AWS Capacity planning review example
I am often asked to review customers' IRIS application performance data to understand if system resources are under or over-provisioned.
This recent example is interesting because it involves an application that has done a "lift and shift" migration of a large IRIS database application to the Cloud. AWS, in this case.
A key takeaway is that once you move to the Cloud, resources can be right-sized over time as needed. You do not have to buy and provision on-premises infrastructure for many years in the future that you expect to grow into.
Continuous monitoring is required. Your application transaction rate will change as your business changes, the application use or the application itself changes. This will change the system resource requirements. Planners should also consider seasonal peaks in activity. Of course, an advantage of the Cloud is resources can be scaled up or down as needed.
For more background information, there are several in-depth posts on AWS and IRIS in the community. A search for "AWS reference" is an excellent place to start. I have also added some helpful links at the end of this post.
AWS services are like Lego blocks, different sizes and shapes can be combined. I have ignored networking, security, and standing up a VPC for this post. I have focused on two of the Lego block components;
- Compute requirements.
- Storage requirements.
Overview
The application is a healthcare information system used at a busy hospital group. The architecture components I am focusing on here include two database servers in an InterSystems mirror failover cluster.
Sidebar: Mirrors are in separate availability zones for additional high availability.
Compute requirements
EC2 Instance Types
Amazon EC2 provides a wide selection of instance types optimised for different use cases. Instance types comprise varying FIXED combinations of CPU and memory and fixed upper limits on storage and networking capacity. Each instance type includes one or more instance sizes.
EC2 instance attributes to look at closely include:
- vCPU cores and Memory.
- Maximum IOPS and IO throughput.
For IRIS applications like this one with a large database server, two types of EC2 instances are a good fit:
- EC2 R5 and R6i are in the Memory Optimised family of instances and are an ideal fit for memory-intensive workloads, such as IRIS. There is 8GB memory per vCPU.
- EC2 M5 and M6i are in the General Purpose family of instances. There is 4GB memory per vCPU. They are used more for web servers, print servers and non-production servers.
Note: Not all instance types are available in all AWS regions. R5 instances were used in this case because the more recently released R6i was unavailable.
Capacity Planning
When an existing on-premises system is available, capacity planning means measuring current resource use, translating that to public cloud resources, and adding resources for expected short-term growth. Generally, if there are no other resource constraints, IRIS database applications scale linearly on the same processors; for example, imagine adding a new hospital to the group; increasing system use (transaction rate) by 20% will require 20% more vCPU resources using the same processor types. Of course, that's not guaranteed; validate your applications.
vCPU requirements
Before the migration, CPU utilisation peaked near 100% at busy times; the on-premises server has 26 vCPUs. A good rule of thumb is to size systems with an expected peak of 80% CPU utilisation. This allows for transient spikes in activity or other unusual activity. An example CPU utilisation chart for a typical day is shown below.
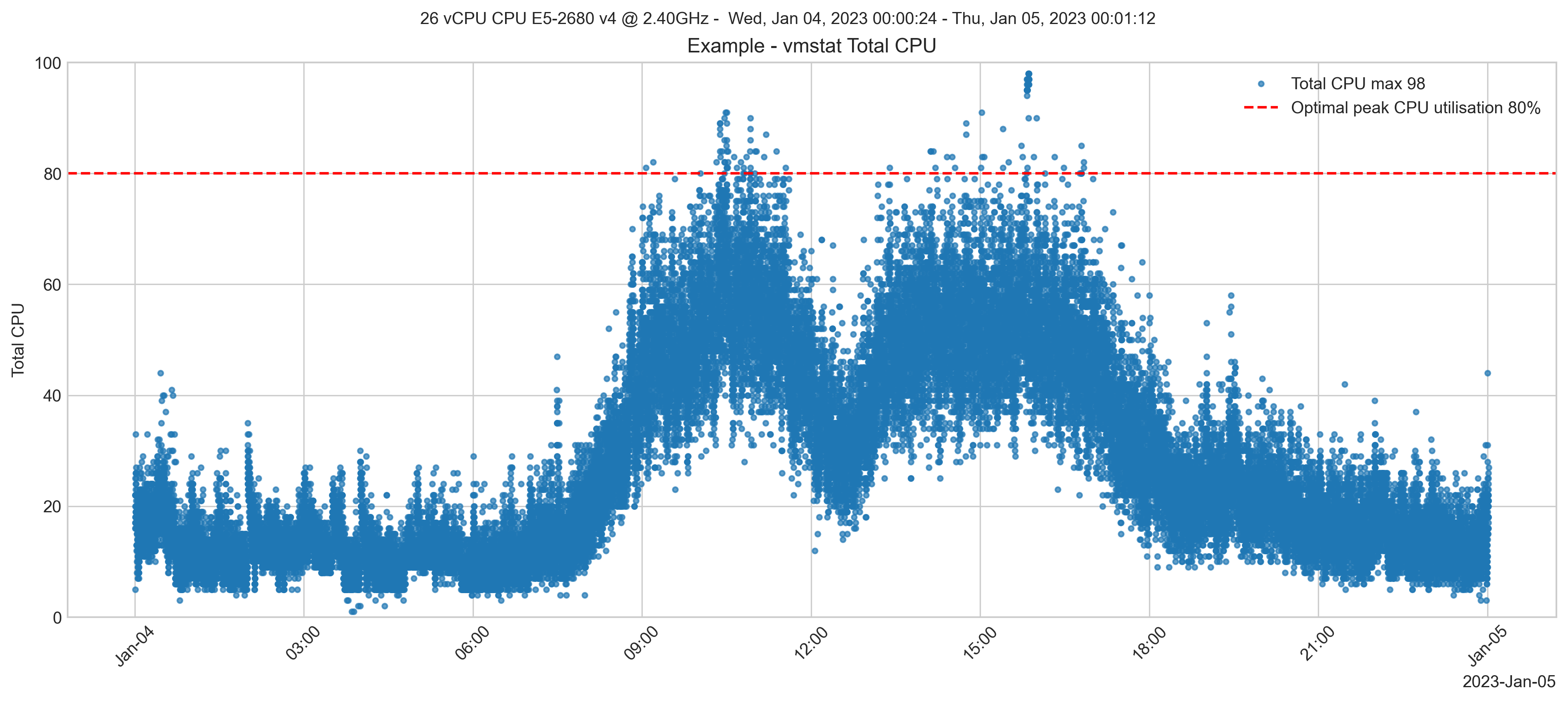
Monitoring the on-premises servers would prompt an increase in vCPUs to 30 cores to bring general peak utilisation below 80%. The customer was anticipating adding 20% transaction growth in the short term. So, a 20% buffer is added to the calculations, also allowing some extra headroom for the migration period.
