InterSystems IRIS provides a complete application development environment for building sophisticated data- and analytics-intensive applications that connect data and application silos. It is designed to work with all of the common development technologies in an open, standards-based fashion and supports both server-side and client-side programming.
InterSystems IRIS supports server-side application development with both Python and InterSystems ObjectScript. InterSystems IRIS also supports client-side development using many popular development technologies, including Java, C#/.NET, Node.js, Python, and ObjectScript.
The purpose of this article will be to focus on client-side development using a popular environment, the .NET development environment.
The ADO.NET Managed Provider, NET Native SDK, XEP API, and the Entity Framework Provider are a set of powerful APIs that combine to cover your bases regarding client-side InterSystems IRIS data platform development by leveraging the .NET framework.
ADO.NET Managed Provider
The ADO.NET Managed Provider is the InterSystems implementation of the ADO.NET data access interface, which will enable connection to IRIS from your .NET application, enabling the use of SQL queries to access data. The other three APIs use this underlying connection protocol.
.NET Native SDK
The .NET Native SDK will provide direct access to InterSystems IRIS objects, globals, and ObjectScript functionality, such as running classes and routines. Directly accessing globals, the fundamental storage structure for data in IRIS, can speed up data retrieval for your .NET application.
XEP API
The XEP API will facilitate high-speed access to InterSystems objects. This is most useful when working with high throughput objects with low to medium complexity.
The Entity Framework Provider and Object Relational Mapping (ORM)
The Entity Framework Provider is the InterSystems implementation of the Entity Framework, the object-relational mapping for ADO.NET.
- What is Object-Relational Mapping or ORM?
- A technique that lets you query and manipulate data from a database using an object-oriented paradigm. These techniques are often implemented as libraries, such as the SQLAlchemy library for Python.
