing in the DTL Test tool. You can verify it works at the Caché/IRIS prompt, though:
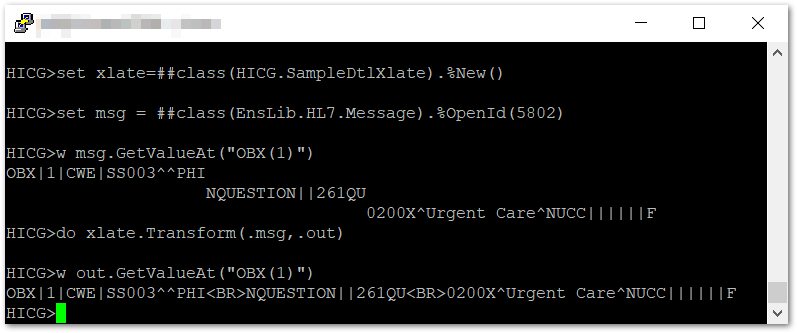
You can, of course, also verify that it works by calling it from a routing rule ![]()
I should also point out (after doing some additional experimentation) that this method works for individual fields as well:

Again, I should mention that what you see in the DTL Test facility does not represent what will happen in the transformation. I believe this is an artifact of the way the Windows clipboard handles EOL characters in a cut/paste operation.
Thank you Jeffrey! The hint concerning the DTL Test facility was indeed helpful because I have tried a lot of possibilties but I got not the expected result in the DTL Test facility.