A simple calculation is that 30 cores + 20% growth and migration buffer is 36 vCPU cores required.
Sizing for the cloud
Remember, AWS EC2 instances in each family type come in fixed sizes of vCPU and memory and set upper limits on IOPS, storage, and network throughput.
For example, available instance types in the R5 and R6i families include:
- 16 vCPUs and 128GB memory
- 32 vCPUs and 256 GB memory
- 48 vCPUs and 384 GB memory
- 64 vCPUs and 512 GB memory
- And so on.
Rule of thumb: A simplified way to size an EC2 instance from known on-premises metrics to the cloud is to round up the recommended on-premises vCPU requirements to the next available EC2 instance size.
Caveats: There can be many other considerations; for example, differences in on-premises and EC2 processor types and speeds, or having more performant storage in the cloud than an old on-premises system, can mean that vCPU requirements change, for example, more IO and more work can be done in less time, increasing peak vCPU utilisation. On-premises servers may have a full CPU processor, including hyper-threading, while cloud instance vCPUs are a single hyper thread. On the other hand, EC2 instances are optimised to offload some processing to onboard Nitro cards allowing the main vCPU cores to spend more cycles processing workloads, thus delivering better instance performance. But, in summary, the above rule is a good guide to start. The advantage of the cloud is that with continuous monitoring, you can plan and change the instance type to optimise performance and cost.
For example, to translate 30 or 36 vCPUs on-premises to similar EC2 instance types:
- The r5.8xlarge has 32 vCPUs, 256 GB memory and a maximum of 30,000 IOPS.
- The r512xlarge has 48 vCPUs, 384 GB memory and a maximum of 40,000 IOPS
Note the maximum IOPS. This will become important later in the story.
Results
An r512xlarge instance was selected for the IRIS database mirrors for the migration.
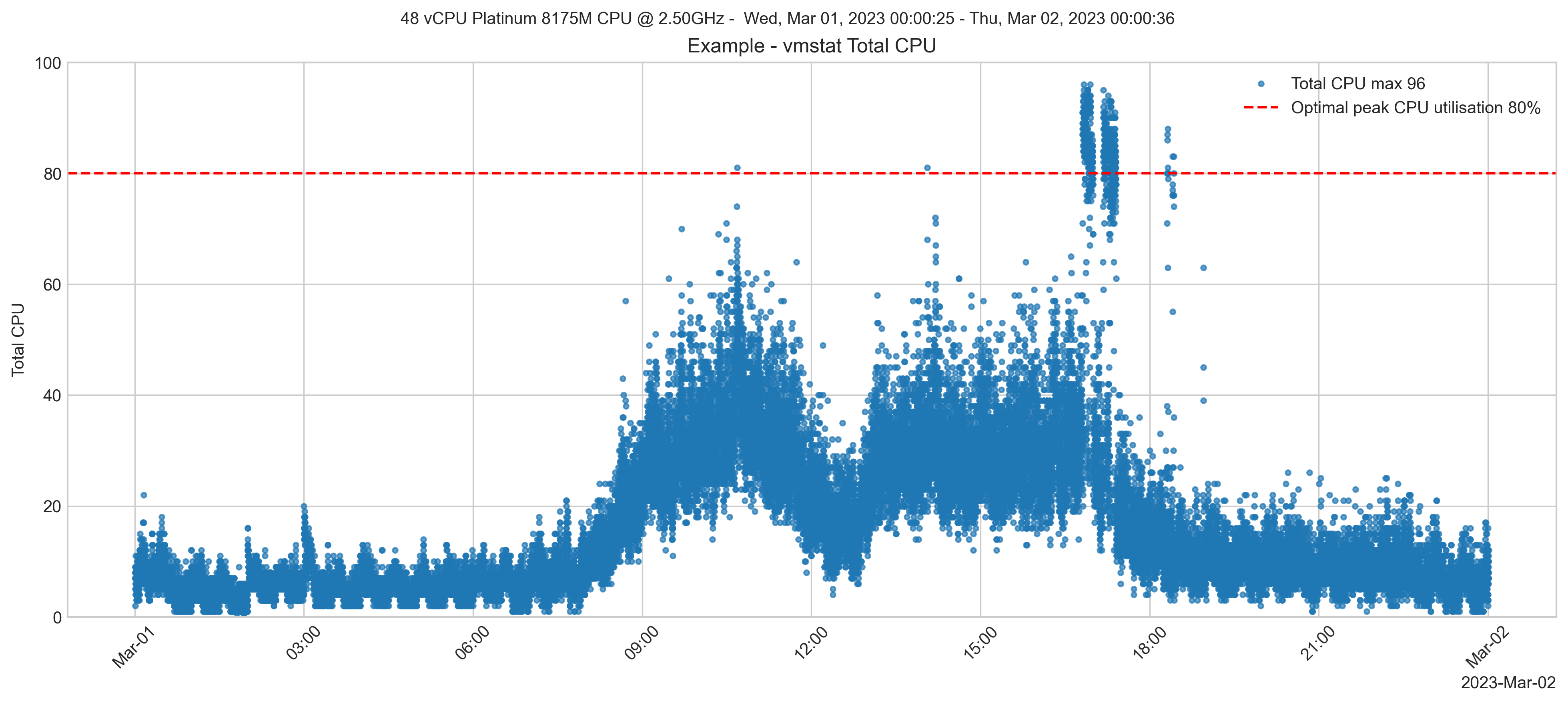
In the weeks after migration, monitoring showed the 48 vCPU instance type with sustained peaks near 100% vCPU utilisation. Generally, though, the processing peaked at around 70%. Well within the acceptable range, and if the periods of high utilisation can be traced to a process that can be optimised, there is plenty of headroom to consider right-sizing to a lower specification and cheaper EC2 instance type.
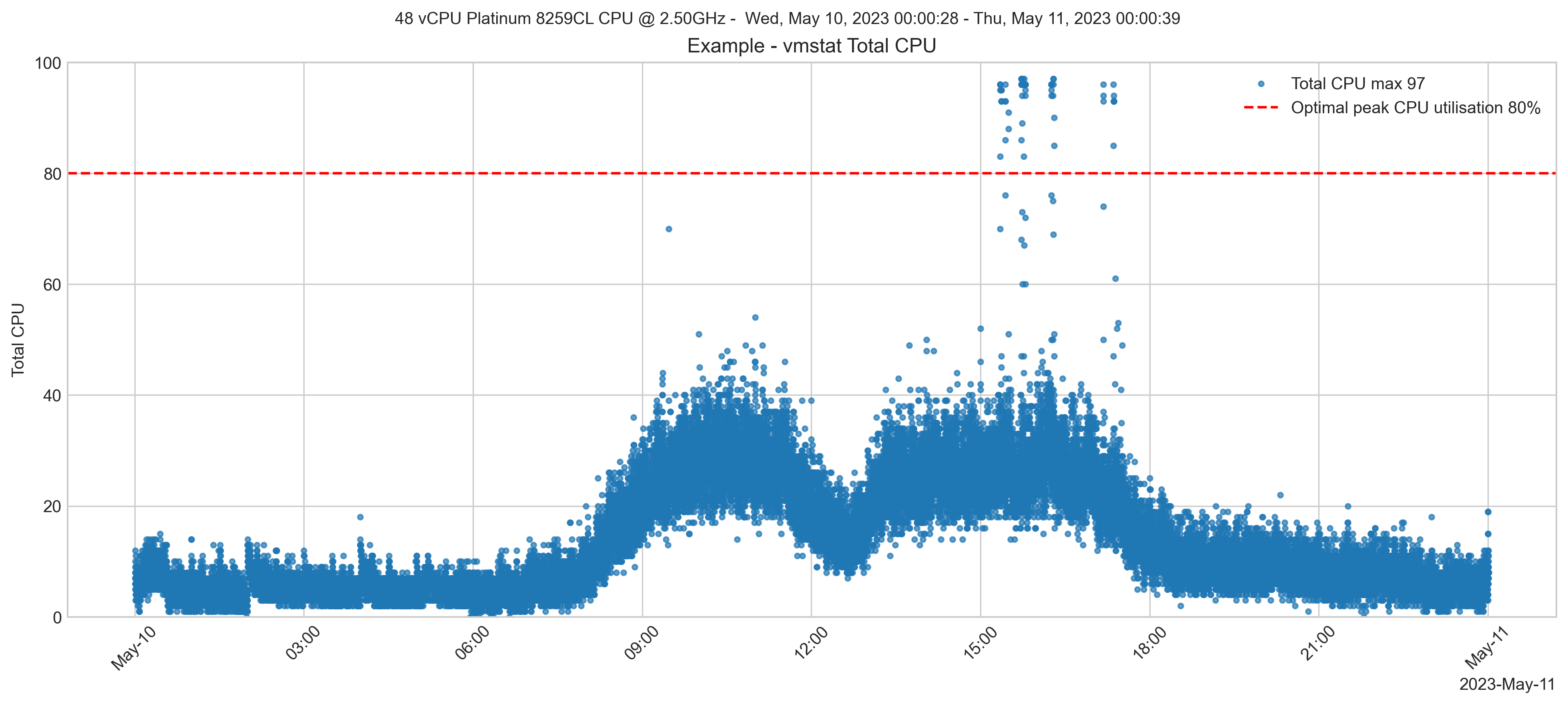
Sometime later, the instance type remained the same. A system performance check shows that the general peak vCPU utilisation has dropped to around 50%. However, there are still transient peaks near 100%.