- If you're drawing a blank thinking of the equivalent library that implements ORM in IRIS, you should be. IRIS can be treated as a relational database (you can use SQL queries to query data stored in IRIS), so there is no need for a library implementing ORM techniques when ORM is built into the platform itself.
.NET developers can leverage any of these APIs alone or in conjunction with the stipulation of requiring the InterSystems.Data.IRISClient.dll assembly file to be referenced in their .NET project. Each API has its pros and cons, but a measured use of each one's capabilities provides a balanced approach to developing on the InterSystems IRIS data platform with the .NET Framework.
 Open Exchange
Open Exchange.png)

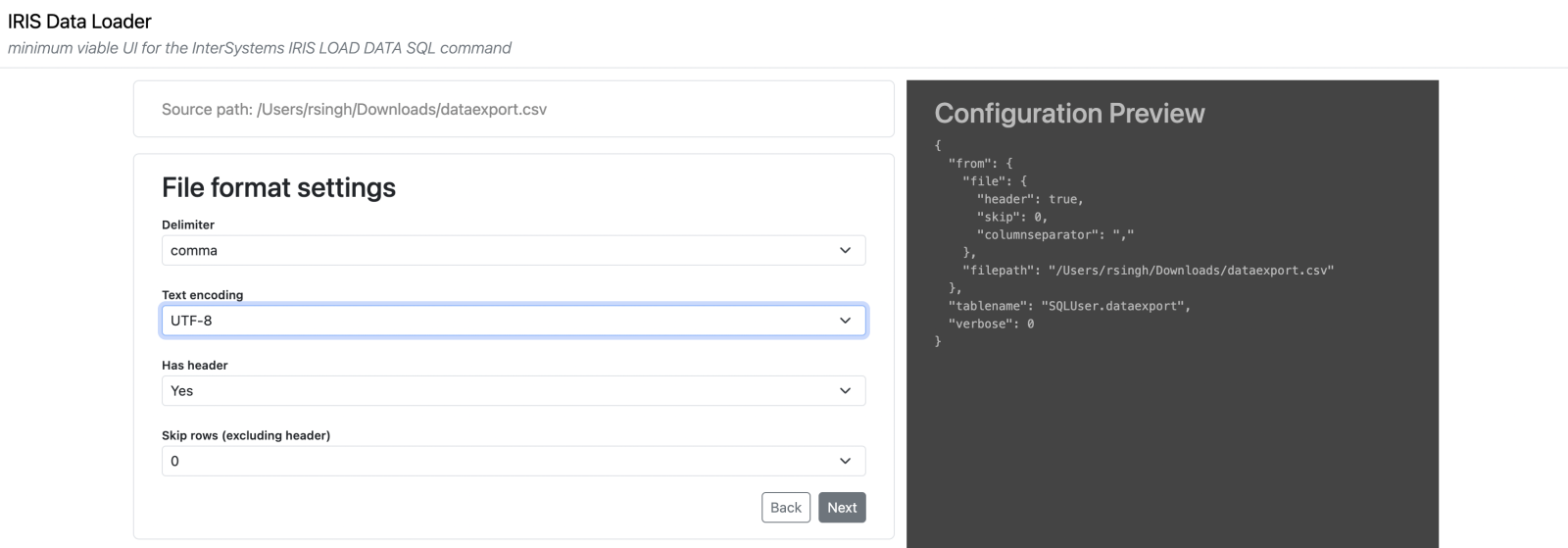 Step 5: Define a destination table name, with the schema name as well
Step 5: Define a destination table name, with the schema name as well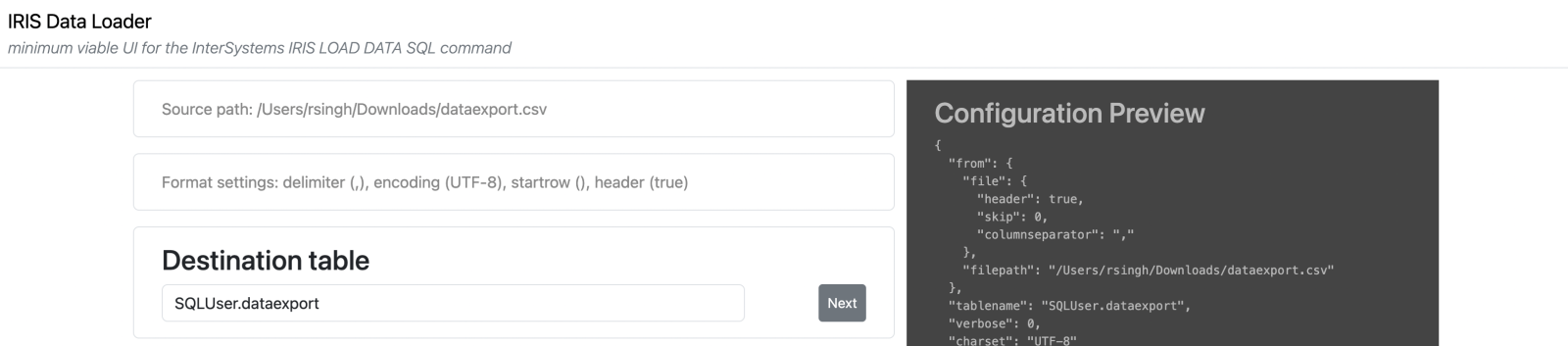
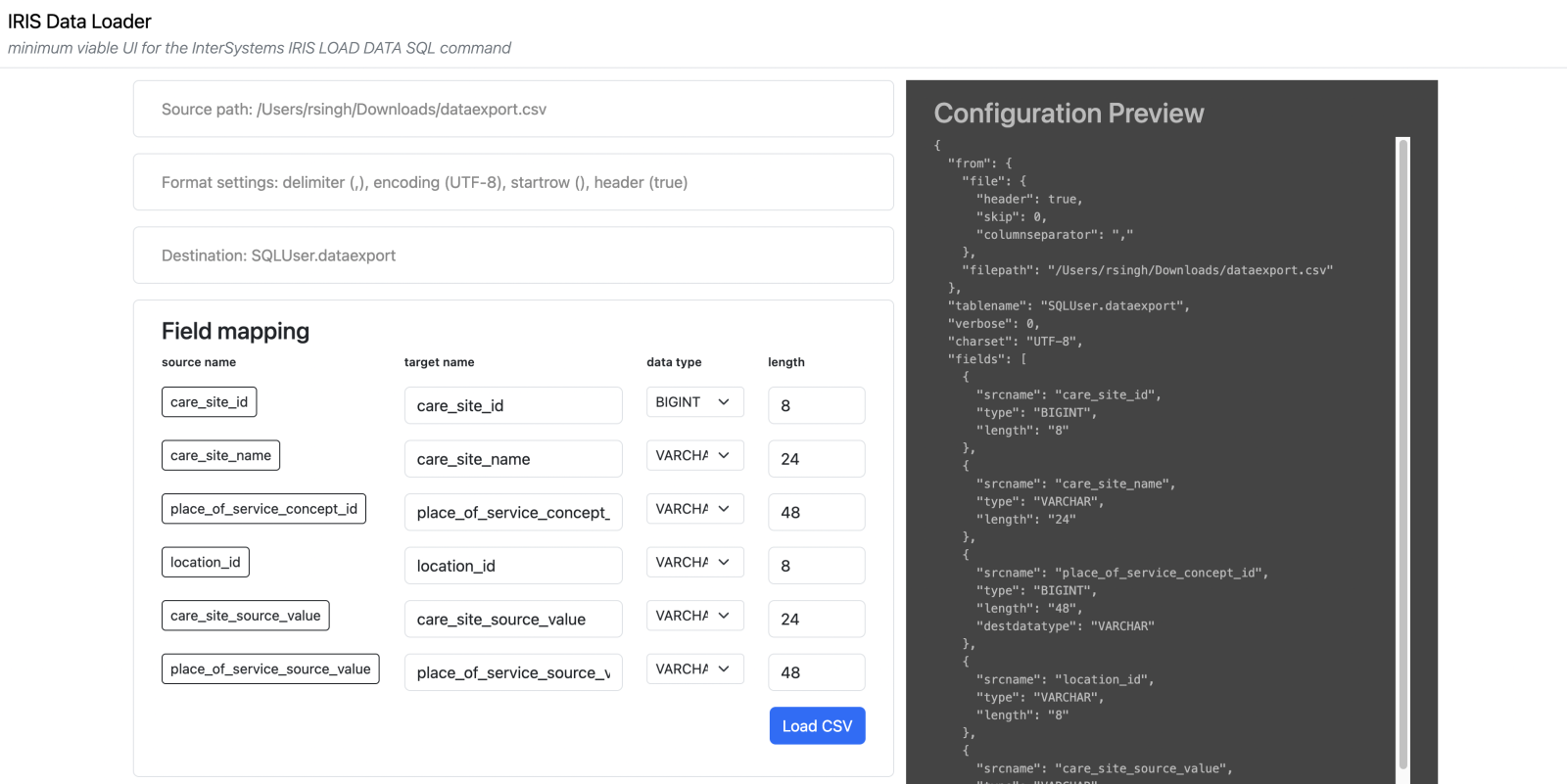
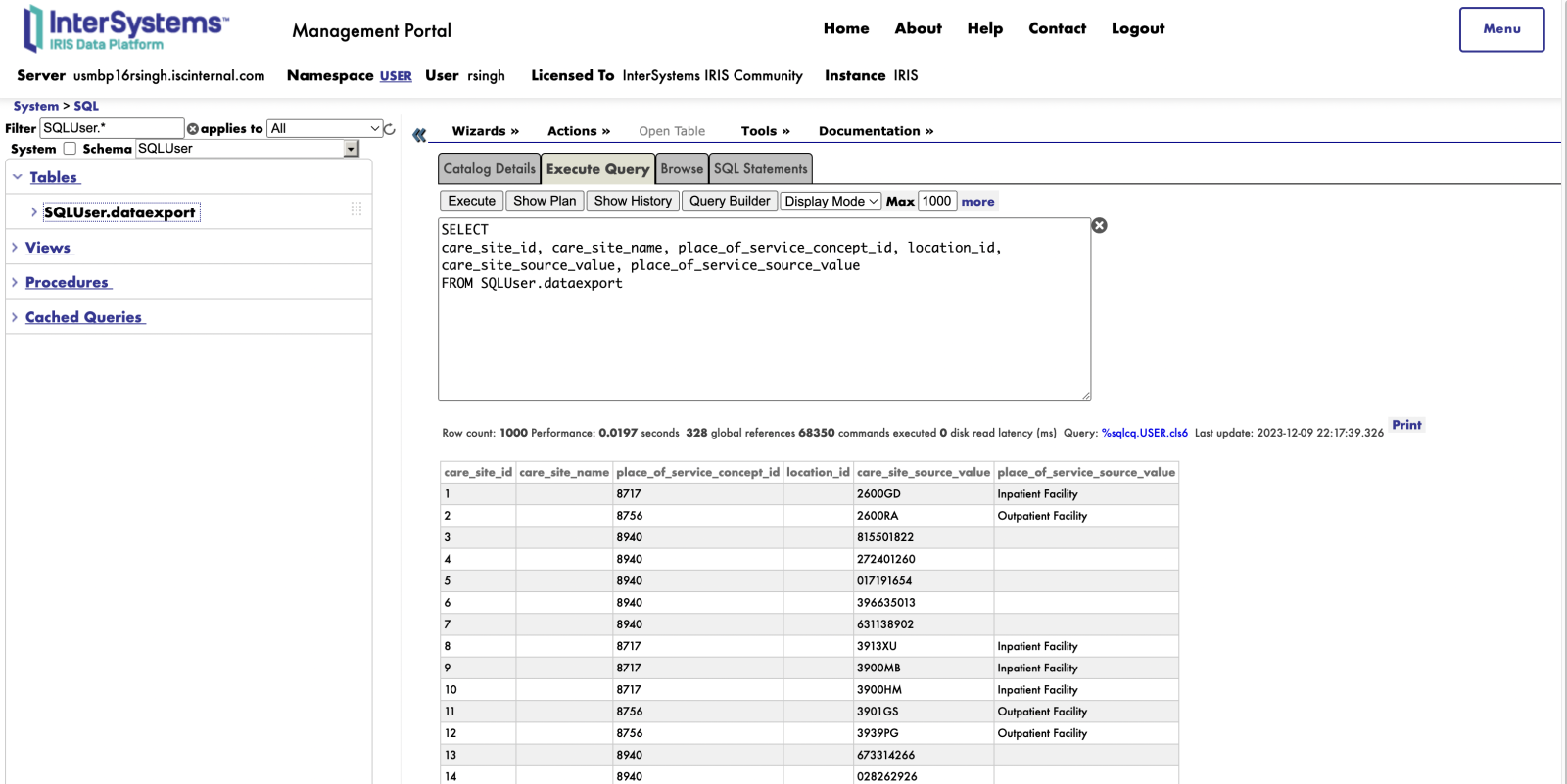
 (*)
(*)