LLM Models and RAG Applications Step-by-Step - Part III - Searching and Injecting Context
Welcome to the third and final publication of our articles dedicated to the development of RAG applications based on LLM models. In this final article, we will see, based on our small example project, how we can find the most appropriate context for the question we want to send to our LLM model and for this we will make use of the vector search functionality included in IRIS.

Vector searches
A key element of any RAG application is the vector search mechanism, which allows you to search within a table with records of this type for those most similar to the reference vector. To do this, it is necessary to first generate the embedding of the question that is going to be passed to the LLM. Let's take a look at our example project to see how we generate this embedding and use it to launch the query to our IRIS database:
model = sentence_transformers.SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
question = model.encode("¿Qué medicamento puede tomar mi hijo de 2 años para bajar la fiebre?", normalize_embeddings=True)
array = np.array(question)
formatted_array = np.vectorize('{:.12f}'.format)(array)
parameterQuery = []
parameterQuery.append(str(','.join(formatted_array)))
cursorIRIS.execute("SELECT distinct(Document) FROM (SELECT VECTOR_DOT_PRODUCT(VectorizedPhrase, TO_VECTOR(?, DECIMAL)) AS similarity, Document FROM LLMRAG.DOCUMENTCHUNK) WHERE similarity > 0.6", parameterQuery)
similarityRows = cursorIRIS.fetchall()As you can see, we instantiate the embedding generator model and vectorize the question that we are going to send to our LLM. Next, we launch a query to our LLMRAG.DOCUMENTCHUNK data table looking for those vectors whose similarity exceeds 0.6 (this value is entirely based on the product developer's criteria).
As you can see, the command used for the search is VECTOR_DOT_PRODUCT, but it is not the only option, let's take a look at the two options we have for similarity searches.
Dot Product (VECTOR_DOT_PRODUCT)
This algebraic operation is nothing more than the sum of the products of each pair of elements that occupy the same position in their respective vectors, represented as follows
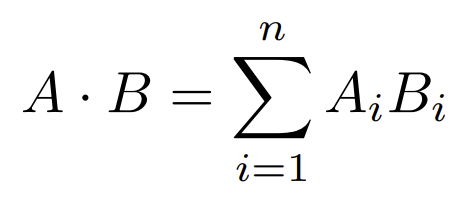
InterSystems recommends using this method when the vectors being worked on are unitary, that is, their modulus is 1. For those of you who are not familiar with algebra, the modulus is calculated as follows:

Cosine Similarity (VECTOR_COSINE)
This calculation represents the scalar product of the vectors divided by the product of their lengths and its formula is as follows:
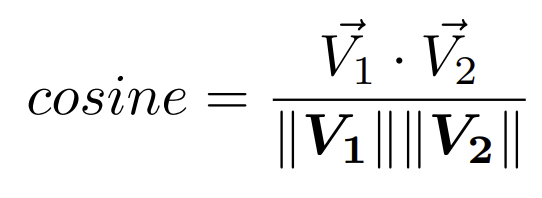
In both cases, the closer the result is to 1, the greater the similarity between the vectors
Context injection
With the query above we will obtain the texts that are related to the question that we will send to the LLM. In our case we are not going to send the text that we have vectorized since it is more interesting to send the entire document with the drug leaflet since the LLM model will be able to put together a much more complete response with the entire document. Let's take a look at our code to see how we are doing it:
for similarityRow in similarityRows:
for doc in docs_before_split:
if similarityRow[0] == doc.metadata['source'].upper():
context = context +"".join(doc.page_content)
prompt = hub.pull("rlm/rag-prompt")
rag_chain = (
{"context": lambda x: context, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("¿Qué medicamento puede tomar mi hijo de 2 años para bajar la fiebre?")Empezamos con un bucle for que nos recorrerá todos los registros vectorizados que son similares a la pregunta realizada. Como en nuestro ejemplo
We start with a for loop that will go through all the vectorized records that are similar to the question asked. As in our example we have the documents stored in the memory from the previous step of cutting and vectorizing, we have reused it in the second loop to extract the text directly. The best thing to do would be to access the document that we will have stored in our system without needing to use that second for loop.
Once the text of the documents that will form the context of the question has been stored in a variable, the next step will be to inform the LLM of the context of the question that we are going to pass to it. Once the context has been passed, we only need to send our question to the model. In this case, we want to know what medicines we can give our 2-year-old son to lower his fever. Let's look at the answers without context and with context:
Without context:
Fever in young children can be worrying, but it is important to manage it appropriately. For a 2-year-old, the most commonly recommended fever-reducing medications are paracetamol (acetaminophen) and ibuprofen.
With context:
Dalsy 40 mg/ml oral suspension, containing ibuprofen, can be used in children from 3 months of age for fever relief. The recommended dose for children 2 years of age depends on their weight and should be administered by prescription. For example, for a child weighing 10 kg, the recommended dose is 1.8 to 2.4 mL per dose, with a maximum daily dose of 7.2 mL (288 mg). Always consult a doctor before administering any medication to a child.
As you can see, when we do not have context the answer is quite generic, while with the appropriate context the answer is much more direct and indicates that it should always be under medical prescription
Conclusions
In this series of articles we have presented the fundamentals of RAG application development. As you can see, the basic concepts are quite simple, but as we know, the devil is always in the details. For every project, the following decisions need to be made:
- Which LLM model to use? On-premise or online service?
- Which embedding model should we use? Does it work correctly for the language we are going to use? Do we need to lemmatize the texts we are going to vectorize?
- How are we going to divide our documents for the context? By paragraph? By text length? With overlaps?
- Is our context based only on unstructured documents or do we have different data sources?
- Do we need to re-rank the results of the vector search with which we have extracted the context? And if so, what model do we apply?
- ...
Developing RAG applications involves more effort in validating results than in the actual technical development of the application. You must be very, very sure that your application does not provide erroneous or inaccurate answers, as this could have serious consequences, not only legal but also in terms of trust.