Recommendation
Continuous monitoring is required. With constant monitoring, the system can be right-sized to achieve the necessary performance and be cheaper to run.
The transient spikes in vCPU utilisation should be investigated. For example, a report or batch job may be moved out of business hours, lowering the overall vCPU peak and lessening any adverse impact on interactive application users.
Review the storage IOPS and throughput requirements before changing the instance type; remember, instance types have fixed limits on maximum IOPS.
Instances can be right-sized by using failover mirroring. Simplified steps are:
- Power off the backup mirror.
- Power on the backup mirror using a smaller or larger instance with configuration changes to mount the EBS storage and account for a smaller memory footprint (think about things like Linux hugepages and IRIS global buffers).
- Let the backup mirror catch up.
- Failover the backup mirror to become primary.
- Repeat, resize the remaining mirror, return it online, and catch up.
Note: During the mirror failover, there will be a short outage for all users, interfaces, etc. However, if ECP application servers are used, there can be no interruption to users. Application servers can also be part of an autoscaling solution.
Other cost-saving options include running the backup mirror on a smaller instance. However, there is a significant risk of reduced performance (and unhappy users) if a failover occurs at peak processing times.
Caveats: Instance vCPU and memory are fixed. Restarting with a smaller instance with a smaller memory footprint will mean a smaller global buffer cache, which can increase the database read IOPS. Please take into account the storage requirements before reducing the instance size. Automate and test rightsizing to minimise the risk of human error, especially if it is a common occurrence.
Storage requirements
Predictable storage IO performance with low latency is vital to provide scalability and reliability for your applications.
Storage types
Amazon Elastic Block Store (EBS) storage is recommended for most high transaction rate IRIS database applications. EBS provides multiple volume types that allow you to optimise storage performance and cost for a broad range of applications. SSD-backed storage is required for transactional workloads such as applications using IRIS databases.
Of the SSD storage types, gp3 volumes are generally recommended for IRIS databases to balance price and performance for transactional applications; however, for exceptional cases with very high IOPS or throughput, io2 can be used (typically for a higher cost). There are other options, such as locally attached ephemeral storage and third-party virtual array solutions. If you have requirements beyond io2 capabilities, talk to InterSystems about your needs.
Storage comes with limits and costs, for example;
- gp3 volumes deliver a baseline performance of 3,000 IOPS and 125 MiBps at any volume size with single-digit millisecond latency 99% of the time for the base cost of the storage GB capacity. gp3 volumes can scale up to 16,000 IOPS and 1,000 MiBps throughput for an additional cost. Storage is priced per GB and on provisioned IOPS over the 3,000 IOPS baseline.
- io2 volumes deliver a consistent baseline performance of up to 500 IOPS/GB to a maximum of 64,000 IOPS with single-digit millisecond latency 99.9% of the time. Storage is priced per GB and on provisioned IOPS.
Remember: EC2 instances also have limits on total EBS IOPS and throughput. For example, the r5.8xlarge has 32 vCPUs and a maximum of 30,000 IOPS. Not all instance types are optimised to use EBS volumes.
Capacity Planning
When an existing on-premises system is available, capacity planning means measuring current resource use, translating that to public cloud resources, and adding resources for expected short-term growth.
The two essential resources to consider are:
- Storage capacity. How many GB of database storage do you need, and what is the expected growth? For example, you know your on-premises system's historical average database growth for a known transaction rate. In that case, you can calculate future database sizes based on any anticipated transaction rate growth. You will also need to consider other storage, such as journals.
- IOPS and throughput. This is the most interesting and is covered in detail below.
Database requirements
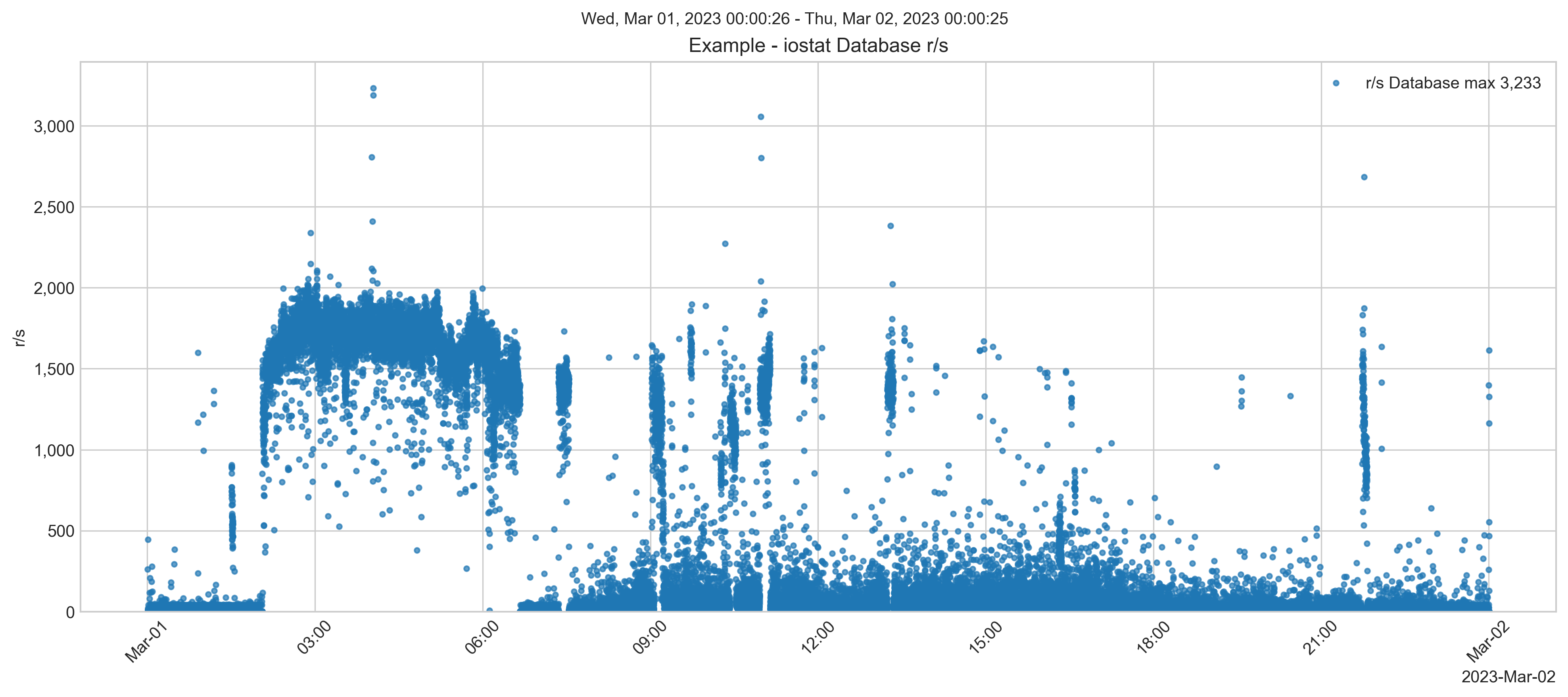
Before the migration, database disk reads were peaking at around 8,000 IOPS.

Read plus Write IOPS was peaking above 40,000 on some days. Although, during business hours, the peaks are much lower.
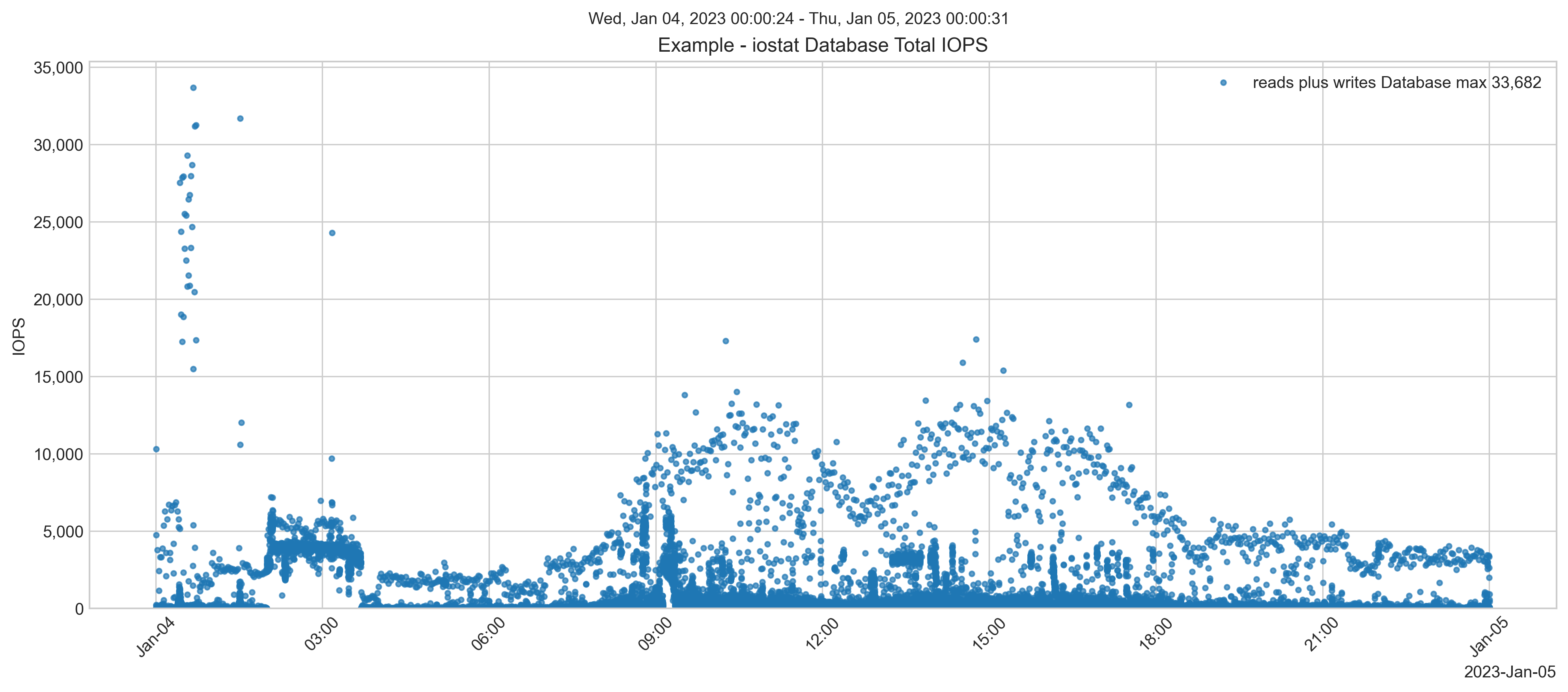
The total throughput of reads plus writes was peaking at around 600 MB/s.
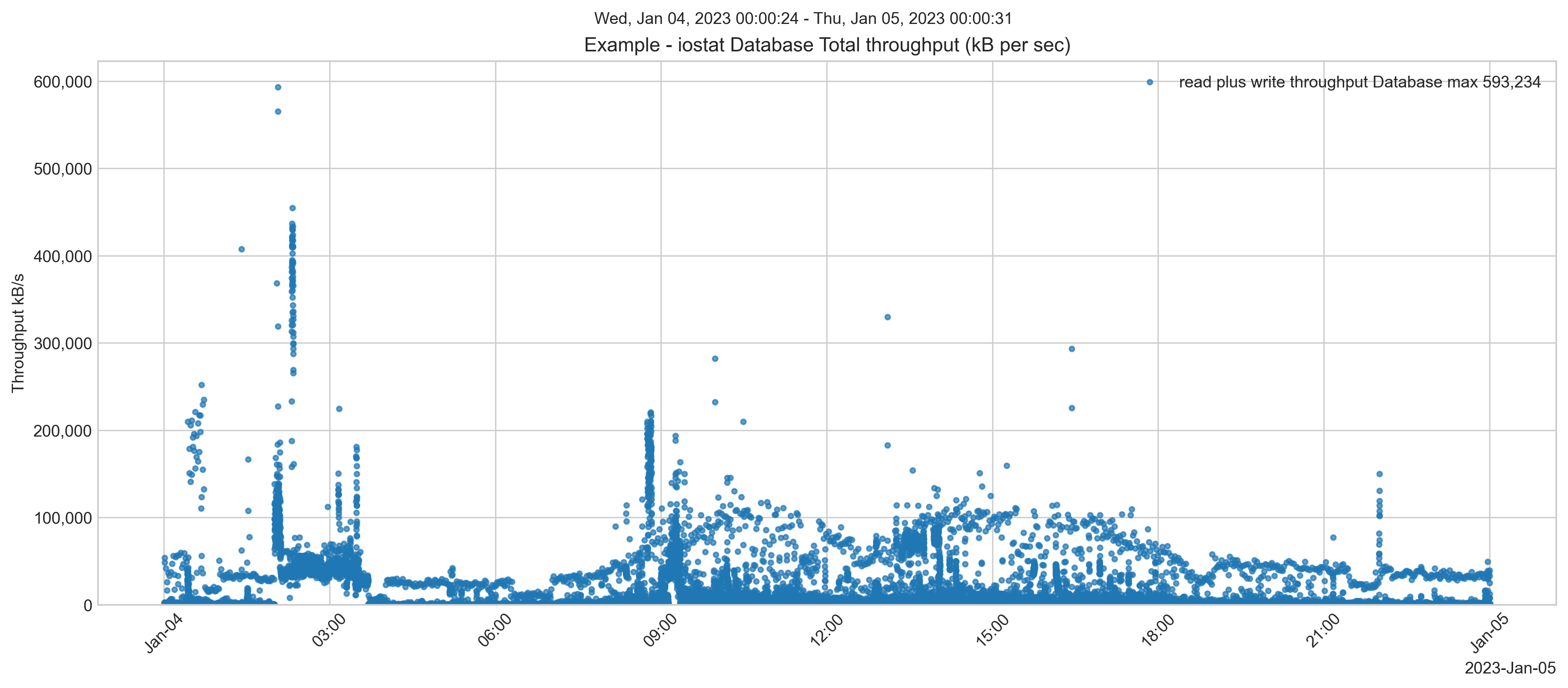
Remember, EC2 instances and EBS volumes have limits on IOPS AND throughput. Whichever limit is reached first will result in the throttling of that resource by AWS, causing performance degradation and likely impacting the users of your system. You must provision IOPS AND throughput.
Sizing for the cloud
For a balance of price and performance, gp3 volumes are used. However, in this case, the limit of 16,000 IOPS for a single gp3 volume is exceeded, and there is an expectation that requirements will increase in the future.
To allow for the provisioning of higher IOPS than is possible on a single gp3 volume, an LVM stripe is used.
For the migration, the database is deployed using an LVM stripe of four gp3 volumes with the following:
- Provisioned 8,000 IOPS on each volume (for a total of 32,000 IOPS).
- Provisioned throughput of 250 MB/s on each volume (for a total of 1,000 MB/s).
The exact capacity planning process was done for the Write Image Journal (WIJ) and transaction journal on-premises disks. The WIJ and journal disks were each provisoned on a single gp3 disk.
For more details and an example of using an LVM stripe, see: https://community.intersystems.com/post/using-lvm-stripe-increase-aws-ebs-iops-and-throughput
Rule of thumb: If your requirements exceed the limits of a single gp3 volume, investigate the cost difference between using LVM gp3 and io2 provisioned IOPS.
Caveats: Ensure the EC2 instance does not limit IOPS or throughput.
Results
In the weeks after migration, database write IOPS peaked at around 40,000 IOPS, similar to on-premises. However, the database reads IOPS were much lower.
Lower read IOPS is expected due to the EC2 instance having more memory available for caching data in global buffers. More application working set data in memory means it does not have to be called in from much slower SSD storage. Remember, the opposite will happen if you reduce the memory footprint.
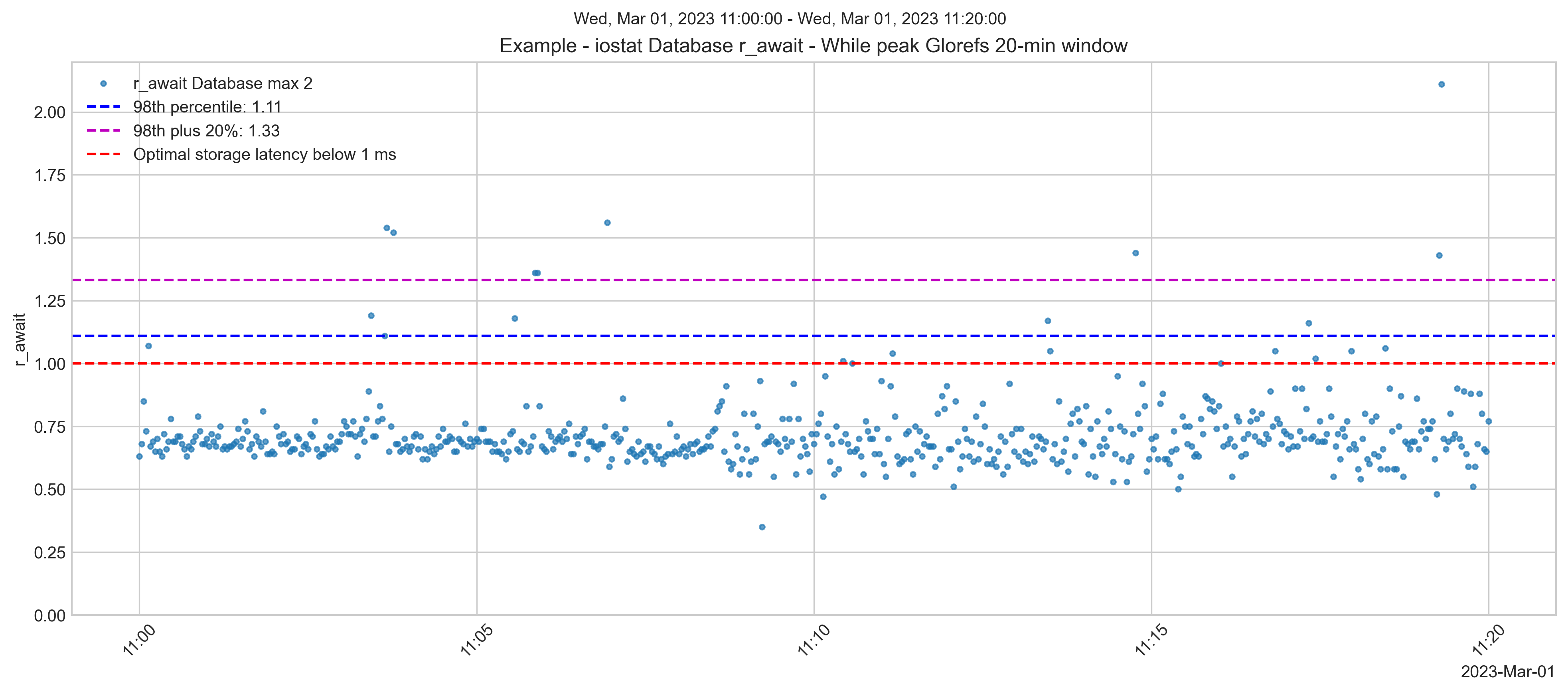
During peak processing times, the database volume had spikes above 1 ms latency. However, the spikes are transient and will not impact the user's experience. Storage performance is excellent.
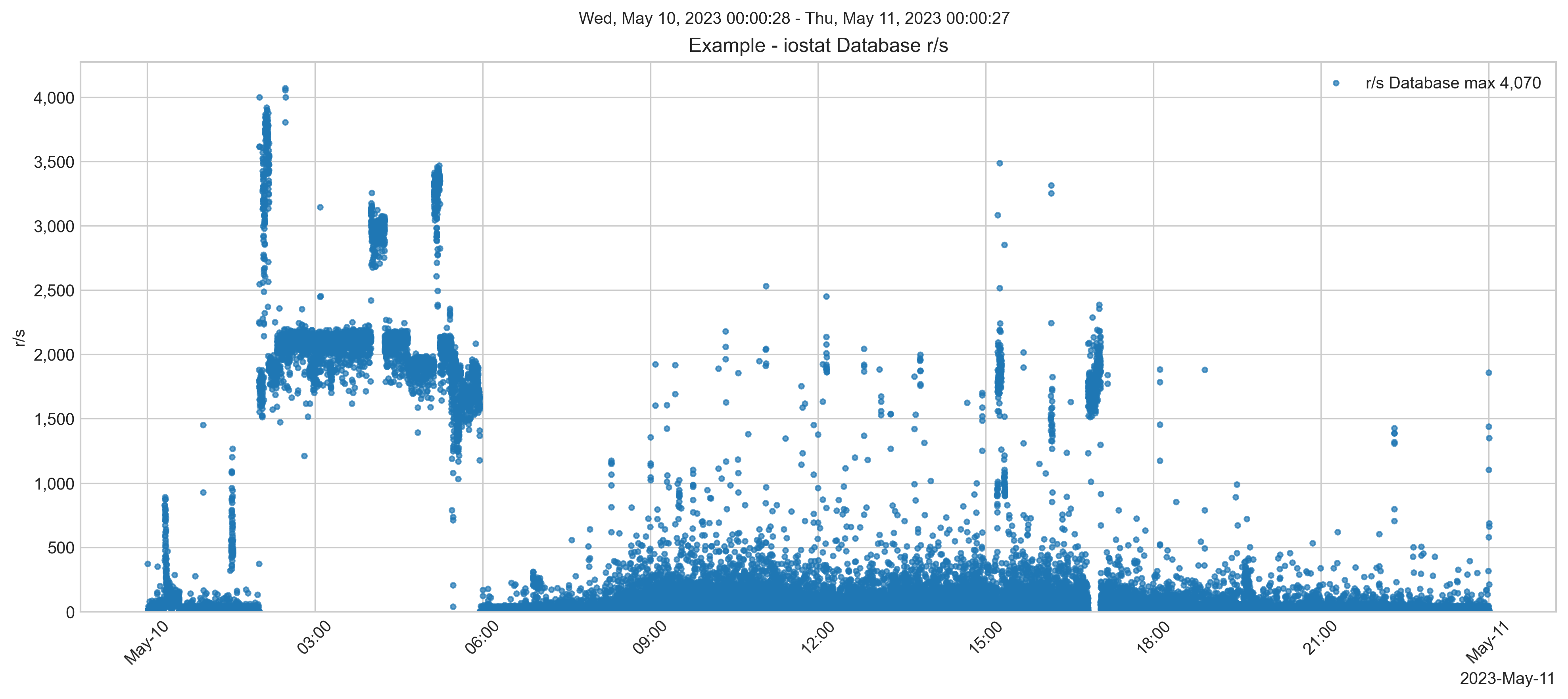
Later, a system performance check shows that although there are some peaks, generally, read IOPS is still lower than on-premises.
Recommendation
Continuous monitoring is required. With constant monitoring, the system can be right-sized to achieve the necessary performance and be cheaper to run.
An application process responsible for the 20 minutes of high overnight database write IOPS (chart not shown) should be reviewed to understand what it is doing. Writes are not affected by large global buffers and are still in the 30-40,000 IOPS range. The process could be completed with lower IOPS provisioning. However, there will be a measurable impact on database read latency if the writes overwhelm the IO path, adversely affecting interactive users. Read latency must be monitored closely if reads are throttled for an extended period.
The database disk IOPS and throughput provisioning can be adjusted via AWS APIs or interactively via the AWS console. Because four EBS volumes comprise the LVM disk, the IOPS and throughput attributes of the EBS volumes must be adjusted equally.
The WIJ and journal should also be continuously monitored to understand if any changes can be made to the IOPS and throughput provisioning.
Note: The WIJ volume has high throughput requirements (not IOPS) due to the 256 kB block size. WIJ volume IOPS may be under the baseline of 3,000 IOPS, but throughput is currently above the throughput baseline of 125 MB/s. Additional throughput is provisioned in the WIJ volume.
Caveats: Decreasing IOPS provisioning to throttle the period of high overnight writes will result in a longer write daemon cycle (WIJ plus random database writes). This may be acceptable if the writes finish within 30-40 seconds. However, there may be a severe impact on read IOPS and read latency and, therefore, the experience of interactive users on the system for 20 minutes or longer. Please be sure to proceed with caution.
Helpful links
- Charts are created with "yaspe" https://community.intersystems.com/post/yaspe-yet-another-system-performance-extractor
AWS
- Details of AWS Elastic Cloud Computing (EC2) can be found here: https://aws.amazon.com/ec2/
- Details of AWS Elastic Block Store (EBS) can be found here: https://aws.amazon.com/ebs/
Comments
Excellent article!
A note for people using Kubernetes or Containers in the cloud: This same advice applies for Kubernetes-based and containers-based deployments. When you create a Kubernetes cluster you assign VM resources (NodeGroups, for example) and you'll want to use the advice in this article to create the right nodes and storageclass for your deployment.